 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Multidimensional Knowledge Profiling of Scientific Literature
Jan 21, 2026The rapid expansion of research across machine learning, vision, and language has produced a volume of publications that is increasingly difficult to synthesize. Traditional bibliometric tools rely mainly on metadata and offer limited visibility into the semantic content of papers, making it hard to track how research themes evolve over time or how different areas influence one another. To obtain a clearer picture of recent developments, we compile a unified corpus of more than 100,000 papers from 22 major conferences between 2020 and 2025 and construct a multidimensional profiling pipeline to organize and analyze their textual content. By combining topic clustering, LLM-assisted parsing, and structured retrieval, we derive a comprehensive representation of research activity that supports the study of topic lifecycles, methodological transitions, dataset and model usage patterns, and institutional research directions. Our analysis highlights several notable shifts, including the growth of safety, multimodal reasoning, and agent-oriented studies, as well as the gradual stabilization of areas such as neural machine translation and graph-based methods. These findings provide an evidence-based view of how AI research is evolving and offer a resource for understanding broader trends and identifying emerging directions. Code and dataset: https://github.com/xzc-zju/Profiling_Scientific_Literature
OpenVE-3M: A Large-Scale High-Quality Dataset for Instruction-Guided Video Editing
Dec 16, 2025The quality and diversity of instruction-based image editing datasets are continuously increasing, yet large-scale, high-quality datasets for instruction-based video editing remain scarce. To address this gap, we introduce OpenVE-3M, an open-source, large-scale, and high-quality dataset for instruction-based video editing. It comprises two primary categories: spatially-aligned edits (Global Style, Background Change, Local Change, Local Remove, Local Add, and Subtitles Edit) and non-spatially-aligned edits (Camera Multi-Shot Edit and Creative Edit). All edit types are generated via a meticulously designed data pipeline with rigorous quality filtering. OpenVE-3M surpasses existing open-source datasets in terms of scale, diversity of edit types, instruction length, and overall quality. Furthermore, to address the lack of a unified benchmark in the field, we construct OpenVE-Bench, containing 431 video-edit pairs that cover a diverse range of editing tasks with three key metrics highly aligned with human judgment. We present OpenVE-Edit, a 5B model trained on our dataset that demonstrates remarkable efficiency and effectiveness by setting a new state-of-the-art on OpenVE-Bench, outperforming all prior open-source models including a 14B baseline. Project page is at https://lewandofskee.github.io/projects/OpenVE.
EfficientIML: Efficient High-Resolution Image Manipulation Localization
Sep 10, 2025With imaging devices delivering ever-higher resolutions and the emerging diffusion-based forgery methods, current detectors trained only on traditional datasets (with splicing, copy-moving and object removal forgeries) lack exposure to this new manipulation type. To address this, we propose a novel high-resolution SIF dataset of 1200+ diffusion-generated manipulations with semantically extracted masks. However, this also imposes a challenge on existing methods, as they face significant computational resource constraints due to their prohibitive computational complexities. Therefore, we propose a novel EfficientIML model with a lightweight, three-stage EfficientRWKV backbone. EfficientRWKV's hybrid state-space and attention network captures global context and local details in parallel, while a multi-scale supervision strategy enforces consistency across hierarchical predictions. Extensive evaluations on our dataset and standard benchmarks demonstrate that our approach outperforms ViT-based and other SOTA lightweight baselines in localization performance, FLOPs and inference speed, underscoring its suitability for real-time forensic applications.
FinMMR: Make Financial Numerical Reasoning More Multimodal, Comprehensive, and Challenging
Aug 06, 2025We present FinMMR, a novel bilingual multimodal benchmark tailored to evaluate the reasoning capabilities of multimodal large language models (MLLMs) in financial numerical reasoning tasks. Compared to existing benchmarks, our work introduces three significant advancements. (1) Multimodality: We meticulously transform existing financial reasoning benchmarks, and construct novel questions from the latest Chinese financial research reports. FinMMR comprises 4.3K questions and 8.7K images spanning 14 categories, including tables, bar charts, and ownership structure charts. (2) Comprehensiveness: FinMMR encompasses 14 financial subdomains, including corporate finance, banking, and industry analysis, significantly exceeding existing benchmarks in financial domain knowledge breadth. (3) Challenge: Models are required to perform multi-step precise numerical reasoning by integrating financial knowledge with the understanding of complex financial images and text. The best-performing MLLM achieves only 53.0% accuracy on Hard problems. We believe that FinMMR will drive advancements in enhancing the reasoning capabilities of MLLMs in real-world scenarios.
UltraVideo: High-Quality UHD Video Dataset with Comprehensive Captions
Jun 16, 2025The quality of the video dataset (image quality, resolution, and fine-grained caption) greatly influences the performance of the video generation model. The growing demand for video applications sets higher requirements for high-quality video generation models. For example, the generation of movie-level Ultra-High Definition (UHD) videos and the creation of 4K short video content. However, the existing public datasets cannot support related research and applications. In this paper, we first propose a high-quality open-sourced UHD-4K (22.4\% of which are 8K) text-to-video dataset named UltraVideo, which contains a wide range of topics (more than 100 kinds), and each video has 9 structured captions with one summarized caption (average of 824 words). Specifically, we carefully design a highly automated curation process with four stages to obtain the final high-quality dataset: \textit{i)} collection of diverse and high-quality video clips. \textit{ii)} statistical data filtering. \textit{iii)} model-based data purification. \textit{iv)} generation of comprehensive, structured captions. In addition, we expand Wan to UltraWan-1K/-4K, which can natively generate high-quality 1K/4K videos with more consistent text controllability, demonstrating the effectiveness of our data curation.We believe that this work can make a significant contribution to future research on UHD video generation. UltraVideo dataset and UltraWan models are available at https://xzc-zju.github.io/projects/UltraVideo.
FinanceReasoning: Benchmarking Financial Numerical Reasoning More Credible, Comprehensive and Challenging
Jun 06, 2025We introduce FinanceReasoning, a novel benchmark designed to evaluate the reasoning capabilities of large reasoning models (LRMs) in financial numerical reasoning problems. Compared to existing benchmarks, our work provides three key advancements. (1) Credibility: We update 15.6% of the questions from four public datasets, annotating 908 new questions with detailed Python solutions and rigorously refining evaluation standards. This enables an accurate assessment of the reasoning improvements of LRMs. (2) Comprehensiveness: FinanceReasoning covers 67.8% of financial concepts and formulas, significantly surpassing existing datasets. Additionally, we construct 3,133 Python-formatted functions, which enhances LRMs' financial reasoning capabilities through refined knowledge (e.g., 83.2% $\rightarrow$ 91.6% for GPT-4o). (3) Challenge: Models are required to apply multiple financial formulas for precise numerical reasoning on 238 Hard problems. The best-performing model (i.e., OpenAI o1 with PoT) achieves 89.1% accuracy, yet LRMs still face challenges in numerical precision. We demonstrate that combining Reasoner and Programmer models can effectively enhance LRMs' performance (e.g., 83.2% $\rightarrow$ 87.8% for DeepSeek-R1). Our work paves the way for future research on evaluating and improving LRMs in domain-specific complex reasoning tasks.
RayFronts: Open-Set Semantic Ray Frontiers for Online Scene Understanding and Exploration
Apr 09, 2025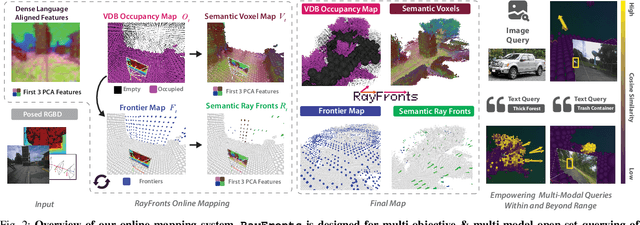
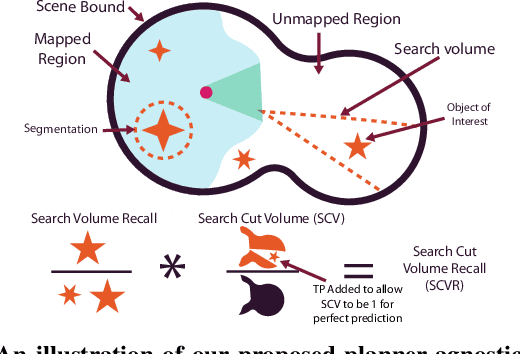
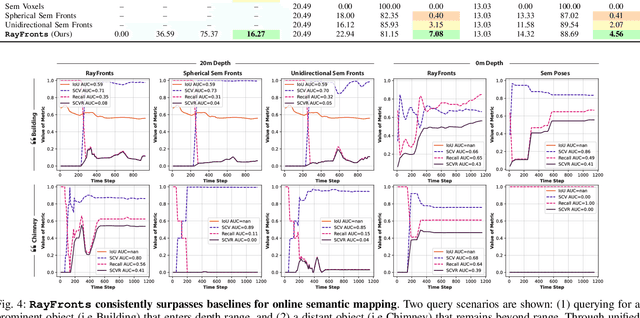
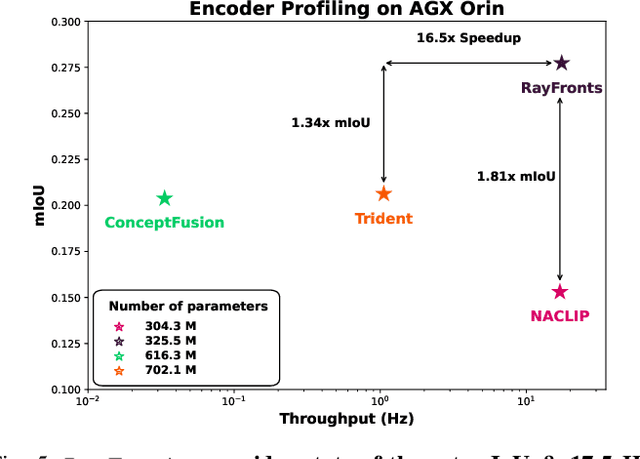
Open-set semantic mapping is crucial for open-world robots. Current mapping approaches either are limited by the depth range or only map beyond-range entities in constrained settings, where overall they fail to combine within-range and beyond-range observations. Furthermore, these methods make a trade-off between fine-grained semantics and efficiency. We introduce RayFronts, a unified representation that enables both dense and beyond-range efficient semantic mapping. RayFronts encodes task-agnostic open-set semantics to both in-range voxels and beyond-range rays encoded at map boundaries, empowering the robot to reduce search volumes significantly and make informed decisions both within & beyond sensory range, while running at 8.84 Hz on an Orin AGX. Benchmarking the within-range semantics shows that RayFronts's fine-grained image encoding provides 1.34x zero-shot 3D semantic segmentation performance while improving throughput by 16.5x. Traditionally, online mapping performance is entangled with other system components, complicating evaluation. We propose a planner-agnostic evaluation framework that captures the utility for online beyond-range search and exploration, and show RayFronts reduces search volume 2.2x more efficiently than the closest online baselines.
EMOv2: Pushing 5M Vision Model Frontier
Dec 09, 2024



This work focuses on developing parameter-efficient and lightweight models for dense predictions while trading off parameters, FLOPs, and performance. Our goal is to set up the new frontier of the 5M magnitude lightweight model on various downstream tasks. Inverted Residual Block (IRB) serves as the infrastructure for lightweight CNNs, but no counterparts have been recognized by attention-based design. Our work rethinks the lightweight infrastructure of efficient IRB and practical components in Transformer from a unified perspective, extending CNN-based IRB to attention-based models and abstracting a one-residual Meta Mobile Block (MMBlock) for lightweight model design. Following neat but effective design criterion, we deduce a modern Improved Inverted Residual Mobile Block (i2RMB) and improve a hierarchical Efficient MOdel (EMOv2) with no elaborate complex structures. Considering the imperceptible latency for mobile users when downloading models under 4G/5G bandwidth and ensuring model performance, we investigate the performance upper limit of lightweight models with a magnitude of 5M. Extensive experiments on various vision recognition, dense prediction, and image generation tasks demonstrate the superiority of our EMOv2 over state-of-the-art methods, e.g., EMOv2-1M/2M/5M achieve 72.3, 75.8, and 79.4 Top-1 that surpass equal-order CNN-/Attention-based models significantly. At the same time, EMOv2-5M equipped RetinaNet achieves 41.5 mAP for object detection tasks that surpasses the previous EMO-5M by +2.6. When employing the more robust training recipe, our EMOv2-5M eventually achieves 82.9 Top-1 accuracy, which elevates the performance of 5M magnitude models to a new level. Code is available at https://github.com/zhangzjn/EMOv2.
MobileMamba: Lightweight Multi-Receptive Visual Mamba Network
Nov 24, 2024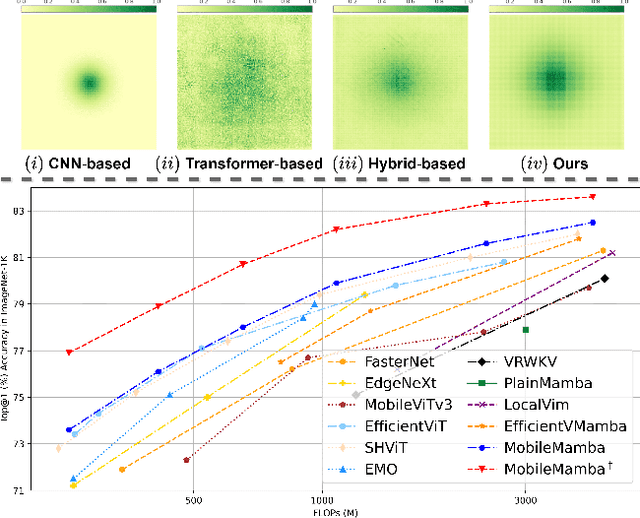
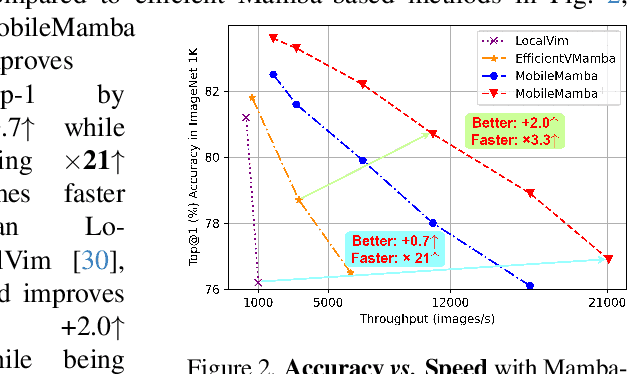

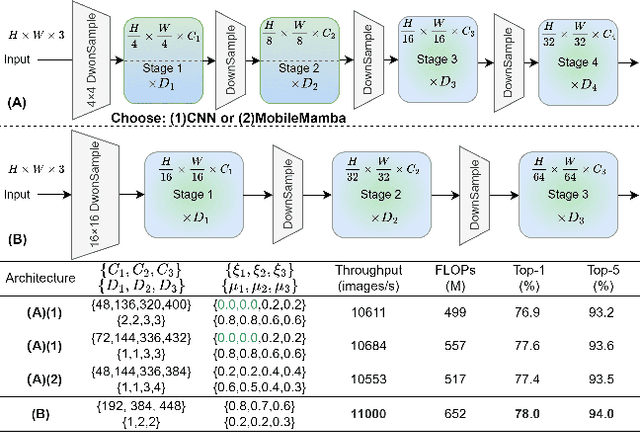
Previous research on lightweight models has primarily focused on CNNs and Transformer-based designs. CNNs, with their local receptive fields, struggle to capture long-range dependencies, while Transformers, despite their global modeling capabilities, are limited by quadratic computational complexity in high-resolution scenarios. Recently, state-space models have gained popularity in the visual domain due to their linear computational complexity. Despite their low FLOPs, current lightweight Mamba-based models exhibit suboptimal throughput. In this work, we propose the MobileMamba framework, which balances efficiency and performance. We design a three-stage network to enhance inference speed significantly. At a fine-grained level, we introduce the Multi-Receptive Field Feature Interaction(MRFFI) module, comprising the Long-Range Wavelet Transform-Enhanced Mamba(WTE-Mamba), Efficient Multi-Kernel Depthwise Convolution(MK-DeConv), and Eliminate Redundant Identity components. This module integrates multi-receptive field information and enhances high-frequency detail extraction. Additionally, we employ training and testing strategies to further improve performance and efficiency. MobileMamba achieves up to 83.6% on Top-1, surpassing existing state-of-the-art methods which is maximum x21 faster than LocalVim on GPU. Extensive experiments on high-resolution downstream tasks demonstrate that MobileMamba surpasses current efficient models, achieving an optimal balance between speed and accuracy.
LLaVA-KD: A Framework of Distilling Multimodal Large Language Models
Oct 21, 2024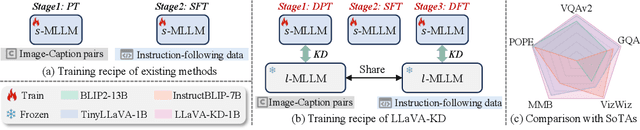
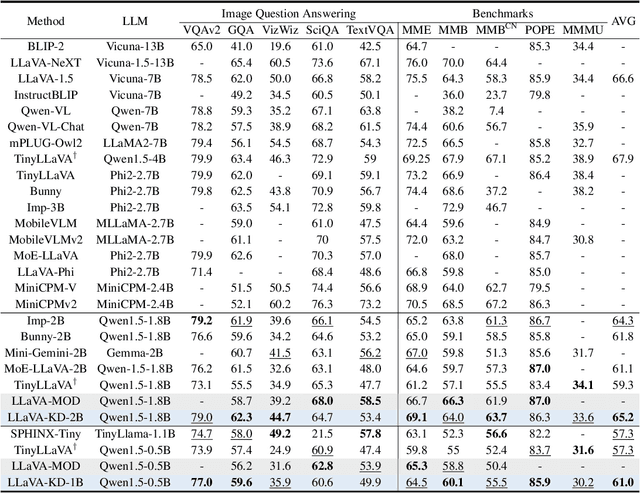
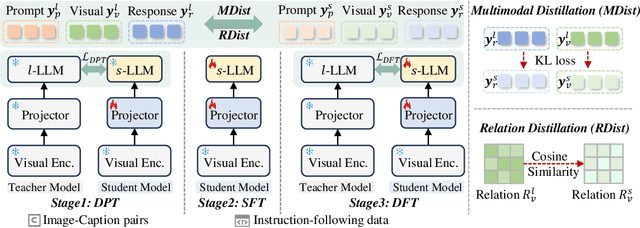
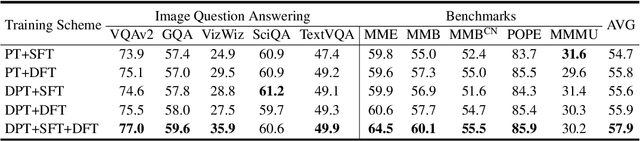
The success of Large Language Models (LLM) has led researchers to explore Multimodal Large Language Models (MLLM) for unified visual and linguistic understanding. However, the increasing model size and computational complexity of MLLM limit their use in resource-constrained environments. Small-scale MLLM (s-MLLM) aims to retain the capabilities of the large-scale model (l-MLLM) while reducing computational demands, but resulting in a significant decline in performance. To address the aforementioned issues, we propose a novel LLaVA-KD framework to transfer knowledge from l-MLLM to s-MLLM. Specifically, we introduce Multimodal Distillation (MDist) to minimize the divergence between the visual-textual output distributions of l-MLLM and s-MLLM, and Relation Distillation (RDist) to transfer l-MLLM's ability to model correlations between visual features. Additionally, we propose a three-stage training scheme to fully exploit the potential of s-MLLM: 1) Distilled Pre-Training to align visual-textual representations, 2) Supervised Fine-Tuning to equip the model with multimodal understanding, and 3) Distilled Fine-Tuning to further transfer l-MLLM capabilities. Our approach significantly improves performance without altering the small model's architecture. Extensive experiments and ablation studies validate the effectiveness of each proposed component. Code will be available at https://github.com/caiyuxuan1120/LLaVA-KD.