 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromptRL: Prompt Matters in RL for Flow-Based Image Generation
Feb 01, 2026Flow matching models (FMs) have revolutionized text-to-image (T2I) generation, with reinforcement learning (RL) serving as a critical post-training strategy for alignment with reward objectives. In this research, we show that current RL pipelines for FMs suffer from two underappreciated yet important limitations: sample inefficiency due to insufficient generation diversity, and pronounced prompt overfitting, where models memorize specific training formulations and exhibit dramatic performance collapse when evaluated on semantically equivalent but stylistically varied prompts. We present PromptRL (Prompt Matters in RL for Flow-Based Image Generation), a framework that incorporates language models (LMs) as trainable prompt refinement agents directly within the flow-based RL optimization loop. This design yields two complementary benefits: rapid development of sophisticated prompt rewriting capabilities and, critically, a synergistic training regime that reshapes the optimization dynamics. PromptRL achieves state-of-the-art performance across multiple benchmarks, obtaining scores of 0.97 on GenEval, 0.98 on OCR accuracy, and 24.05 on PickScore. Furthermore, we validate the effectiveness of our RL approach on large-scale image editing models, improving the EditReward of FLUX.1-Kontext from 1.19 to 1.43 with only 0.06 million rollouts, surpassing Gemini 2.5 Flash Image (also known as Nano Banana), which scores 1.37, and achieving comparable performance with ReasonNet (1.44), which relied on fine-grained data annotations along with a complex multi-stage training. Our extensive experiments empirically demonstrate that PromptRL consistently achieves higher performance ceilings while requiring over 2$\times$ fewer rollouts compared to naive flow-only RL. Our code is available at https://github.com/G-U-N/UniRL.
MixFlow Training: Alleviating Exposure Bias with Slowed Interpolation Mixture
Dec 22, 2025This paper studies the training-testing discrepancy (a.k.a. exposure bias) problem for improving the diffusion models. During training, the input of a prediction network at one training timestep is the corresponding ground-truth noisy data that is an interpolation of the noise and the data, and during testing, the input is the generated noisy data. We present a novel training approach, named MixFlow, for improving the performance. Our approach is motivated by the Slow Flow phenomenon: the ground-truth interpolation that is the nearest to the generated noisy data at a given sampling timestep is observed to correspond to a higher-noise timestep (termed slowed timestep), i.e., the corresponding ground-truth timestep is slower than the sampling timestep. MixFlow leverages the interpolations at the slowed timesteps, named slowed interpolation mixture, for post-training the prediction network for each training timestep. Experiments over class-conditional image generation (including SiT, REPA, and RAE) and text-to-image generation validate the effectiveness of our approach. Our approach MixFlow over the RAE models achieve strong generation results on ImageNet: 1.43 FID (without guidance) and 1.10 (with guidance) at 256 x 256, and 1.55 FID (without guidance) and 1.10 (with guidance) at 512 x 512.
Image Diffusion Preview with Consistency Solver
Dec 15, 2025The slow inference process of image diffusion models significantly degrades interactive user experiences. To address this, we introduce Diffusion Preview, a novel paradigm employing rapid, low-step sampling to generate preliminary outputs for user evaluation, deferring full-step refinement until the preview is deemed satisfactory. Existing acceleration methods, including training-free solvers and post-training distillation, struggle to deliver high-quality previews or ensure consistency between previews and final outputs. We propose ConsistencySolver derived from general linear multistep methods, a lightweight, trainable high-order solver optimized via Reinforcement Learning, that enhances preview quality and consistency. Experimental results demonstrate that ConsistencySolver significantly improves generation quality and consistency in low-step scenarios, making it ideal for efficient preview-and-refine workflows. Notably, it achieves FID scores on-par with Multistep DPM-Solver using 47% fewer steps, while outperforming distillation baselines. Furthermore, user studies indicate our approach reduces overall user interaction time by nearly 50% while maintaining generation quality. Code is available at https://github.com/G-U-N/consolver.
Self-NPO: Negative Preference Optimization of Diffusion Models by Simply Learning from Itself without Explicit Preference Annotations
May 17, 2025Diffusion models have demonstrated remarkable success in various visual generation tasks, including image, video, and 3D content generation. Preference optimization (PO) is a prominent and growing area of research that aims to align these models with human preferences. While existing PO methods primarily concentrate on producing favorable outputs, they often overlook the significance of classifier-free guidance (CFG) in mitigating undesirable results. Diffusion-NPO addresses this gap by introducing negative preference optimization (NPO), training models to generate outputs opposite to human preferences and thereby steering them away from unfavorable outcomes. However, prior NPO approaches, including Diffusion-NPO, rely on costly and fragile procedures for obtaining explicit preference annotations (e.g., manual pairwise labeling or reward model training), limiting their practicality in domains where such data are scarce or difficult to acquire. In this work, we introduce Self-NPO, a Negative Preference Optimization approach that learns exclusively from the model itself, thereby eliminating the need for manual data labeling or reward model training. Moreover, our method is highly efficient and does not require exhaustive data sampling. We demonstrate that Self-NPO integrates seamlessly into widely used diffusion models, including SD1.5, SDXL, and CogVideoX, as well as models already optimized for human preferences, consistently enhancing both their generation quality and alignment with human preferences.
Diffusion-NPO: Negative Preference Optimization for Better Preference Aligned Generation of Diffusion Models
May 16, 2025Diffusion models have made substantial advances in image generation, yet models trained on large, unfiltered datasets often yield outputs misaligned with human preferences. Numerous methods have been proposed to fine-tune pre-trained diffusion models, achieving notable improvements in aligning generated outputs with human preferences. However, we argue that existing preference alignment methods neglect the critical role of handling unconditional/negative-conditional outputs, leading to a diminished capacity to avoid generating undesirable outcomes. This oversight limits the efficacy of classifier-free guidance~(CFG), which relies on the contrast between conditional generation and unconditional/negative-conditional generation to optimize output quality. In response, we propose a straightforward but versatile effective approach that involves training a model specifically attuned to negative preferences. This method does not require new training strategies or datasets but rather involves minor modifications to existing techniques. Our approach integrates seamlessly with models such as SD1.5, SDXL, video diffusion models and models that have undergone preference optimization, consistently enhancing their alignment with human preferences.
GS-DiT: Advancing Video Generation with Pseudo 4D Gaussian Fields through Efficient Dense 3D Point Tracking
Jan 05, 2025



4D video control is essential in video generation as it enables the use of sophisticated lens techniques, such as multi-camera shooting and dolly zoom, which are currently unsupported by existing methods. Training a video Diffusion Transformer (DiT) directly to control 4D content requires expensive multi-view videos. Inspired by Monocular Dynamic novel View Synthesis (MDVS) that optimizes a 4D representation and renders videos according to different 4D elements, such as camera pose and object motion editing, we bring pseudo 4D Gaussian fields to video generation. Specifically, we propose a novel framework that constructs a pseudo 4D Gaussian field with dense 3D point tracking and renders the Gaussian field for all video frames. Then we finetune a pretrained DiT to generate videos following the guidance of the rendered video, dubbed as GS-DiT. To boost the training of the GS-DiT, we also propose an efficient Dense 3D Point Tracking (D3D-PT) method for the pseudo 4D Gaussian field construction. Our D3D-PT outperforms SpatialTracker, the state-of-the-art sparse 3D point tracking method, in accuracy and accelerates the inference speed by two orders of magnitude. During the inference stage, GS-DiT can generate videos with the same dynamic content while adhering to different camera parameters, addressing a significant limitation of current video generation models. GS-DiT demonstrates strong generalization capabilities and extends the 4D controllability of Gaussian splatting to video generation beyond just camera poses. It supports advanced cinematic effects through the manipulation of the Gaussian field and camera intrinsics, making it a powerful tool for creative video production. Demos are available at https://wkbian.github.io/Projects/GS-DiT/.
BlinkVision: A Benchmark for Optical Flow, Scene Flow and Point Tracking Estimation using RGB Frames and Events
Oct 27, 2024Recent advances in event-based vision suggest that these systems complement traditional cameras by providing continuous observation without frame rate limitations and a high dynamic range, making them well-suited for correspondence tasks such as optical flow and point tracking. However, there is still a lack of comprehensive benchmarks for correspondence tasks that include both event data and images. To address this gap, we propose BlinkVision, a large-scale and diverse benchmark with multiple modalities and dense correspondence annotations. BlinkVision offers several valuable features: 1) Rich modalities: It includes both event data and RGB images. 2) Extensive annotations: It provides dense per-pixel annotations covering optical flow, scene flow, and point tracking. 3) Large vocabulary: It contains 410 everyday categories, sharing common classes with popular 2D and 3D datasets like LVIS and ShapeNet. 4) Naturalistic: It delivers photorealistic data and covers various naturalistic factors, such as camera shake and deformation. BlinkVision enables extensive benchmarks on three types of correspondence tasks (optical flow, point tracking, and scene flow estimation) for both image-based and event-based methods, offering new observations, practices, and insights for future research. The benchmark website is https://www.blinkvision.net/.
Stable Consistency Tuning: Understanding and Improving Consistency Models
Oct 24, 2024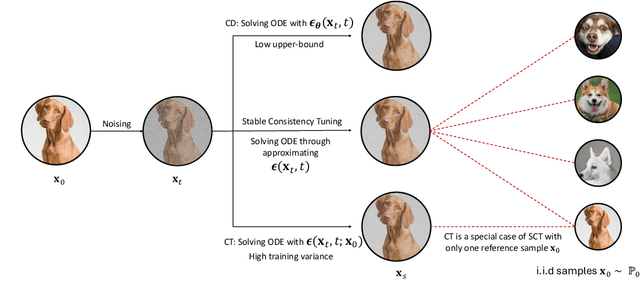

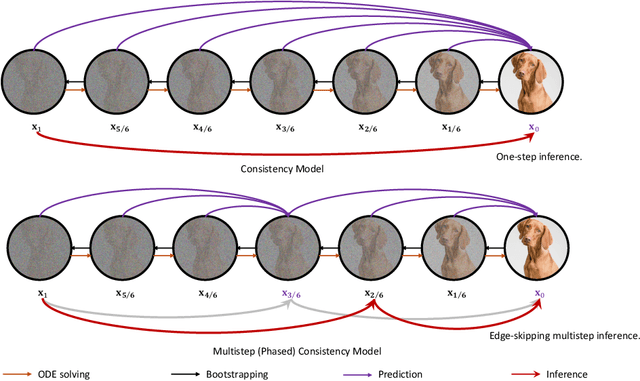
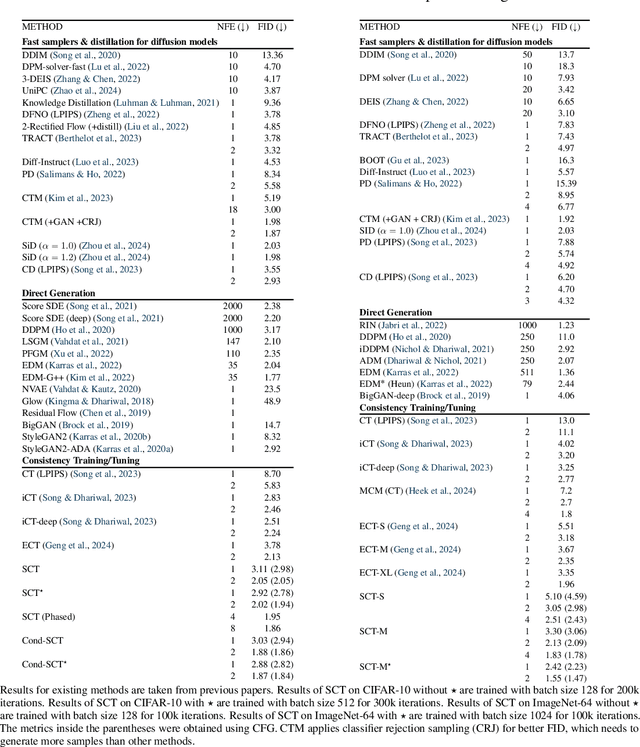
Diffusion models achieve superior generation quality but suffer from slow generation speed due to the iterative nature of denoising. In contrast, consistency models, a new generative family, achieve competitive performance with significantly faster sampling. These models are trained either through consistency distillation, which leverages pretrained diffusion models, or consistency training/tuning directly from raw data. In this work, we propose a novel framework for understanding consistency models by modeling the denoising process of the diffusion model as a Markov Decision Process (MDP) and framing consistency model training as the value estimation through Temporal Difference~(TD) Learning. More importantly, this framework allows us to analyze the limitations of current consistency training/tuning strategies. Built upon Easy Consistency Tuning (ECT), we propose Stable Consistency Tuning (SCT), which incorporates variance-reduced learning using the score identity. SCT leads to significant performance improvements on benchmarks such as CIFAR-10 and ImageNet-64. On ImageNet-64, SCT achieves 1-step FID 2.42 and 2-step FID 1.55, a new SoTA for consistency models.
Rectified Diffusion: Straightness Is Not Your Need in Rectified Flow
Oct 09, 2024Diffusion models have greatly improved visual generation but are hindered by slow generation speed due to the computationally intensive nature of solving generative ODEs. Rectified flow, a widely recognized solution, improves generation speed by straightening the ODE path. Its key components include: 1) using the diffusion form of flow-matching, 2) employing $\boldsymbol v$-prediction, and 3) performing rectification (a.k.a. reflow). In this paper, we argue that the success of rectification primarily lies in using a pretrained diffusion model to obtain matched pairs of noise and samples, followed by retraining with these matched noise-sample pairs. Based on this, components 1) and 2) are unnecessary. Furthermore, we highlight that straightness is not an essential training target for rectification; rather, it is a specific case of flow-matching models. The more critical training target is to achieve a first-order approximate ODE path, which is inherently curved for models like DDPM and Sub-VP. Building on this insight, we propose Rectified Diffusion, which generalizes the design space and application scope of rectification to encompass the broader category of diffusion models, rather than being restricted to flow-matching models. We validate our method on Stable Diffusion v1-5 and Stable Diffusion XL. Our method not only greatly simplifies the training procedure of rectified flow-based previous works (e.g., InstaFlow) but also achieves superior performance with even lower training cost. Our code is available at https://github.com/G-U-N/Rectified-Diffusion.
Trans4D: Realistic Geometry-Aware Transition for Compositional Text-to-4D Synthesis
Oct 09, 2024Recent advances in diffusion models have demonstrated exceptional capabilities in image and video generation, further improving the effectiveness of 4D synthesis. Existing 4D generation methods can generate high-quality 4D objects or scenes based on user-friendly conditions, benefiting the gaming and video industries. However, these methods struggle to synthesize significant object deformation of complex 4D transitions and interactions within scenes. To address this challenge, we propose Trans4D, a novel text-to-4D synthesis framework that enables realistic complex scene transitions. Specifically, we first use multi-modal large language models (MLLMs) to produce a physic-aware scene description for 4D scene initialization and effective transition timing planning. Then we propose a geometry-aware 4D transition network to realize a complex scene-level 4D transition based on the plan, which involves expressive geometrical object deformation. Extensive experiments demonstrate that Trans4D consistently outperforms existing state-of-the-art methods in generating 4D scenes with accurate and high-quality transitions, validating its effectiveness. Code: https://github.com/YangLing0818/Trans4D