 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinMMDocR: Benchmarking Financial Multimodal Reasoning with Scenario Awareness, Document Understanding, and Multi-Step Computation
Dec 31, 2025We introduce FinMMDocR, a novel bilingual multimodal benchmark for evaluating multimodal large language models (MLLMs) on real-world financial numerical reasoning. Compared to existing benchmarks, our work delivers three major advancements. (1) Scenario Awareness: 57.9% of 1,200 expert-annotated problems incorporate 12 types of implicit financial scenarios (e.g., Portfolio Management), challenging models to perform expert-level reasoning based on assumptions; (2) Document Understanding: 837 Chinese/English documents spanning 9 types (e.g., Company Research) average 50.8 pages with rich visual elements, significantly surpassing existing benchmarks in both breadth and depth of financial documents; (3) Multi-Step Computation: Problems demand 11-step reasoning on average (5.3 extraction + 5.7 calculation steps), with 65.0% requiring cross-page evidence (2.4 pages average). The best-performing MLLM achieves only 58.0% accuracy, and different retrieval-augmented generation (RAG) methods show significant performance variations on this task. We expect FinMMDocR to drive improvements in MLLMs and reasoning-enhanced methods on complex multimodal reasoning tasks in real-world scenarios.
FinMMR: Make Financial Numerical Reasoning More Multimodal, Comprehensive, and Challenging
Aug 06, 2025We present FinMMR, a novel bilingual multimodal benchmark tailored to evaluate the reasoning capabilities of multimodal large language models (MLLMs) in financial numerical reasoning tasks. Compared to existing benchmarks, our work introduces three significant advancements. (1) Multimodality: We meticulously transform existing financial reasoning benchmarks, and construct novel questions from the latest Chinese financial research reports. FinMMR comprises 4.3K questions and 8.7K images spanning 14 categories, including tables, bar charts, and ownership structure charts. (2) Comprehensiveness: FinMMR encompasses 14 financial subdomains, including corporate finance, banking, and industry analysis, significantly exceeding existing benchmarks in financial domain knowledge breadth. (3) Challenge: Models are required to perform multi-step precise numerical reasoning by integrating financial knowledge with the understanding of complex financial images and text. The best-performing MLLM achieves only 53.0% accuracy on Hard problems. We believe that FinMMR will drive advancements in enhancing the reasoning capabilities of MLLMs in real-world scenarios.
FinanceReasoning: Benchmarking Financial Numerical Reasoning More Credible, Comprehensive and Challenging
Jun 06, 2025We introduce FinanceReasoning, a novel benchmark designed to evaluate the reasoning capabilities of large reasoning models (LRMs) in financial numerical reasoning problems. Compared to existing benchmarks, our work provides three key advancements. (1) Credibility: We update 15.6% of the questions from four public datasets, annotating 908 new questions with detailed Python solutions and rigorously refining evaluation standards. This enables an accurate assessment of the reasoning improvements of LRMs. (2) Comprehensiveness: FinanceReasoning covers 67.8% of financial concepts and formulas, significantly surpassing existing datasets. Additionally, we construct 3,133 Python-formatted functions, which enhances LRMs' financial reasoning capabilities through refined knowledge (e.g., 83.2% $\rightarrow$ 91.6% for GPT-4o). (3) Challenge: Models are required to apply multiple financial formulas for precise numerical reasoning on 238 Hard problems. The best-performing model (i.e., OpenAI o1 with PoT) achieves 89.1% accuracy, yet LRMs still face challenges in numerical precision. We demonstrate that combining Reasoner and Programmer models can effectively enhance LRMs' performance (e.g., 83.2% $\rightarrow$ 87.8% for DeepSeek-R1). Our work paves the way for future research on evaluating and improving LRMs in domain-specific complex reasoning tasks.
SoCov: Semi-Orthogonal Parametric Pooling of Covariance Matrix for Speaker Recognition
Apr 23, 2025In conventional deep speaker embedding frameworks, the pooling layer aggregates all frame-level features over time and computes their mean and standard deviation statistics as inputs to subsequent segment-level layers. Such statistics pooling strategy produces fixed-length representations from variable-length speech segments. However, this method treats different frame-level features equally and discards covariance information. In this paper, we propose the Semi-orthogonal parameter pooling of Covariance matrix (SoCov) method. The SoCov pooling computes the covariance matrix from the self-attentive frame-level features and compresses it into a vector using the semi-orthogonal parametric vectorization, which is then concatenated with the weighted standard deviation vector to form inputs to the segment-level layers. Deep embedding based on SoCov is called ``sc-vector''. The proposed sc-vector is compared to several different baselines on the SRE21 development and evaluation sets. The sc-vector system significantly outperforms the conventional x-vector system, with a relative reduction in EER of 15.5% on SRE21Eval. When using self-attentive deep feature, SoCov helps to reduce EER on SRE21Eval by about 30.9% relatively to the conventional ``mean + standard deviation'' statistics.
The CORAL++ Algorithm for Unsupervised Domain Adaptation of Speaker Recogntion
Feb 02, 2022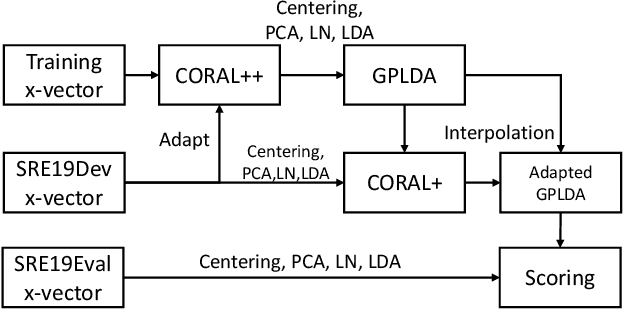


State-of-the-art speaker recognition systems are trained with a large amount of human-labeled training data set. Such a training set is usually composed of various data sources to enhance the modeling capability of models. However, in practical deployment, unseen condition is almost inevitable. Domain mismatch is a common problem in real-life applications due to the statistical difference between the training and testing data sets. To alleviate the degradation caused by domain mismatch, we propose a new feature-based unsupervised domain adaptation algorithm. The algorithm we propose is a further optimization based on the well-known CORrelation ALignment (CORAL), so we call it CORAL++. On the NIST 2019 Speaker Recognition Evaluation (SRE19), we use SRE18 CTS set as the development set to verify the effectiveness of CORAL++. With the typical x-vector/PLDA setup, the CORAL++ outperforms the CORAL by 9.40% relatively on EER.