 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Feature Adaptation for 3D Industrial Anomaly Detection
Jan 17, 2024



Industrial anomaly detection is generally addressed as an unsupervised task that aims at locating defects with only normal training samples. Recently, numerous 2D anomaly detection methods have been proposed and have achieved promising results, however, using only the 2D RGB data as input is not sufficient to identify imperceptible geometric surface anomalies. Hence, in this work, we focus on multi-modal anomaly detection. Specifically, we investigate early multi-modal approaches that attempted to utilize models pre-trained on large-scale visual datasets, i.e., ImageNet, to construct feature databases. And we empirically find that directly using these pre-trained models is not optimal, it can either fail to detect subtle defects or mistake abnormal features as normal ones. This may be attributed to the domain gap between target industrial data and source data.Towards this problem, we propose a Local-to-global Self-supervised Feature Adaptation (LSFA) method to finetune the adaptors and learn task-oriented representation toward anomaly detection.Both intra-modal adaptation and cross-modal alignment are optimized from a local-to-global perspective in LSFA to ensure the representation quality and consistency in the inference stage.Extensive experiments demonstrate that our method not only brings a significant performance boost to feature embedding based approaches, but also outperforms previous State-of-The-Art (SoTA) methods prominently on both MVTec-3D AD and Eyecandies datasets, e.g., LSFA achieves 97.1% I-AUROC on MVTec-3D, surpass previous SoTA by +3.4%.
Exploring Plain ViT Reconstruction for Multi-class Unsupervised Anomaly Detection
Dec 12, 2023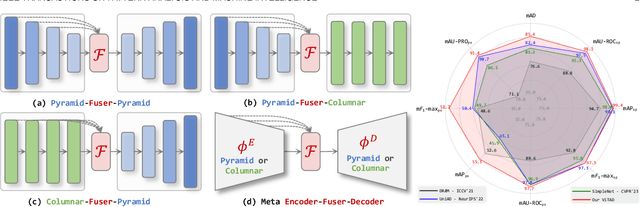
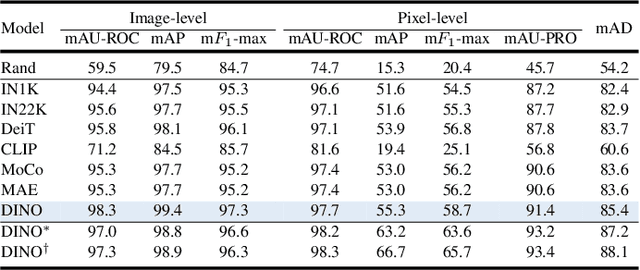
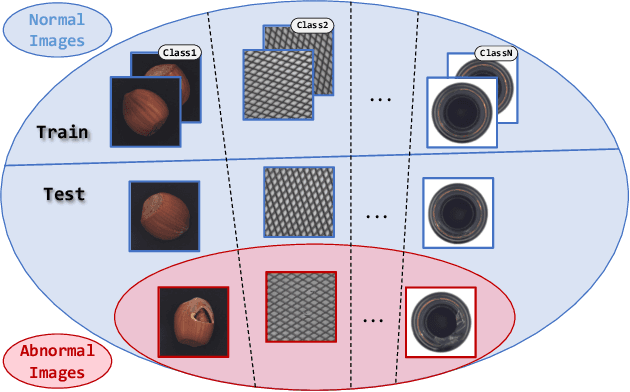
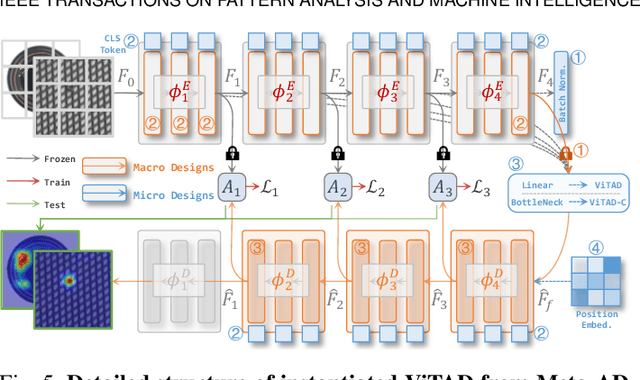
This work studies the recently proposed challenging and practical Multi-class Unsupervised Anomaly Detection (MUAD) task, which only requires normal images for training while simultaneously testing both normal/anomaly images for multiple classes. Existing reconstruction-based methods typically adopt pyramid networks as encoders/decoders to obtain multi-resolution features, accompanied by elaborate sub-modules with heavier handcraft engineering designs for more precise localization. In contrast, a plain Vision Transformer (ViT) with simple architecture has been shown effective in multiple domains, which is simpler, more effective, and elegant. Following this spirit, this paper explores plain ViT architecture for MUAD. Specifically, we abstract a Meta-AD concept by inducing current reconstruction-based methods. Then, we instantiate a novel and elegant plain ViT-based symmetric ViTAD structure, effectively designed step by step from three macro and four micro perspectives. In addition, this paper reveals several interesting findings for further exploration. Finally, we propose a comprehensive and fair evaluation benchmark on eight metrics for the MUAD task. Based on a naive training recipe, ViTAD achieves state-of-the-art (SoTA) results and efficiency on the MVTec AD and VisA datasets without bells and whistles, obtaining 85.4 mAD that surpasses SoTA UniAD by +3.0, and only requiring 1.1 hours and 2.3G GPU memory to complete model training by a single V100 GPU. Source code, models, and more results are available at https://zhangzjn.github.io/projects/ViTAD.
DiAD: A Diffusion-based Framework for Multi-class Anomaly Detection
Dec 11, 2023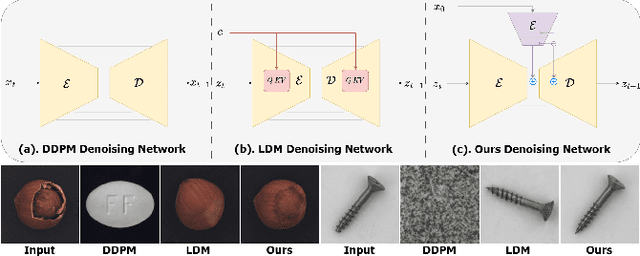
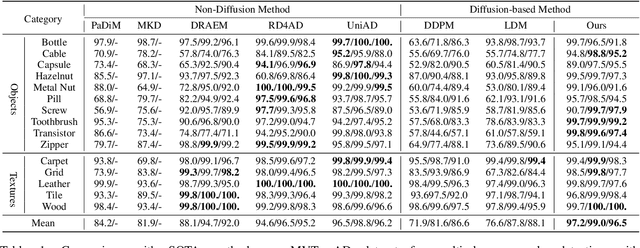
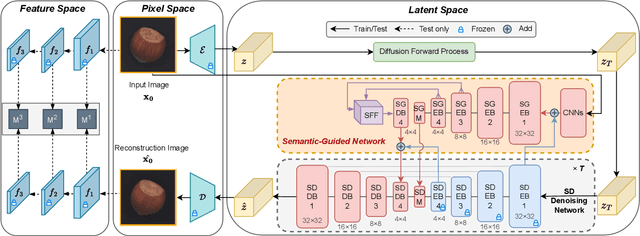
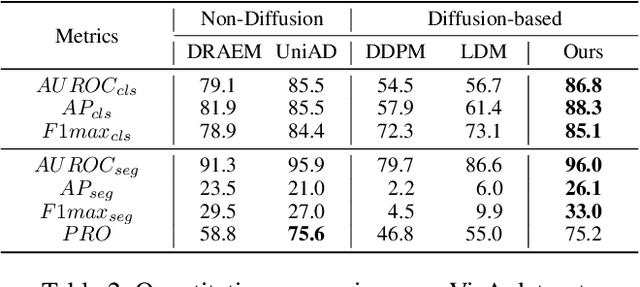
Reconstruction-based approaches have achieved remarkable outcomes in anomaly detection. The exceptional image reconstruction capabilities of recently popular diffusion models have sparked research efforts to utilize them for enhanced reconstruction of anomalous images. Nonetheless, these methods might face challenges related to the preservation of image categories and pixel-wise structural integrity in the more practical multi-class setting. To solve the above problems, we propose a Difusion-based Anomaly Detection (DiAD) framework for multi-class anomaly detection, which consists of a pixel-space autoencoder, a latent-space Semantic-Guided (SG) network with a connection to the stable diffusion's denoising network, and a feature-space pre-trained feature extractor. Firstly, The SG network is proposed for reconstructing anomalous regions while preserving the original image's semantic information. Secondly, we introduce Spatial-aware Feature Fusion (SFF) block to maximize reconstruction accuracy when dealing with extensively reconstructed areas. Thirdly, the input and reconstructed images are processed by a pre-trained feature extractor to generate anomaly maps based on features extracted at different scales. Experiments on MVTec-AD and VisA datasets demonstrate the effectiveness of our approach which surpasses the state-of-the-art methods, e.g., achieving 96.8/52.6 and 97.2/99.0 (AUROC/AP) for localization and detection respectively on multi-class MVTec-AD dataset. Code will be available at https://lewandofskee.github.io/projects/diad.
Exploring Grounding Potential of VQA-oriented GPT-4V for Zero-shot Anomaly Detection
Nov 05, 2023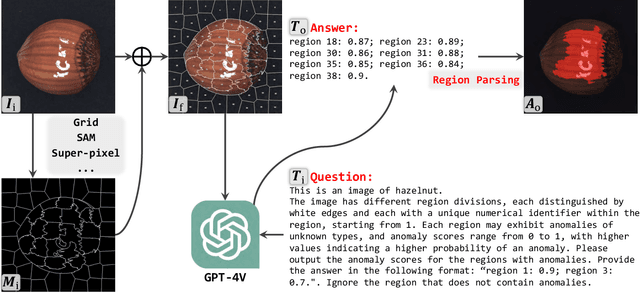
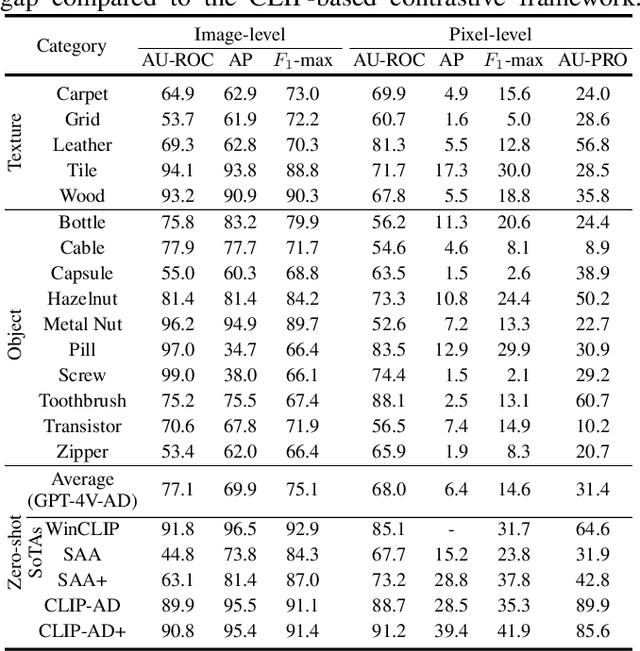

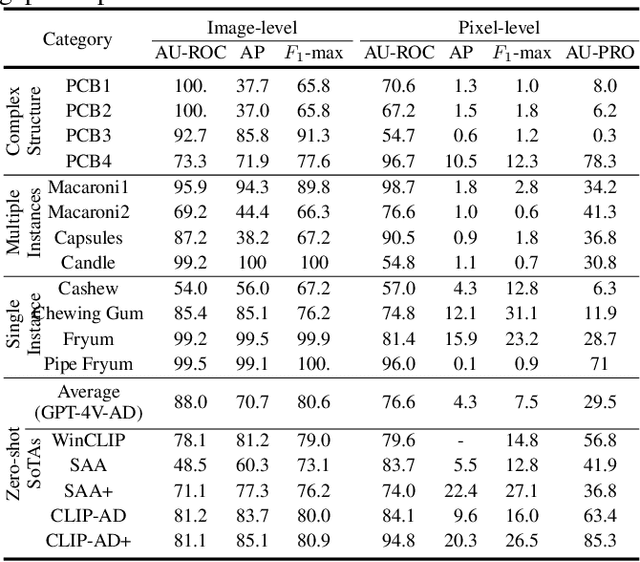
Large Multimodal Model (LMM) GPT-4V(ision) endows GPT-4 with visual grounding capabilities, making it possible to handle certain tasks through the Visual Question Answering (VQA) paradigm. This paper explores the potential of VQA-oriented GPT-4V in the recently popular visual Anomaly Detection (AD) and is the first to conduct qualitative and quantitative evaluations on the popular MVTec AD and VisA datasets. Considering that this task requires both image-/pixel-level evaluations, the proposed GPT-4V-AD framework contains three components: 1) Granular Region Division, 2) Prompt Designing, 3) Text2Segmentation for easy quantitative evaluation, and have made some different attempts for comparative analysis. The results show that GPT-4V can achieve certain results in the zero-shot AD task through a VQA paradigm, such as achieving image-level 77.1/88.0 and pixel-level 68.0/76.6 AU-ROCs on MVTec AD and VisA datasets, respectively. However, its performance still has a certain gap compared to the state-of-the-art zero-shot method, e.g., WinCLIP ann CLIP-AD, and further research is needed. This study provides a baseline reference for the research of VQA-oriented LMM in the zero-shot AD task, and we also post several possible future works. Code is available at \url{https://github.com/zhangzjn/GPT-4V-AD}.
CLIP-AD: A Language-Guided Staged Dual-Path Model for Zero-shot Anomaly Detection
Nov 01, 2023



This paper considers zero-shot Anomaly Detection (AD), a valuable yet under-studied task, which performs AD without any reference images of the test objects. Specifically, we employ a language-guided strategy and propose a simple-yet-effective architecture CLIP-AD, leveraging the superior zero-shot classification capabilities of the large vision-language model CLIP. A natural idea for anomaly segmentation is to directly calculate the similarity between text/image features, but we observe opposite predictions and irrelevant highlights in the results. Inspired by the phenomena, we introduce a Staged Dual-Path model (SDP) that effectively uses features from various levels and applies architecture and feature surgery to address these issues. Furthermore, delving beyond surface phenomena, we identify the problem arising from misalignment of text/image features in the joint embedding space. Thus, we introduce a fine-tuning strategy by adding linear layers and construct an extended model SDP+, further enhancing the performance. Abundant experiments demonstrate the effectiveness of our approach, e.g., on VisA, SDP outperforms SOTA by +1.0/+1.2 in classification/segmentation F1 scores, while SDP+ achieves +1.9/+11.7 improvements.
A Zero-/Few-Shot Anomaly Classification and Segmentation Method for CVPR 2023 VAND Workshop Challenge Tracks 1&2: 1st Place on Zero-shot AD and 4th Place on Few-shot AD
Jun 13, 2023



In this technical report, we briefly introduce our solution for the Zero/Few-shot Track of the Visual Anomaly and Novelty Detection (VAND) 2023 Challenge. For industrial visual inspection, building a single model that can be rapidly adapted to numerous categories without or with only a few normal reference images is a promising research direction. This is primarily because of the vast variety of the product types. For the zero-shot track, we propose a solution based on the CLIP model by adding extra linear layers. These layers are used to map the image features to the joint embedding space, so that they can compare with the text features to generate the anomaly maps. Besides, when the reference images are available, we utilize multiple memory banks to store their features and compare them with the features of the test images during the testing phase. In this challenge, our method achieved first place in the zero-shot track, especially excelling in segmentation with an impressive F1 score improvement of 0.0489 over the second-ranked participant. Furthermore, in the few-shot track, we secured the fourth position overall, with our classification F1 score of 0.8687 ranking first among all participating teams.
Better "CMOS" Produces Clearer Images: Learning Space-Variant Blur Estimation for Blind Image Super-Resolution
Apr 07, 2023



Most of the existing blind image Super-Resolution (SR) methods assume that the blur kernels are space-invariant. However, the blur involved in real applications are usually space-variant due to object motion, out-of-focus, etc., resulting in severe performance drop of the advanced SR methods. To address this problem, we firstly introduce two new datasets with out-of-focus blur, i.e., NYUv2-BSR and Cityscapes-BSR, to support further researches of blind SR with space-variant blur. Based on the datasets, we design a novel Cross-MOdal fuSion network (CMOS) that estimate both blur and semantics simultaneously, which leads to improved SR results. It involves a feature Grouping Interactive Attention (GIA) module to make the two modalities interact more effectively and avoid inconsistency. GIA can also be used for the interaction of other features because of the universality of its structure. Qualitative and quantitative experiments compared with state-of-the-art methods on above datasets and real-world images demonstrate the superiority of our method, e.g., obtaining PSNR/SSIM by +1.91/+0.0048 on NYUv2-BSR than MANet.