 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCB-Conformer: Contextual biasing Conformer for biased word recognition
Apr 25, 2023
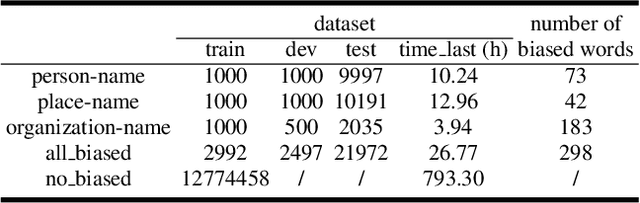
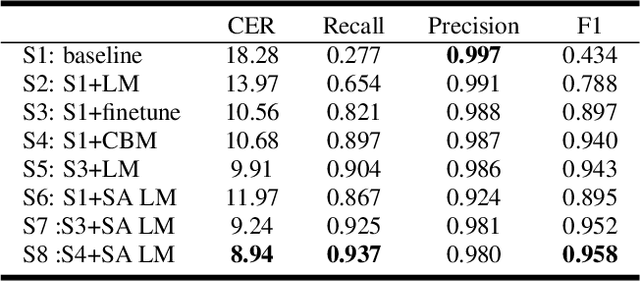
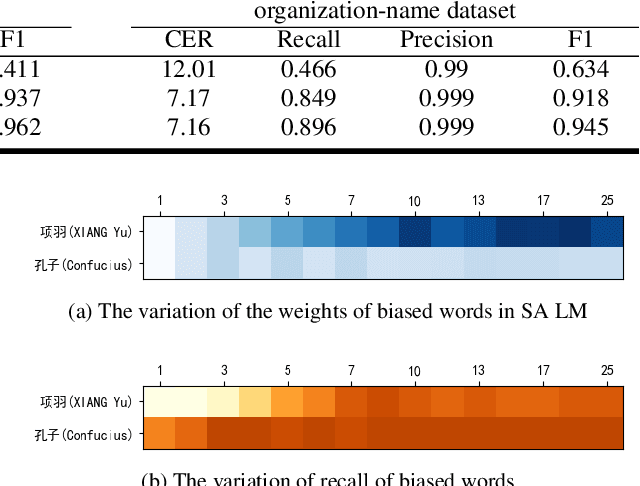
Due to the mismatch between the source and target domains, how to better utilize the biased word information to improve the performance of the automatic speech recognition model in the target domain becomes a hot research topic. Previous approaches either decode with a fixed external language model or introduce a sizeable biasing module, which leads to poor adaptability and slow inference. In this work, we propose CB-Conformer to improve biased word recognition by introducing the Contextual Biasing Module and the Self-Adaptive Language Model to vanilla Conformer. The Contextual Biasing Module combines audio fragments and contextual information, with only 0.2% model parameters of the original Conformer. The Self-Adaptive Language Model modifies the internal weights of biased words based on their recall and precision, resulting in a greater focus on biased words and more successful integration with the automatic speech recognition model than the standard fixed language model. In addition, we construct and release an open-source Mandarin biased-word dataset based on WenetSpeech. Experiments indicate that our proposed method brings a 15.34% character error rate reduction, a 14.13% biased word recall increase, and a 6.80% biased word F1-score increase compared with the base Conformer.
Multi-head Monotonic Chunkwise Attention For Online Speech Recognition
May 01, 2020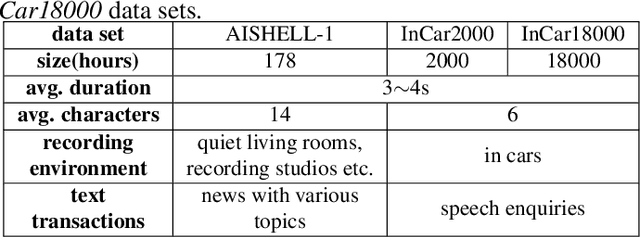
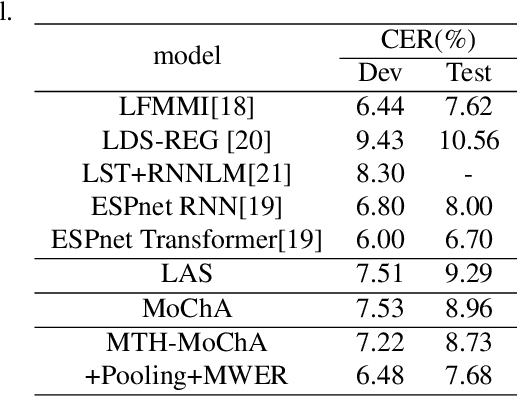
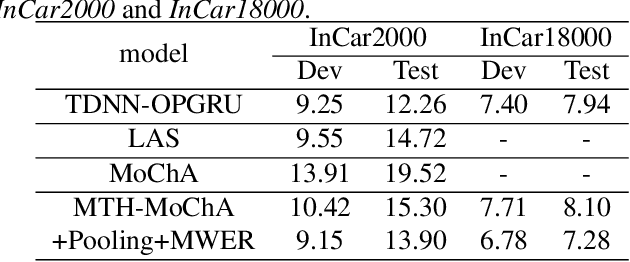
The attention mechanism of the Listen, Attend and Spell (LAS) model requires the whole input sequence to calculate the attention context and thus is not suitable for online speech recognition. To deal with this problem, we propose multi-head monotonic chunk-wise attention (MTH-MoChA), an improved version of MoChA. MTH-MoChA splits the input sequence into small chunks and computes multi-head attentions over the chunks. We also explore useful training strategies such as LSTM pooling, minimum world error rate training and SpecAugment to further improve the performance of MTH-MoChA. Experiments on AISHELL-1 data show that the proposed model, along with the training strategies, improve the character error rate (CER) of MoChA from 8.96% to 7.68% on test set. On another 18000 hours in-car speech data set, MTH-MoChA obtains 7.28% CER, which is significantly better than a state-of-the-art hybrid system.