 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemanticGen: Video Generation in Semantic Space
Dec 24, 2025

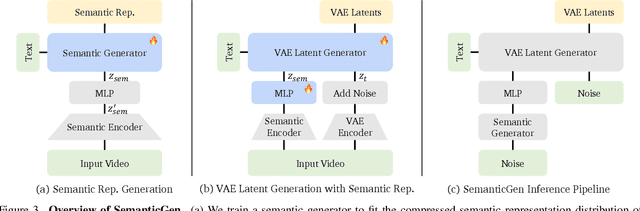

State-of-the-art video generative models typically learn the distribution of video latents in the VAE space and map them to pixels using a VAE decoder. While this approach can generate high-quality videos, it suffers from slow convergence and is computationally expensive when generating long videos. In this paper, we introduce SemanticGen, a novel solution to address these limitations by generating videos in the semantic space. Our main insight is that, due to the inherent redundancy in videos, the generation process should begin in a compact, high-level semantic space for global planning, followed by the addition of high-frequency details, rather than directly modeling a vast set of low-level video tokens using bi-directional attention. SemanticGen adopts a two-stage generation process. In the first stage, a diffusion model generates compact semantic video features, which define the global layout of the video. In the second stage, another diffusion model generates VAE latents conditioned on these semantic features to produce the final output. We observe that generation in the semantic space leads to faster convergence compared to the VAE latent space. Our method is also effective and computationally efficient when extended to long video generation. Extensive experiments demonstrate that SemanticGen produces high-quality videos and outperforms state-of-the-art approaches and strong baselines.
Kling-Omni Technical Report
Dec 18, 2025



We present Kling-Omni, a generalist generative framework designed to synthesize high-fidelity videos directly from multimodal visual language inputs. Adopting an end-to-end perspective, Kling-Omni bridges the functional separation among diverse video generation, editing, and intelligent reasoning tasks, integrating them into a holistic system. Unlike disjointed pipeline approaches, Kling-Omni supports a diverse range of user inputs, including text instructions, reference images, and video contexts, processing them into a unified multimodal representation to deliver cinematic-quality and highly-intelligent video content creation. To support these capabilities, we constructed a comprehensive data system that serves as the foundation for multimodal video creation. The framework is further empowered by efficient large-scale pre-training strategies and infrastructure optimizations for inference. Comprehensive evaluations reveal that Kling-Omni demonstrates exceptional capabilities in in-context generation, reasoning-based editing, and multimodal instruction following. Moving beyond a content creation tool, we believe Kling-Omni is a pivotal advancement toward multimodal world simulators capable of perceiving, reasoning, generating and interacting with the dynamic and complex worlds.
SVG-T2I: Scaling Up Text-to-Image Latent Diffusion Model Without Variational Autoencoder
Dec 12, 2025Visual generation grounded in Visual Foundation Model (VFM) representations offers a highly promising unified pathway for integrating visual understanding, perception, and generation. Despite this potential, training large-scale text-to-image diffusion models entirely within the VFM representation space remains largely unexplored. To bridge this gap, we scale the SVG (Self-supervised representations for Visual Generation) framework, proposing SVG-T2I to support high-quality text-to-image synthesis directly in the VFM feature domain. By leveraging a standard text-to-image diffusion pipeline, SVG-T2I achieves competitive performance, reaching 0.75 on GenEval and 85.78 on DPG-Bench. This performance validates the intrinsic representational power of VFMs for generative tasks. We fully open-source the project, including the autoencoder and generation model, together with their training, inference, evaluation pipelines, and pre-trained weights, to facilitate further research in representation-driven visual generation.
Deep Reward Supervisions for Tuning Text-to-Image Diffusion Models
May 01, 2024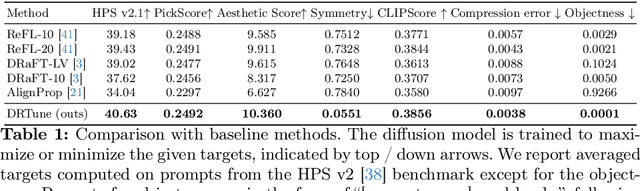
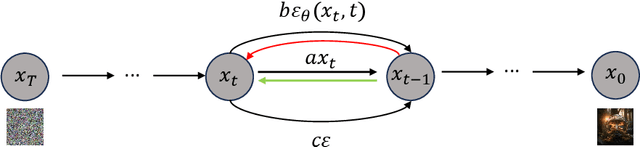
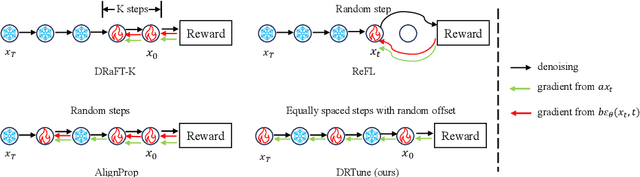

Optimizing a text-to-image diffusion model with a given reward function is an important but underexplored research area. In this study, we propose Deep Reward Tuning (DRTune), an algorithm that directly supervises the final output image of a text-to-image diffusion model and back-propagates through the iterative sampling process to the input noise. We find that training earlier steps in the sampling process is crucial for low-level rewards, and deep supervision can be achieved efficiently and effectively by stopping the gradient of the denoising network input. DRTune is extensively evaluated on various reward models. It consistently outperforms other algorithms, particularly for low-level control signals, where all shallow supervision methods fail. Additionally, we fine-tune Stable Diffusion XL 1.0 (SDXL 1.0) model via DRTune to optimize Human Preference Score v2.1, resulting in the Favorable Diffusion XL 1.0 (FDXL 1.0) model. FDXL 1.0 significantly enhances image quality compared to SDXL 1.0 and reaches comparable quality compared with Midjourney v5.2.
CoMat: Aligning Text-to-Image Diffusion Model with Image-to-Text Concept Matching
Apr 04, 2024



Diffusion models have demonstrated great success in the field of text-to-image generation. However, alleviating the misalignment between the text prompts and images is still challenging. The root reason behind the misalignment has not been extensively investigated. We observe that the misalignment is caused by inadequate token attention activation. We further attribute this phenomenon to the diffusion model's insufficient condition utilization, which is caused by its training paradigm. To address the issue, we propose CoMat, an end-to-end diffusion model fine-tuning strategy with an image-to-text concept matching mechanism. We leverage an image captioning model to measure image-to-text alignment and guide the diffusion model to revisit ignored tokens. A novel attribute concentration module is also proposed to address the attribute binding problem. Without any image or human preference data, we use only 20K text prompts to fine-tune SDXL to obtain CoMat-SDXL. Extensive experiments show that CoMat-SDXL significantly outperforms the baseline model SDXL in two text-to-image alignment benchmarks and achieves start-of-the-art performance.
ECNet: Effective Controllable Text-to-Image Diffusion Models
Mar 27, 2024The conditional text-to-image diffusion models have garnered significant attention in recent years. However, the precision of these models is often compromised mainly for two reasons, ambiguous condition input and inadequate condition guidance over single denoising loss. To address the challenges, we introduce two innovative solutions. Firstly, we propose a Spatial Guidance Injector (SGI) which enhances conditional detail by encoding text inputs with precise annotation information. This method directly tackles the issue of ambiguous control inputs by providing clear, annotated guidance to the model. Secondly, to overcome the issue of limited conditional supervision, we introduce Diffusion Consistency Loss (DCL), which applies supervision on the denoised latent code at any given time step. This encourages consistency between the latent code at each time step and the input signal, thereby enhancing the robustness and accuracy of the output. The combination of SGI and DCL results in our Effective Controllable Network (ECNet), which offers a more accurate controllable end-to-end text-to-image generation framework with a more precise conditioning input and stronger controllable supervision. We validate our approach through extensive experiments on generation under various conditions, such as human body skeletons, facial landmarks, and sketches of general objects. The results consistently demonstrate that our method significantly enhances the controllability and robustness of the generated images, outperforming existing state-of-the-art controllable text-to-image models.
Be-Your-Outpainter: Mastering Video Outpainting through Input-Specific Adaptation
Mar 20, 2024


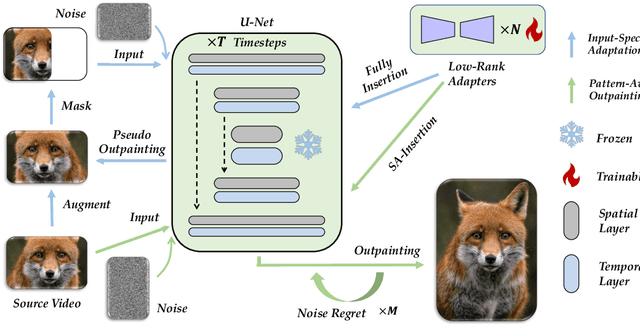
Video outpainting is a challenging task, aiming at generating video content outside the viewport of the input video while maintaining inter-frame and intra-frame consistency. Existing methods fall short in either generation quality or flexibility. We introduce MOTIA Mastering Video Outpainting Through Input-Specific Adaptation, a diffusion-based pipeline that leverages both the intrinsic data-specific patterns of the source video and the image/video generative prior for effective outpainting. MOTIA comprises two main phases: input-specific adaptation and pattern-aware outpainting. The input-specific adaptation phase involves conducting efficient and effective pseudo outpainting learning on the single-shot source video. This process encourages the model to identify and learn patterns within the source video, as well as bridging the gap between standard generative processes and outpainting. The subsequent phase, pattern-aware outpainting, is dedicated to the generalization of these learned patterns to generate outpainting outcomes. Additional strategies including spatial-aware insertion and noise travel are proposed to better leverage the diffusion model's generative prior and the acquired video patterns from source videos. Extensive evaluations underscore MOTIA's superiority, outperforming existing state-of-the-art methods in widely recognized benchmarks. Notably, these advancements are achieved without necessitating extensive, task-specific tuning.
JourneyDB: A Benchmark for Generative Image Understanding
Jul 03, 2023While recent advancements in vision-language models have revolutionized multi-modal understanding, it remains unclear whether they possess the capabilities of comprehending the generated images. Compared to real data, synthetic images exhibit a higher degree of diversity in both content and style, for which there are significant difficulties for the models to fully apprehend. To this end, we present a large-scale dataset, JourneyDB, for multi-modal visual understanding in generative images. Our curated dataset covers 4 million diverse and high-quality generated images paired with the text prompts used to produce them. We further design 4 benchmarks to quantify the performance of generated image understanding in terms of both content and style interpretation. These benchmarks include prompt inversion, style retrieval, image captioning and visual question answering. Lastly, we assess the performance of current state-of-the-art multi-modal models when applied to JourneyDB, and provide an in-depth analysis of their strengths and limitations in generated content understanding. We hope the proposed dataset and benchmarks will facilitate the research in the field of generative content understanding. The dataset will be available on https://journeydb.github.io.
Human Preference Score v2: A Solid Benchmark for Evaluating Human Preferences of Text-to-Image Synthesis
Jun 15, 2023



Recent text-to-image generative models can generate high-fidelity images from text inputs, but the quality of these generated images cannot be accurately evaluated by existing evaluation metrics. To address this issue, we introduce Human Preference Dataset v2 (HPD v2), a large-scale dataset that captures human preferences on images from a wide range of sources. HPD v2 comprises 798,090 human preference choices on 430,060 pairs of images, making it the largest dataset of its kind. The text prompts and images are deliberately collected to eliminate potential bias, which is a common issue in previous datasets. By fine-tuning CLIP on HPD v2, we obtain Human Preference Score v2 (HPS v2), a scoring model that can more accurately predict text-generated images' human preferences. Our experiments demonstrate that HPS v2 generalizes better than previous metrics across various image distributions and is responsive to algorithmic improvements of text-to-image generative models, making it a preferable evaluation metric for these models. We also investigate the design of the evaluation prompts for text-to-image generative models, to make the evaluation stable, fair and easy-to-use. Finally, we establish a benchmark for text-to-image generative models using HPS v2, which includes a set of recent text-to-image models from the academia, community and industry. The code and dataset is / will be available at https://github.com/tgxs002/HPSv2.
Better Aligning Text-to-Image Models with Human Preference
Mar 25, 2023



Recent years have witnessed a rapid growth of deep generative models, with text-to-image models gaining significant attention from the public. However, existing models often generate images that do not align well with human aesthetic preferences, such as awkward combinations of limbs and facial expressions. To address this issue, we collect a dataset of human choices on generated images from the Stable Foundation Discord channel. Our experiments demonstrate that current evaluation metrics for generative models do not correlate well with human choices. Thus, we train a human preference classifier with the collected dataset and derive a Human Preference Score (HPS) based on the classifier. Using the HPS, we propose a simple yet effective method to adapt Stable Diffusion to better align with human aesthetic preferences. Our experiments show that the HPS outperforms CLIP in predicting human choices and has good generalization capability towards images generated from other models. By tuning Stable Diffusion with the guidance of the HPS, the adapted model is able to generate images that are more preferred by human users.