 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEVA: Efficient Reinforcement Learning for End-to-End Video Agent
Mar 24, 2026Video understanding with multimodal large language models (MLLMs) remains challenging due to the long token sequences of videos, which contain extensive temporal dependencies and redundant frames. Existing approaches typically treat MLLMs as passive recognizers, processing entire videos or uniformly sampled frames without adaptive reasoning. Recent agent-based methods introduce external tools, yet still depend on manually designed workflows and perception-first strategies, resulting in inefficiency on long videos. We present EVA, an Efficient Reinforcement Learning framework for End-to-End Video Agent, which enables planning-before-perception through iterative summary-plan-action-reflection reasoning. EVA autonomously decides what to watch, when to watch, and how to watch, achieving query-driven and efficient video understanding. To train such agents, we design a simple yet effective three-stage learning pipeline - comprising supervised fine-tuning (SFT), Kahneman-Tversky Optimization (KTO), and Generalized Reward Policy Optimization (GRPO) - that bridges supervised imitation and reinforcement learning. We further construct high-quality datasets for each stage, supporting stable and reproducible training. We evaluate EVA on six video understanding benchmarks, demonstrating its comprehensive capabilities. Compared with existing baselines, EVA achieves a substantial improvement of 6-12% over general MLLM baselines and a further 1-3% gain over prior adaptive agent methods. Our code and model are available at https://github.com/wangruohui/EfficientVideoAgent.
ScaleADFG: Affordance-based Dexterous Functional Grasping via Scalable Dataset
Nov 12, 2025Dexterous functional tool-use grasping is essential for effective robotic manipulation of tools. However, existing approaches face significant challenges in efficiently constructing large-scale datasets and ensuring generalizability to everyday object scales. These issues primarily arise from size mismatches between robotic and human hands, and the diversity in real-world object scales. To address these limitations, we propose the ScaleADFG framework, which consists of a fully automated dataset construction pipeline and a lightweight grasp generation network. Our dataset introduce an affordance-based algorithm to synthesize diverse tool-use grasp configurations without expert demonstrations, allowing flexible object-hand size ratios and enabling large robotic hands (compared to human hands) to grasp everyday objects effectively. Additionally, we leverage pre-trained models to generate extensive 3D assets and facilitate efficient retrieval of object affordances. Our dataset comprising five object categories, each containing over 1,000 unique shapes with 15 scale variations. After filtering, the dataset includes over 60,000 grasps for each 2 dexterous robotic hands. On top of this dataset, we train a lightweight, single-stage grasp generation network with a notably simple loss design, eliminating the need for post-refinement. This demonstrates the critical importance of large-scale datasets and multi-scale object variant for effective training. Extensive experiments in simulation and on real robot confirm that the ScaleADFG framework exhibits strong adaptability to objects of varying scales, enhancing functional grasp stability, diversity, and generalizability. Moreover, our network exhibits effective zero-shot transfer to real-world objects. Project page is available at https://sizhe-wang.github.io/ScaleADFG_webpage
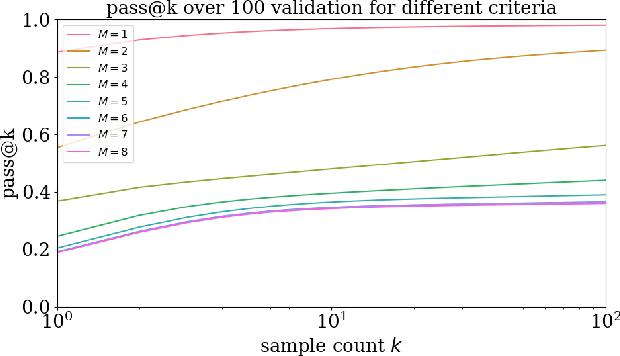
Measuring Scientific Capabilities of Language Models with a Systems Biology Dry Lab
Jul 02, 2025
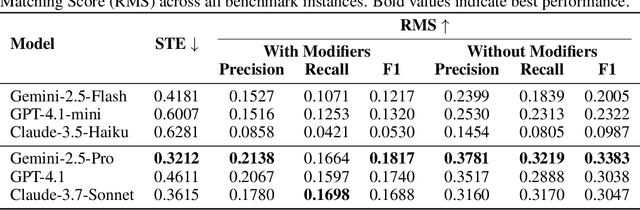
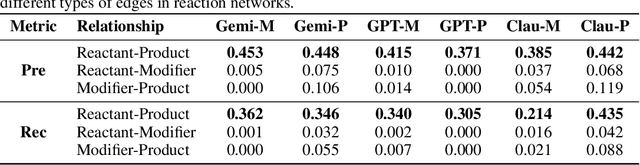
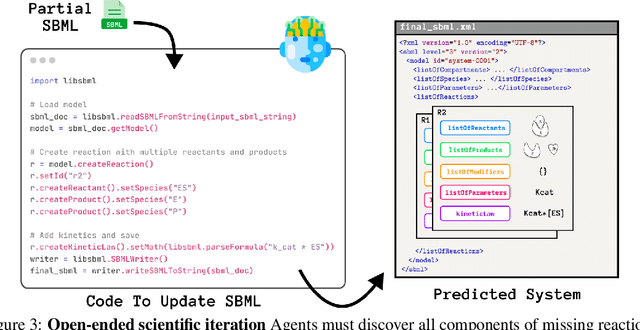
Designing experiments and result interpretations are core scientific competencies, particularly in biology, where researchers perturb complex systems to uncover the underlying systems. Recent efforts to evaluate the scientific capabilities of large language models (LLMs) fail to test these competencies because wet-lab experimentation is prohibitively expensive: in expertise, time and equipment. We introduce SciGym, a first-in-class benchmark that assesses LLMs' iterative experiment design and analysis abilities in open-ended scientific discovery tasks. SciGym overcomes the challenge of wet-lab costs by running a dry lab of biological systems. These models, encoded in Systems Biology Markup Language, are efficient for generating simulated data, making them ideal testbeds for experimentation on realistically complex systems. We evaluated six frontier LLMs on 137 small systems, and released a total of 350 systems. Our evaluation shows that while more capable models demonstrated superior performance, all models' performance declined significantly as system complexity increased, suggesting substantial room for improvement in the scientific capabilities of LLM agents.
BioReason: Incentivizing Multimodal Biological Reasoning within a DNA-LLM Model
May 29, 2025
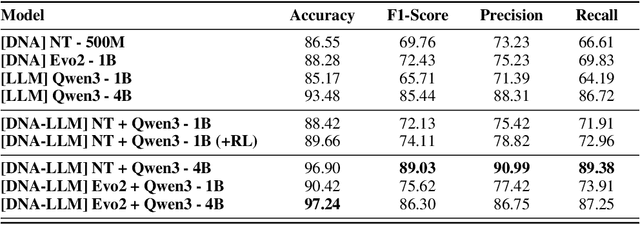


Unlocking deep, interpretable biological reasoning from complex genomic data is a major AI challenge hindering scientific discovery. Current DNA foundation models, despite strong sequence representation, struggle with multi-step reasoning and lack inherent transparent, biologically intuitive explanations. We introduce BioReason, a pioneering architecture that, for the first time, deeply integrates a DNA foundation model with a Large Language Model (LLM). This novel connection enables the LLM to directly process and reason with genomic information as a fundamental input, fostering a new form of multimodal biological understanding. BioReason's sophisticated multi-step reasoning is developed through supervised fine-tuning and targeted reinforcement learning, guiding the system to generate logical, biologically coherent deductions. On biological reasoning benchmarks including KEGG-based disease pathway prediction - where accuracy improves from 88% to 97% - and variant effect prediction, BioReason demonstrates an average 15% performance gain over strong single-modality baselines. BioReason reasons over unseen biological entities and articulates decision-making through interpretable, step-by-step biological traces, offering a transformative approach for AI in biology that enables deeper mechanistic insights and accelerates testable hypothesis generation from genomic data. Data, code, and checkpoints are publicly available at https://github.com/bowang-lab/BioReason
Dita: Scaling Diffusion Transformer for Generalist Vision-Language-Action Policy
Mar 25, 2025While recent vision-language-action models trained on diverse robot datasets exhibit promising generalization capabilities with limited in-domain data, their reliance on compact action heads to predict discretized or continuous actions constrains adaptability to heterogeneous action spaces. We present Dita, a scalable framework that leverages Transformer architectures to directly denoise continuous action sequences through a unified multimodal diffusion process. Departing from prior methods that condition denoising on fused embeddings via shallow networks, Dita employs in-context conditioning -- enabling fine-grained alignment between denoised actions and raw visual tokens from historical observations. This design explicitly models action deltas and environmental nuances. By scaling the diffusion action denoiser alongside the Transformer's scalability, Dita effectively integrates cross-embodiment datasets across diverse camera perspectives, observation scenes, tasks, and action spaces. Such synergy enhances robustness against various variances and facilitates the successful execution of long-horizon tasks. Evaluations across extensive benchmarks demonstrate state-of-the-art or comparative performance in simulation. Notably, Dita achieves robust real-world adaptation to environmental variances and complex long-horizon tasks through 10-shot finetuning, using only third-person camera inputs. The architecture establishes a versatile, lightweight and open-source baseline for generalist robot policy learning. Project Page: https://robodita.github.io.
On the Privacy Risk of In-context Learning
Nov 15, 2024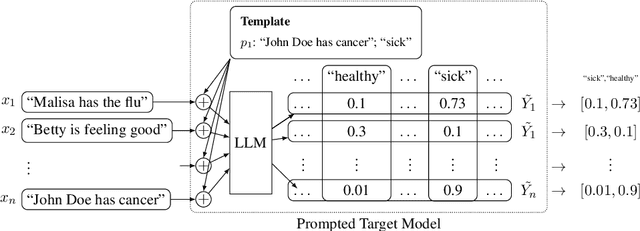
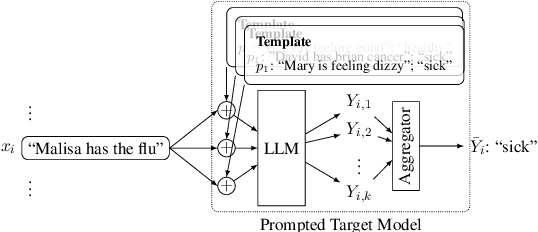

Large language models (LLMs) are excellent few-shot learners. They can perform a wide variety of tasks purely based on natural language prompts provided to them. These prompts contain data of a specific downstream task -- often the private dataset of a party, e.g., a company that wants to leverage the LLM for their purposes. We show that deploying prompted models presents a significant privacy risk for the data used within the prompt by instantiating a highly effective membership inference attack. We also observe that the privacy risk of prompted models exceeds fine-tuned models at the same utility levels. After identifying the model's sensitivity to their prompts -- in the form of a significantly higher prediction confidence on the prompted data -- as a cause for the increased risk, we propose ensembling as a mitigation strategy. By aggregating over multiple different versions of a prompted model, membership inference risk can be decreased.
Can LLMs Understand Social Norms in Autonomous Driving Games?
Aug 22, 2024



Social norm is defined as a shared standard of acceptable behavior in a society. The emergence of social norms fosters coordination among agents without any hard-coded rules, which is crucial for the large-scale deployment of AVs in an intelligent transportation system. This paper explores the application of LLMs in understanding and modeling social norms in autonomous driving games. We introduce LLMs into autonomous driving games as intelligent agents who make decisions according to text prompts. These agents are referred to as LLM-based agents. Our framework involves LLM-based agents playing Markov games in a multi-agent system (MAS), allowing us to investigate the emergence of social norms among individual agents. We aim to identify social norms by designing prompts and utilizing LLMs on textual information related to the environment setup and the observations of LLM-based agents. Using the OpenAI Chat API powered by GPT-4.0, we conduct experiments to simulate interactions and evaluate the performance of LLM-based agents in two driving scenarios: unsignalized intersection and highway platoon. The results show that LLM-based agents can handle dynamically changing environments in Markov games, and social norms evolve among LLM-based agents in both scenarios. In the intersection game, LLM-based agents tend to adopt a conservative driving policy when facing a potential car crash. The advantage of LLM-based agents in games lies in their strong operability and analyzability, which facilitate experimental design.
Meta-Designing Quantum Experiments with Language Models
Jun 04, 2024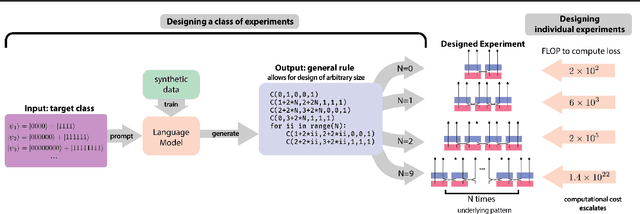


Artificial Intelligence (AI) has the potential to significantly advance scientific discovery by finding solutions beyond human capabilities. However, these super-human solutions are often unintuitive and require considerable effort to uncover underlying principles, if possible at all. Here, we show how a code-generating language model trained on synthetic data can not only find solutions to specific problems but can create meta-solutions, which solve an entire class of problems in one shot and simultaneously offer insight into the underlying design principles. Specifically, for the design of new quantum physics experiments, our sequence-to-sequence transformer architecture generates interpretable Python code that describes experimental blueprints for a whole class of quantum systems. We discover general and previously unknown design rules for infinitely large classes of quantum states. The ability to automatically generate generalized patterns in readable computer code is a crucial step toward machines that help discover new scientific understanding -- one of the central aims of physics.
Flocks of Stochastic Parrots: Differentially Private Prompt Learning for Large Language Models
May 24, 2023Large language models (LLMs) are excellent in-context learners. However, the sensitivity of data contained in prompts raises privacy concerns. Our work first shows that these concerns are valid: we instantiate a simple but highly effective membership inference attack against the data used to prompt LLMs. To address this vulnerability, one could forego prompting and resort to fine-tuning LLMs with known algorithms for private gradient descent. However, this comes at the expense of the practicality and efficiency offered by prompting. Therefore, we propose to privately learn to prompt. We first show that soft prompts can be obtained privately through gradient descent on downstream data. However, this is not the case for discrete prompts. Thus, we orchestrate a noisy vote among an ensemble of LLMs presented with different prompts, i.e., a flock of stochastic parrots. The vote privately transfers the flock's knowledge into a single public prompt. We show that LLMs prompted with our private algorithms closely match the non-private baselines. For example, using GPT3 as the base model, we achieve a downstream accuracy of 92.7% on the sst2 dataset with ($\epsilon=0.147, \delta=10^{-6}$)-differential privacy vs. 95.2% for the non-private baseline. Through our experiments, we also show that our prompt-based approach is easily deployed with existing commercial APIs.
Progressive Transfer Learning for Dexterous In-Hand Manipulation with Multi-Fingered Anthropomorphic Hand
Apr 19, 2023



Dexterous in-hand manipulation for a multi-fingered anthropomorphic hand is extremely difficult because of the high-dimensional state and action spaces, rich contact patterns between the fingers and objects. Even though deep reinforcement learning has made moderate progress and demonstrated its strong potential for manipulation, it is still faced with certain challenges, such as large-scale data collection and high sample complexity. Especially, for some slight change scenes, it always needs to re-collect vast amounts of data and carry out numerous iterations of fine-tuning. Remarkably, humans can quickly transfer learned manipulation skills to different scenarios with little supervision. Inspired by human flexible transfer learning capability, we propose a novel dexterous in-hand manipulation progressive transfer learning framework (PTL) based on efficiently utilizing the collected trajectories and the source-trained dynamics model. This framework adopts progressive neural networks for dynamics model transfer learning on samples selected by a new samples selection method based on dynamics properties, rewards and scores of the trajectories. Experimental results on contact-rich anthropomorphic hand manipulation tasks show that our method can efficiently and effectively learn in-hand manipulation skills with a few online attempts and adjustment learning under the new scene. Compared to learning from scratch, our method can reduce training time costs by 95%.