 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiroFlow: Towards High-Performance and Robust Open-Source Agent Framework for General Deep Research Tasks
Feb 26, 2026Despite the remarkable progress of large language models (LLMs), the capabilities of standalone LLMs have begun to plateau when tackling real-world, complex tasks that require interaction with external tools and dynamic environments. Although recent agent frameworks aim to enhance model autonomy through tool integration and external interaction, they still suffer from naive workflows, unstable performance, limited support across diverse benchmarks and tasks, and heavy reliance on costly commercial APIs. In this work, we propose a high-performance and robust open-source agent framework, termed MiroFlow, which incorporates an agent graph for flexible orchestration, an optional deep reasoning mode to enhance performance, and a robust workflow execution to ensure stable and reproducible performance. Extensive experiments demonstrate that MiroFlow consistently achieves state-of-the-art performance across multiple agent benchmarks, including GAIA, BrowseComp-EN/ZH, HLE, xBench-DeepSearch, and notably FutureX. We hope it could serve as an easily accessible, reproducible, and comparable baseline for the deep research community.
MiroThinker: Pushing the Performance Boundaries of Open-Source Research Agents via Model, Context, and Interactive Scaling
Nov 18, 2025We present MiroThinker v1.0, an open-source research agent designed to advance tool-augmented reasoning and information-seeking capabilities. Unlike previous agents that only scale up model size or context length, MiroThinker explores interaction scaling at the model level, systematically training the model to handle deeper and more frequent agent-environment interactions as a third dimension of performance improvement. Unlike LLM test-time scaling, which operates in isolation and risks degradation with longer reasoning chains, interactive scaling leverages environment feedback and external information acquisition to correct errors and refine trajectories. Through reinforcement learning, the model achieves efficient interaction scaling: with a 256K context window, it can perform up to 600 tool calls per task, enabling sustained multi-turn reasoning and complex real-world research workflows. Across four representative benchmarks-GAIA, HLE, BrowseComp, and BrowseComp-ZH-the 72B variant achieves up to 81.9%, 37.7%, 47.1%, and 55.6% accuracy respectively, surpassing previous open-source agents and approaching commercial counterparts such as GPT-5-high. Our analysis reveals that MiroThinker benefits from interactive scaling consistently: research performance improves predictably as the model engages in deeper and more frequent agent-environment interactions, demonstrating that interaction depth exhibits scaling behaviors analogous to model size and context length. These findings establish interaction scaling as a third critical dimension for building next-generation open research agents, complementing model capacity and context windows.
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Aug 25, 2025



We introduce InternVL 3.5, a new family of open-source multimodal models that significantly advances versatility, reasoning capability, and inference efficiency along the InternVL series. A key innovation is the Cascade Reinforcement Learning (Cascade RL) framework, which enhances reasoning through a two-stage process: offline RL for stable convergence and online RL for refined alignment. This coarse-to-fine training strategy leads to substantial improvements on downstream reasoning tasks, e.g., MMMU and MathVista. To optimize efficiency, we propose a Visual Resolution Router (ViR) that dynamically adjusts the resolution of visual tokens without compromising performance. Coupled with ViR, our Decoupled Vision-Language Deployment (DvD) strategy separates the vision encoder and language model across different GPUs, effectively balancing computational load. These contributions collectively enable InternVL3.5 to achieve up to a +16.0\% gain in overall reasoning performance and a 4.05$\times$ inference speedup compared to its predecessor, i.e., InternVL3. In addition, InternVL3.5 supports novel capabilities such as GUI interaction and embodied agency. Notably, our largest model, i.e., InternVL3.5-241B-A28B, attains state-of-the-art results among open-source MLLMs across general multimodal, reasoning, text, and agentic tasks -- narrowing the performance gap with leading commercial models like GPT-5. All models and code are publicly released.
CoMemo: LVLMs Need Image Context with Image Memory
Jun 06, 2025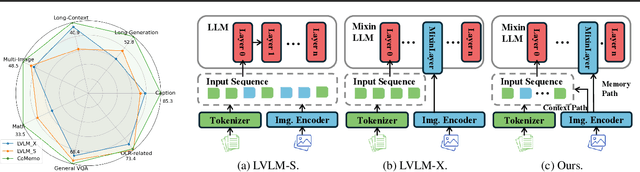
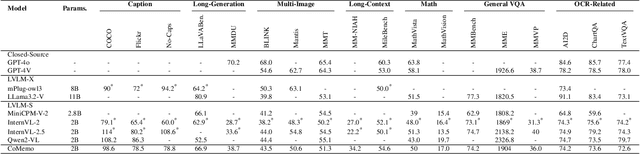
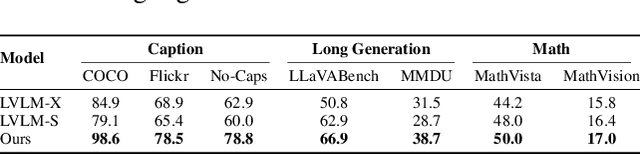
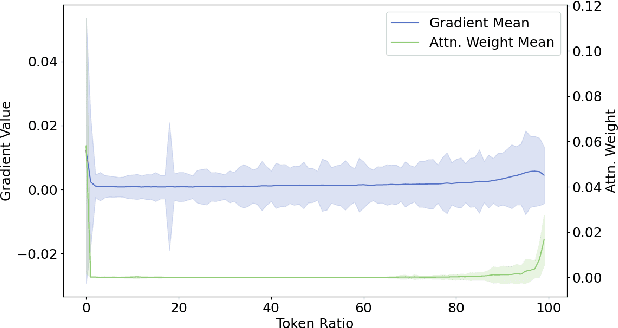
Recent advancements in Large Vision-Language Models built upon Large Language Models have established aligning visual features with LLM representations as the dominant paradigm. However, inherited LLM architectural designs introduce suboptimal characteristics for multimodal processing. First, LVLMs exhibit a bimodal distribution in attention allocation, leading to the progressive neglect of middle visual content as context expands. Second, conventional positional encoding schemes fail to preserve vital 2D structural relationships when processing dynamic high-resolution images. To address these limitations, we propose CoMemo - a dual-path architecture that combines a Context image path with an image Memory path for visual processing, effectively alleviating visual information neglect. Additionally, we introduce RoPE-DHR, a novel positional encoding mechanism that employs thumbnail-based positional aggregation to maintain 2D spatial awareness while mitigating remote decay in extended sequences. Evaluations across seven benchmarks,including long-context comprehension, multi-image reasoning, and visual question answering, demonstrate CoMemo's superior performance compared to conventional LVLM architectures. Project page is available at https://lalbj.github.io/projects/CoMemo/.
ZeroGUI: Automating Online GUI Learning at Zero Human Cost
May 29, 2025



The rapid advancement of large Vision-Language Models (VLMs) has propelled the development of pure-vision-based GUI Agents, capable of perceiving and operating Graphical User Interfaces (GUI) to autonomously fulfill user instructions. However, existing approaches usually adopt an offline learning framework, which faces two core limitations: (1) heavy reliance on high-quality manual annotations for element grounding and action supervision, and (2) limited adaptability to dynamic and interactive environments. To address these limitations, we propose ZeroGUI, a scalable, online learning framework for automating GUI Agent training at Zero human cost. Specifically, ZeroGUI integrates (i) VLM-based automatic task generation to produce diverse training goals from the current environment state, (ii) VLM-based automatic reward estimation to assess task success without hand-crafted evaluation functions, and (iii) two-stage online reinforcement learning to continuously interact with and learn from GUI environments. Experiments on two advanced GUI Agents (UI-TARS and Aguvis) demonstrate that ZeroGUI significantly boosts performance across OSWorld and AndroidLab environments. The code is available at https://github.com/OpenGVLab/ZeroGUI.
VisuLogic: A Benchmark for Evaluating Visual Reasoning in Multi-modal Large Language Models
Apr 21, 2025



Visual reasoning is a core component of human intelligence and a critical capability for advanced multimodal models. Yet current reasoning evaluations of multimodal large language models (MLLMs) often rely on text descriptions and allow language-based reasoning shortcuts, failing to measure genuine vision-centric reasoning. To address this, we introduce VisuLogic: a benchmark of 1,000 human-verified problems across six categories (e.g., quantitative shifts, spatial relations, attribute comparisons). These various types of questions can be evaluated to assess the visual reasoning capabilities of MLLMs from multiple perspectives. We evaluate leading MLLMs on this benchmark and analyze their results to identify common failure modes. Most models score below 30% accuracy-only slightly above the 25% random baseline and far below the 51.4% achieved by humans-revealing significant gaps in visual reasoning. Furthermore, we provide a supplementary training dataset and a reinforcement-learning baseline to support further progress.
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Apr 15, 2025We introduce InternVL3, a significant advancement in the InternVL series featuring a native multimodal pre-training paradigm. Rather than adapting a text-only large language model (LLM) into a multimodal large language model (MLLM) that supports visual inputs, InternVL3 jointly acquires multimodal and linguistic capabilities from both diverse multimodal data and pure-text corpora during a single pre-training stage. This unified training paradigm effectively addresses the complexities and alignment challenges commonly encountered in conventional post-hoc training pipelines for MLLMs. To further improve performance and scalability, InternVL3 incorporates variable visual position encoding (V2PE) to support extended multimodal contexts, employs advanced post-training techniques such as supervised fine-tuning (SFT) and mixed preference optimization (MPO), and adopts test-time scaling strategies alongside an optimized training infrastructure. Extensive empirical evaluations demonstrate that InternVL3 delivers superior performance across a wide range of multi-modal tasks. In particular, InternVL3-78B achieves a score of 72.2 on the MMMU benchmark, setting a new state-of-the-art among open-source MLLMs. Its capabilities remain highly competitive with leading proprietary models, including ChatGPT-4o, Claude 3.5 Sonnet, and Gemini 2.5 Pro, while also maintaining strong pure-language proficiency. In pursuit of open-science principles, we will publicly release both the training data and model weights to foster further research and development in next-generation MLLMs.
LangBridge: Interpreting Image as a Combination of Language Embeddings
Mar 26, 2025



Recent years have witnessed remarkable advances in Large Vision-Language Models (LVLMs), which have achieved human-level performance across various complex vision-language tasks. Following LLaVA's paradigm, mainstream LVLMs typically employ a shallow MLP for visual-language alignment through a two-stage training process: pretraining for cross-modal alignment followed by instruction tuning. While this approach has proven effective, the underlying mechanisms of how MLPs bridge the modality gap remain poorly understood. Although some research has explored how LLMs process transformed visual tokens, few studies have investigated the fundamental alignment mechanism. Furthermore, the MLP adapter requires retraining whenever switching LLM backbones. To address these limitations, we first investigate the working principles of MLP adapters and discover that they learn to project visual embeddings into subspaces spanned by corresponding text embeddings progressively. Based on this insight, we propose LangBridge, a novel adapter that explicitly maps visual tokens to linear combinations of LLM vocabulary embeddings. This innovative design enables pretraining-free adapter transfer across different LLMs while maintaining performance. Our experimental results demonstrate that a LangBridge adapter pre-trained on Qwen2-0.5B can be directly applied to larger models such as LLaMA3-8B or Qwen2.5-14B while maintaining competitive performance. Overall, LangBridge enables interpretable vision-language alignment by grounding visual representations in LLM vocab embedding, while its plug-and-play design ensures efficient reuse across multiple LLMs with nearly no performance degradation. See our project page at https://jiaqiliao77.github.io/LangBridge.github.io/
Dita: Scaling Diffusion Transformer for Generalist Vision-Language-Action Policy
Mar 25, 2025While recent vision-language-action models trained on diverse robot datasets exhibit promising generalization capabilities with limited in-domain data, their reliance on compact action heads to predict discretized or continuous actions constrains adaptability to heterogeneous action spaces. We present Dita, a scalable framework that leverages Transformer architectures to directly denoise continuous action sequences through a unified multimodal diffusion process. Departing from prior methods that condition denoising on fused embeddings via shallow networks, Dita employs in-context conditioning -- enabling fine-grained alignment between denoised actions and raw visual tokens from historical observations. This design explicitly models action deltas and environmental nuances. By scaling the diffusion action denoiser alongside the Transformer's scalability, Dita effectively integrates cross-embodiment datasets across diverse camera perspectives, observation scenes, tasks, and action spaces. Such synergy enhances robustness against various variances and facilitates the successful execution of long-horizon tasks. Evaluations across extensive benchmarks demonstrate state-of-the-art or comparative performance in simulation. Notably, Dita achieves robust real-world adaptation to environmental variances and complex long-horizon tasks through 10-shot finetuning, using only third-person camera inputs. The architecture establishes a versatile, lightweight and open-source baseline for generalist robot policy learning. Project Page: https://robodita.github.io.
VisualPRM: An Effective Process Reward Model for Multimodal Reasoning
Mar 13, 2025



We introduce VisualPRM, an advanced multimodal Process Reward Model (PRM) with 8B parameters, which improves the reasoning abilities of existing Multimodal Large Language Models (MLLMs) across different model scales and families with Best-of-N (BoN) evaluation strategies. Specifically, our model improves the reasoning performance of three types of MLLMs and four different model scales. Even when applied to the highly capable InternVL2.5-78B, it achieves a 5.9-point improvement across seven multimodal reasoning benchmarks. Experimental results show that our model exhibits superior performance compared to Outcome Reward Models and Self-Consistency during BoN evaluation. To facilitate the training of multimodal PRMs, we construct a multimodal process supervision dataset VisualPRM400K using an automated data pipeline. For the evaluation of multimodal PRMs, we propose VisualProcessBench, a benchmark with human-annotated step-wise correctness labels, to measure the abilities of PRMs to detect erroneous steps in multimodal reasoning tasks. We hope that our work can inspire more future research and contribute to the development of MLLMs. Our model, data, and benchmark are released in https://internvl.github.io/blog/2025-03-13-VisualPRM/.