 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaMARP: An Adaptive Multi-Agent Interaction Framework for General Immersive Role-Playing
Jan 16, 2026LLM role-playing aims to portray arbitrary characters in interactive narratives, yet existing systems often suffer from limited immersion and adaptability. They typically under-model dynamic environmental information and assume largely static scenes and casts, offering insufficient support for multi-character orchestration, scene transitions, and on-the-fly character introduction. We propose an adaptive multi-agent role-playing framework, AdaMARP, featuring an immersive message format that interleaves [Thought], (Action), <Environment>, and Speech, together with an explicit Scene Manager that governs role-playing through discrete actions (init_scene, pick_speaker, switch_scene, add_role, end) accompanied by rationales. To train these capabilities, we construct AdaRPSet for the Actor Model and AdaSMSet for supervising orchestration decisions, and introduce AdaptiveBench for trajectory-level evaluation. Experiments across multiple backbones and model scales demonstrate consistent improvements: AdaRPSet enhances character consistency, environment grounding, and narrative coherence, with an 8B actor outperforming several commercial LLMs, while AdaSMSet enables smoother scene transitions and more natural role introductions, surpassing Claude Sonnet 4.5 using only a 14B LLM.
Disco-RAG: Discourse-Aware Retrieval-Augmented Generation
Jan 07, 2026Retrieval-Augmented Generation (RAG) has emerged as an important means of enhancing the performance of large language models (LLMs) in knowledge-intensive tasks. However, most existing RAG strategies treat retrieved passages in a flat and unstructured way, which prevents the model from capturing structural cues and constrains its ability to synthesize knowledge from dispersed evidence across documents. To overcome these limitations, we propose Disco-RAG, a discourse-aware framework that explicitly injects discourse signals into the generation process. Our method constructs intra-chunk discourse trees to capture local hierarchies and builds inter-chunk rhetorical graphs to model cross-passage coherence. These structures are jointly integrated into a planning blueprint that conditions the generation. Experiments on question answering and long-document summarization benchmarks show the efficacy of our approach. Disco-RAG achieves state-of-the-art results on the benchmarks without fine-tuning. These findings underscore the important role of discourse structure in advancing RAG systems.
The devil is in the details: Enhancing Video Virtual Try-On via Keyframe-Driven Details Injection
Dec 23, 2025Although diffusion transformer (DiT)-based video virtual try-on (VVT) has made significant progress in synthesizing realistic videos, existing methods still struggle to capture fine-grained garment dynamics and preserve background integrity across video frames. They also incur high computational costs due to additional interaction modules introduced into DiTs, while the limited scale and quality of existing public datasets also restrict model generalization and effective training. To address these challenges, we propose a novel framework, KeyTailor, along with a large-scale, high-definition dataset, ViT-HD. The core idea of KeyTailor is a keyframe-driven details injection strategy, motivated by the fact that keyframes inherently contain both foreground dynamics and background consistency. Specifically, KeyTailor adopts an instruction-guided keyframe sampling strategy to filter informative frames from the input video. Subsequently,two tailored keyframe-driven modules, the garment details enhancement module and the collaborative background optimization module, are employed to distill garment dynamics into garment-related latents and to optimize the integrity of background latents, both guided by keyframes.These enriched details are then injected into standard DiT blocks together with pose, mask, and noise latents, enabling efficient and realistic try-on video synthesis. This design ensures consistency without explicitly modifying the DiT architecture, while simultaneously avoiding additional complexity. In addition, our dataset ViT-HD comprises 15, 070 high-quality video samples at a resolution of 810*1080, covering diverse garments. Extensive experiments demonstrate that KeyTailor outperforms state-of-the-art baselines in terms of garment fidelity and background integrity across both dynamic and static scenarios.
Transform Trained Transformer: Accelerating Naive 4K Video Generation Over 10$\times$
Dec 15, 2025Native 4K (2160$\times$3840) video generation remains a critical challenge due to the quadratic computational explosion of full-attention as spatiotemporal resolution increases, making it difficult for models to strike a balance between efficiency and quality. This paper proposes a novel Transformer retrofit strategy termed $\textbf{T3}$ ($\textbf{T}$ransform $\textbf{T}$rained $\textbf{T}$ransformer) that, without altering the core architecture of full-attention pretrained models, significantly reduces compute requirements by optimizing their forward logic. Specifically, $\textbf{T3-Video}$ introduces a multi-scale weight-sharing window attention mechanism and, via hierarchical blocking together with an axis-preserving full-attention design, can effect an "attention pattern" transformation of a pretrained model using only modest compute and data. Results on 4K-VBench show that $\textbf{T3-Video}$ substantially outperforms existing approaches: while delivering performance improvements (+4.29$\uparrow$ VQA and +0.08$\uparrow$ VTC), it accelerates native 4K video generation by more than 10$\times$. Project page at https://zhangzjn.github.io/projects/T3-Video
RoleRMBench & RoleRM: Towards Reward Modeling for Profile-Based Role Play in Dialogue Systems
Dec 11, 2025Reward modeling has become a cornerstone of aligning large language models (LLMs) with human preferences. Yet, when extended to subjective and open-ended domains such as role play, existing reward models exhibit severe degradation, struggling to capture nuanced and persona-grounded human judgments. To address this gap, we introduce RoleRMBench, the first systematic benchmark for reward modeling in role-playing dialogue, covering seven fine-grained capabilities from narrative management to role consistency and engagement. Evaluation on RoleRMBench reveals large and consistent gaps between general-purpose reward models and human judgment, particularly in narrative and stylistic dimensions. We further propose RoleRM, a reward model trained with Continuous Implicit Preferences (CIP), which reformulates subjective evaluation as continuous consistent pairwise supervision under multiple structuring strategies. Comprehensive experiments show that RoleRM surpasses strong open- and closed-source reward models by over 24% on average, demonstrating substantial gains in narrative coherence and stylistic fidelity. Our findings highlight the importance of continuous preference representation and annotation consistency, establishing a foundation for subjective alignment in human-centered dialogue systems.
SwiftVideo: A Unified Framework for Few-Step Video Generation through Trajectory-Distribution Alignment
Aug 08, 2025Diffusion-based or flow-based models have achieved significant progress in video synthesis but require multiple iterative sampling steps, which incurs substantial computational overhead. While many distillation methods that are solely based on trajectory-preserving or distribution-matching have been developed to accelerate video generation models, these approaches often suffer from performance breakdown or increased artifacts under few-step settings. To address these limitations, we propose \textbf{\emph{SwiftVideo}}, a unified and stable distillation framework that combines the advantages of trajectory-preserving and distribution-matching strategies. Our approach introduces continuous-time consistency distillation to ensure precise preservation of ODE trajectories. Subsequently, we propose a dual-perspective alignment that includes distribution alignment between synthetic and real data along with trajectory alignment across different inference steps. Our method maintains high-quality video generation while substantially reducing the number of inference steps. Quantitative evaluations on the OpenVid-1M benchmark demonstrate that our method significantly outperforms existing approaches in few-step video generation.
Reasoning to Edit: Hypothetical Instruction-Based Image Editing with Visual Reasoning
Jul 02, 2025Instruction-based image editing (IIE) has advanced rapidly with the success of diffusion models. However, existing efforts primarily focus on simple and explicit instructions to execute editing operations such as adding, deleting, moving, or swapping objects. They struggle to handle more complex implicit hypothetical instructions that require deeper reasoning to infer plausible visual changes and user intent. Additionally, current datasets provide limited support for training and evaluating reasoning-aware editing capabilities. Architecturally, these methods also lack mechanisms for fine-grained detail extraction that support such reasoning. To address these limitations, we propose Reason50K, a large-scale dataset specifically curated for training and evaluating hypothetical instruction reasoning image editing, along with ReasonBrain, a novel framework designed to reason over and execute implicit hypothetical instructions across diverse scenarios. Reason50K includes over 50K samples spanning four key reasoning scenarios: Physical, Temporal, Causal, and Story reasoning. ReasonBrain leverages Multimodal Large Language Models (MLLMs) for editing guidance generation and a diffusion model for image synthesis, incorporating a Fine-grained Reasoning Cue Extraction (FRCE) module to capture detailed visual and textual semantics essential for supporting instruction reasoning. To mitigate the semantic loss, we further introduce a Cross-Modal Enhancer (CME) that enables rich interactions between the fine-grained cues and MLLM-derived features. Extensive experiments demonstrate that ReasonBrain consistently outperforms state-of-the-art baselines on reasoning scenarios while exhibiting strong zero-shot generalization to conventional IIE tasks. Our dataset and code will be released publicly.
UltraVideo: High-Quality UHD Video Dataset with Comprehensive Captions
Jun 16, 2025The quality of the video dataset (image quality, resolution, and fine-grained caption) greatly influences the performance of the video generation model. The growing demand for video applications sets higher requirements for high-quality video generation models. For example, the generation of movie-level Ultra-High Definition (UHD) videos and the creation of 4K short video content. However, the existing public datasets cannot support related research and applications. In this paper, we first propose a high-quality open-sourced UHD-4K (22.4\% of which are 8K) text-to-video dataset named UltraVideo, which contains a wide range of topics (more than 100 kinds), and each video has 9 structured captions with one summarized caption (average of 824 words). Specifically, we carefully design a highly automated curation process with four stages to obtain the final high-quality dataset: \textit{i)} collection of diverse and high-quality video clips. \textit{ii)} statistical data filtering. \textit{iii)} model-based data purification. \textit{iv)} generation of comprehensive, structured captions. In addition, we expand Wan to UltraWan-1K/-4K, which can natively generate high-quality 1K/4K videos with more consistent text controllability, demonstrating the effectiveness of our data curation.We believe that this work can make a significant contribution to future research on UHD video generation. UltraVideo dataset and UltraWan models are available at https://xzc-zju.github.io/projects/UltraVideo.
Swin DiT: Diffusion Transformer using Pseudo Shifted Windows
May 19, 2025Diffusion Transformers (DiTs) achieve remarkable performance within the domain of image generation through the incorporation of the transformer architecture. Conventionally, DiTs are constructed by stacking serial isotropic global information modeling transformers, which face significant computational cost when processing high-resolution images. We empirically analyze that latent space image generation does not exhibit a strong dependence on global information as traditionally assumed. Most of the layers in the model demonstrate redundancy in global computation. In addition, conventional attention mechanisms exhibit low-frequency inertia issues. To address these issues, we propose \textbf{P}seudo \textbf{S}hifted \textbf{W}indow \textbf{A}ttention (PSWA), which fundamentally mitigates global model redundancy. PSWA achieves intermediate global-local information interaction through window attention, while employing a high-frequency bridging branch to simulate shifted window operations, supplementing appropriate global and high-frequency information. Furthermore, we propose the Progressive Coverage Channel Allocation(PCCA) strategy that captures high-order attention similarity without additional computational cost. Building upon all of them, we propose a series of Pseudo \textbf{S}hifted \textbf{Win}dow DiTs (\textbf{Swin DiT}), accompanied by extensive experiments demonstrating their superior performance. For example, our proposed Swin-DiT-L achieves a 54%$\uparrow$ FID improvement over DiT-XL/2 while requiring less computational. https://github.com/wujiafu007/Swin-DiT
UniCombine: Unified Multi-Conditional Combination with Diffusion Transformer
Mar 12, 2025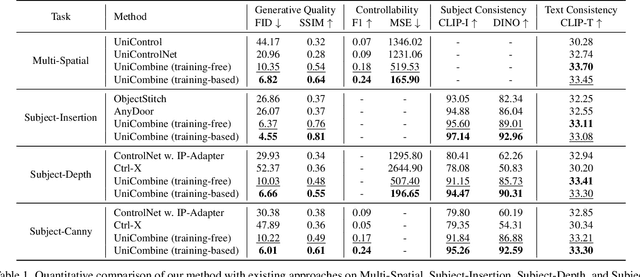
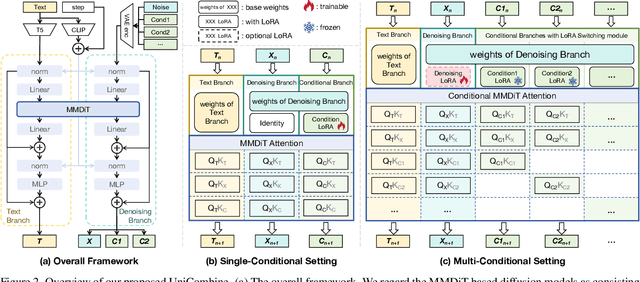
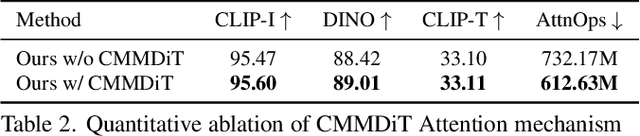
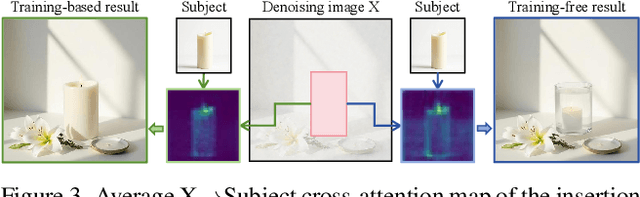
With the rapid development of diffusion models in image generation, the demand for more powerful and flexible controllable frameworks is increasing. Although existing methods can guide generation beyond text prompts, the challenge of effectively combining multiple conditional inputs while maintaining consistency with all of them remains unsolved. To address this, we introduce UniCombine, a DiT-based multi-conditional controllable generative framework capable of handling any combination of conditions, including but not limited to text prompts, spatial maps, and subject images. Specifically, we introduce a novel Conditional MMDiT Attention mechanism and incorporate a trainable LoRA module to build both the training-free and training-based versions. Additionally, we propose a new pipeline to construct SubjectSpatial200K, the first dataset designed for multi-conditional generative tasks covering both the subject-driven and spatially-aligned conditions. Extensive experimental results on multi-conditional generation demonstrate the outstanding universality and powerful capability of our approach with state-of-the-art performance.