 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentralized Non-convex Stochastic Optimization with Heterogeneous Variance
Feb 12, 2026Decentralized optimization is critical for solving large-scale machine learning problems over distributed networks, where multiple nodes collaborate through local communication. In practice, the variances of stochastic gradient estimators often differ across nodes, yet their impact on algorithm design and complexity remains unclear. To address this issue, we propose D-NSS, a decentralized algorithm with node-specific sampling, and establish its sample complexity depending on the arithmetic mean of local standard deviations, achieving tighter bounds than existing methods that rely on the worst-case or quadratic mean. We further derive a matching sample complexity lower bound under heterogeneous variance, thereby proving the optimality of this dependence. Moreover, we extend the framework with a variance reduction technique and develop D-NSS-VR, which under the mean-squared smoothness assumption attains an improved sample complexity bound while preserving the arithmetic-mean dependence. Finally, numerical experiments validate the theoretical results and demonstrate the effectiveness of the proposed algorithms.
Bi-Anchor Interpolation Solver for Accelerating Generative Modeling
Jan 29, 2026Flow Matching (FM) models have emerged as a leading paradigm for high-fidelity synthesis. However, their reliance on iterative Ordinary Differential Equation (ODE) solving creates a significant latency bottleneck. Existing solutions face a dichotomy: training-free solvers suffer from significant performance degradation at low Neural Function Evaluations (NFEs), while training-based one- or few-steps generation methods incur prohibitive training costs and lack plug-and-play versatility. To bridge this gap, we propose the Bi-Anchor Interpolation Solver (BA-solver). BA-solver retains the versatility of standard training-free solvers while achieving significant acceleration by introducing a lightweight SideNet (1-2% backbone size) alongside the frozen backbone. Specifically, our method is founded on two synergistic components: \textbf{1) Bidirectional Temporal Perception}, where the SideNet learns to approximate both future and historical velocities without retraining the heavy backbone; and 2) Bi-Anchor Velocity Integration, which utilizes the SideNet with two anchor velocities to efficiently approximate intermediate velocities for batched high-order integration. By utilizing the backbone to establish high-precision ``anchors'' and the SideNet to densify the trajectory, BA-solver enables large interval sizes with minimized error. Empirical results on ImageNet-256^2 demonstrate that BA-solver achieves generation quality comparable to 100+ NFEs Euler solver in just 10 NFEs and maintains high fidelity in as few as 5 NFEs, incurring negligible training costs. Furthermore, BA-solver ensures seamless integration with existing generative pipelines, facilitating downstream tasks such as image editing.
Stability and Generalization of Nonconvex Optimization with Heavy-Tailed Noise
Jan 27, 2026The empirical evidence indicates that stochastic optimization with heavy-tailed gradient noise is more appropriate to characterize the training of machine learning models than that with standard bounded gradient variance noise. Most existing works on this phenomenon focus on the convergence of optimization errors, while the analysis for generalization bounds under the heavy-tailed gradient noise remains limited. In this paper, we develop a general framework for establishing generalization bounds under heavy-tailed noise. Specifically, we introduce a truncation argument to achieve the generalization error bound based on the algorithmic stability under the assumption of bounded $p$th centered moment with $p\in(1,2]$. Building on this framework, we further provide the stability and generalization analysis for several popular stochastic algorithms under heavy-tailed noise, including clipped and normalized stochastic gradient descent, as well as their mini-batch and momentum variants.
Policy Mirror Descent with Temporal Difference Learning: Sample Complexity under Online Markov Data
Dec 30, 2025This paper studies the policy mirror descent (PMD) method, which is a general policy optimization framework in reinforcement learning and can cover a wide range of policy gradient methods by specifying difference mirror maps. Existing sample complexity analysis for policy mirror descent either focuses on the generative sampling model, or the Markovian sampling model but with the action values being explicitly approximated to certain pre-specified accuracy. In contrast, we consider the sample complexity of policy mirror descent with temporal difference (TD) learning under the Markovian sampling model. Two algorithms called Expected TD-PMD and Approximate TD-PMD have been presented, which are off-policy and mixed policy algorithms respectively. Under a small enough constant policy update step size, the $\tilde{O}(\varepsilon^{-2})$ (a logarithm factor about $\varepsilon$ is hidden in $\tilde{O}(\cdot)$) sample complexity can be established for them to achieve average-time $\varepsilon$-optimality. The sample complexity is further improved to $O(\varepsilon^{-2})$ (without the hidden logarithm factor) to achieve the last-iterate $\varepsilon$-optimality based on adaptive policy update step sizes.
MobileMamba: Lightweight Multi-Receptive Visual Mamba Network
Nov 24, 2024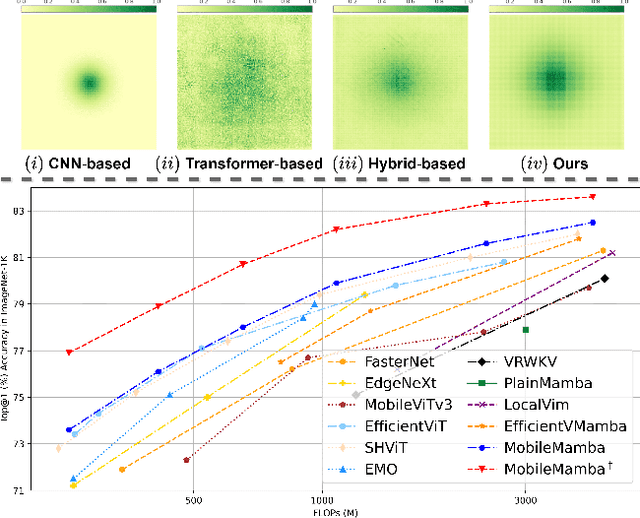
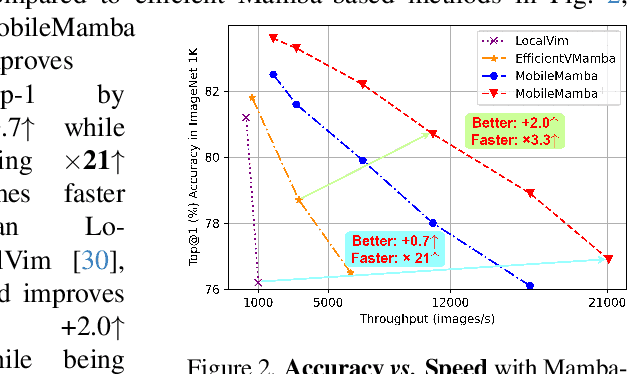

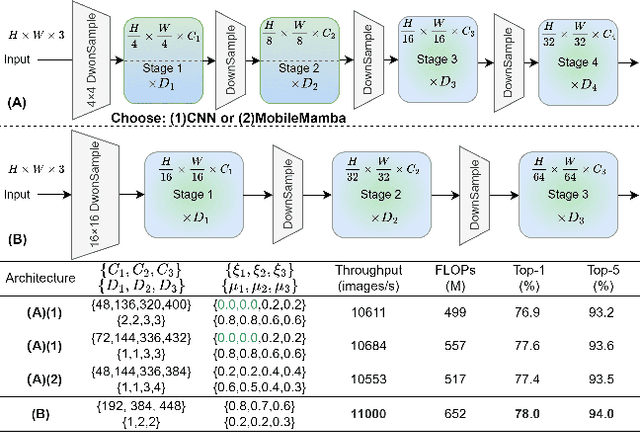
Previous research on lightweight models has primarily focused on CNNs and Transformer-based designs. CNNs, with their local receptive fields, struggle to capture long-range dependencies, while Transformers, despite their global modeling capabilities, are limited by quadratic computational complexity in high-resolution scenarios. Recently, state-space models have gained popularity in the visual domain due to their linear computational complexity. Despite their low FLOPs, current lightweight Mamba-based models exhibit suboptimal throughput. In this work, we propose the MobileMamba framework, which balances efficiency and performance. We design a three-stage network to enhance inference speed significantly. At a fine-grained level, we introduce the Multi-Receptive Field Feature Interaction(MRFFI) module, comprising the Long-Range Wavelet Transform-Enhanced Mamba(WTE-Mamba), Efficient Multi-Kernel Depthwise Convolution(MK-DeConv), and Eliminate Redundant Identity components. This module integrates multi-receptive field information and enhances high-frequency detail extraction. Additionally, we employ training and testing strategies to further improve performance and efficiency. MobileMamba achieves up to 83.6% on Top-1, surpassing existing state-of-the-art methods which is maximum x21 faster than LocalVim on GPU. Extensive experiments on high-resolution downstream tasks demonstrate that MobileMamba surpasses current efficient models, achieving an optimal balance between speed and accuracy.
IterIS: Iterative Inference-Solving Alignment for LoRA Merging
Nov 21, 2024



Low-rank adaptations (LoRA) are widely used to fine-tune large models across various domains for specific downstream tasks. While task-specific LoRAs are often available, concerns about data privacy and intellectual property can restrict access to training data, limiting the acquisition of a multi-task model through gradient-based training. In response, LoRA merging presents an effective solution by combining multiple LoRAs into a unified adapter while maintaining data privacy. Prior works on LoRA merging primarily frame it as an optimization problem, yet these approaches face several limitations, including the rough assumption about input features utilized in optimization, massive sample requirements, and the unbalanced optimization objective. These limitations can significantly degrade performance. To address these, we propose a novel optimization-based method, named IterIS: 1) We formulate LoRA merging as an advanced optimization problem to mitigate the rough assumption. Additionally, we employ an iterative inference-solving framework in our algorithm. It can progressively refine the optimization objective for improved performance. 2) We introduce an efficient regularization term to reduce the need for massive sample requirements (requiring only 1-5% of the unlabeled samples compared to prior methods). 3) We utilize adaptive weights in the optimization objective to mitigate potential unbalances in LoRA merging process. Our method demonstrates significant improvements over multiple baselines and state-of-the-art methods in composing tasks for text-to-image diffusion, vision-language models, and large language models. Furthermore, our layer-wise algorithm can achieve convergence with minimal steps, ensuring efficiency in both memory and computation.
Data Watermarking for Sequential Recommender Systems
Nov 20, 2024



In the era of large foundation models, data has become a crucial component for building high-performance AI systems. As the demand for high-quality and large-scale data continues to rise, data copyright protection is attracting increasing attention. In this work, we explore the problem of data watermarking for sequential recommender systems, where a watermark is embedded into the target dataset and can be detected in models trained on that dataset. We address two specific challenges: dataset watermarking, which protects the ownership of the entire dataset, and user watermarking, which safeguards the data of individual users. We systematically define these problems and present a method named DWRS to address them. Our approach involves randomly selecting unpopular items to create a watermark sequence, which is then inserted into normal users' interaction sequences. Extensive experiments on five representative sequential recommendation models and three benchmark datasets demonstrate the effectiveness of DWRS in protecting data copyright while preserving model utility.
Graph and Sequential Neural Networks in Session-based Recommendation: A Survey
Aug 27, 2024Recent years have witnessed the remarkable success of recommendation systems (RSs) in alleviating the information overload problem. As a new paradigm of RSs, session-based recommendation (SR) specializes in users' short-term preference capture and aims to provide a more dynamic and timely recommendation based on the ongoing interacted actions. In this survey, we will give a comprehensive overview of the recent works on SR. First, we clarify the definitions of various SR tasks and introduce the characteristics of session-based recommendation against other recommendation tasks. Then, we summarize the existing methods in two categories: sequential neural network based methods and graph neural network (GNN) based methods. The standard frameworks and technical are also introduced. Finally, we discuss the challenges of SR and new research directions in this area.
MambaAD: Exploring State Space Models for Multi-class Unsupervised Anomaly Detection
Apr 14, 2024



Recent advancements in anomaly detection have seen the efficacy of CNN- and transformer-based approaches. However, CNNs struggle with long-range dependencies, while transformers are burdened by quadratic computational complexity. Mamba-based models, with their superior long-range modeling and linear efficiency, have garnered substantial attention. This study pioneers the application of Mamba to multi-class unsupervised anomaly detection, presenting MambaAD, which consists of a pre-trained encoder and a Mamba decoder featuring (Locality-Enhanced State Space) LSS modules at multi-scales. The proposed LSS module, integrating parallel cascaded (Hybrid State Space) HSS blocks and multi-kernel convolutions operations, effectively captures both long-range and local information. The HSS block, utilizing (Hybrid Scanning) HS encoders, encodes feature maps into five scanning methods and eight directions, thereby strengthening global connections through the (State Space Model) SSM. The use of Hilbert scanning and eight directions significantly improves feature sequence modeling. Comprehensive experiments on six diverse anomaly detection datasets and seven metrics demonstrate state-of-the-art performance, substantiating the method's effectiveness.
Attention Is Not the Only Choice: Counterfactual Reasoning for Path-Based Explainable Recommendation
Jan 11, 2024Compared with only pursuing recommendation accuracy, the explainability of a recommendation model has drawn more attention in recent years. Many graph-based recommendations resort to informative paths with the attention mechanism for the explanation. Unfortunately, these attention weights are intentionally designed for model accuracy but not explainability. Recently, some researchers have started to question attention-based explainability because the attention weights are unstable for different reproductions, and they may not always align with human intuition. Inspired by the counterfactual reasoning from causality learning theory, we propose a novel explainable framework targeting path-based recommendations, wherein the explainable weights of paths are learned to replace attention weights. Specifically, we design two counterfactual reasoning algorithms from both path representation and path topological structure perspectives. Moreover, unlike traditional case studies, we also propose a package of explainability evaluation solutions with both qualitative and quantitative methods. We conduct extensive experiments on three real-world datasets, the results of which further demonstrate the effectiveness and reliability of our method.