 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Plain ViT Reconstruction for Multi-class Unsupervised Anomaly Detection
Paper and Code
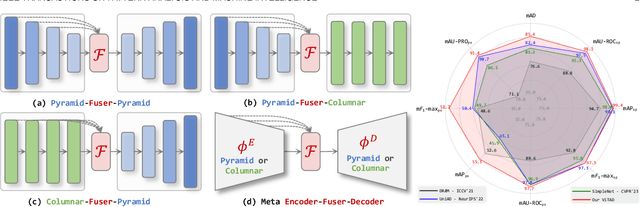
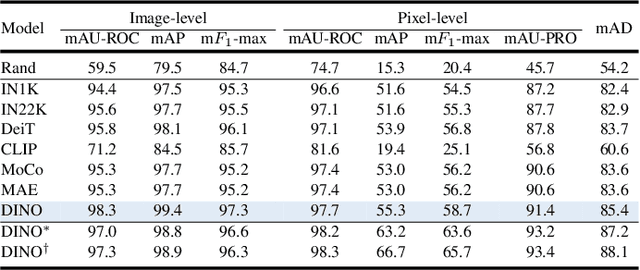
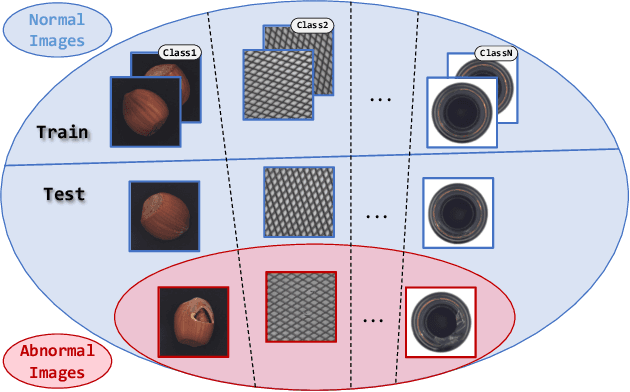
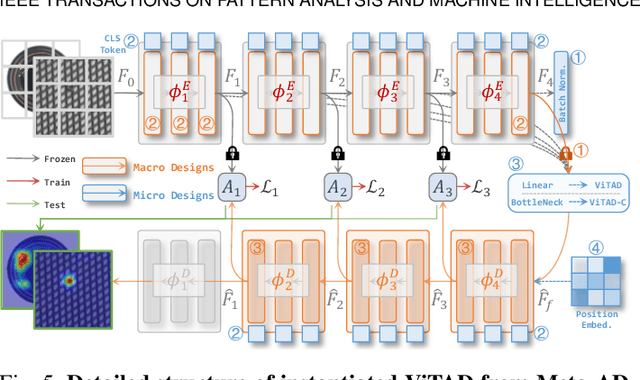
This work studies the recently proposed challenging and practical Multi-class Unsupervised Anomaly Detection (MUAD) task, which only requires normal images for training while simultaneously testing both normal/anomaly images for multiple classes. Existing reconstruction-based methods typically adopt pyramid networks as encoders/decoders to obtain multi-resolution features, accompanied by elaborate sub-modules with heavier handcraft engineering designs for more precise localization. In contrast, a plain Vision Transformer (ViT) with simple architecture has been shown effective in multiple domains, which is simpler, more effective, and elegant. Following this spirit, this paper explores plain ViT architecture for MUAD. Specifically, we abstract a Meta-AD concept by inducing current reconstruction-based methods. Then, we instantiate a novel and elegant plain ViT-based symmetric ViTAD structure, effectively designed step by step from three macro and four micro perspectives. In addition, this paper reveals several interesting findings for further exploration. Finally, we propose a comprehensive and fair evaluation benchmark on eight metrics for the MUAD task. Based on a naive training recipe, ViTAD achieves state-of-the-art (SoTA) results and efficiency on the MVTec AD and VisA datasets without bells and whistles, obtaining 85.4 mAD that surpasses SoTA UniAD by +3.0, and only requiring 1.1 hours and 2.3G GPU memory to complete model training by a single V100 GPU. Source code, models, and more results are available at https://zhangzjn.github.io/projects/ViTAD.