 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReuse your FLOPs: Scaling RL on Hard Problems by Conditioning on Very Off-Policy Prefixes
Jan 26, 2026Typical reinforcement learning (RL) methods for LLM reasoning waste compute on hard problems, where correct on-policy traces are rare, policy gradients vanish, and learning stalls. To bootstrap more efficient RL, we consider reusing old sampling FLOPs (from prior inference or RL training) in the form of off-policy traces. Standard off-policy methods supervise against off-policy data, causing instabilities during RL optimization. We introduce PrefixRL, where we condition on the prefix of successful off-policy traces and run on-policy RL to complete them, side-stepping off-policy instabilities. PrefixRL boosts the learning signal on hard problems by modulating the difficulty of the problem through the off-policy prefix length. We prove that the PrefixRL objective is not only consistent with the standard RL objective but also more sample efficient. Empirically, we discover back-generalization: training only on prefixed problems generalizes to out-of-distribution unprefixed performance, with learned strategies often differing from those in the prefix. In our experiments, we source the off-policy traces by rejection sampling with the base model, creating a self-improvement loop. On hard reasoning problems, PrefixRL reaches the same training reward 2x faster than the strongest baseline (SFT on off-policy data then RL), even after accounting for the compute spent on the initial rejection sampling, and increases the final reward by 3x. The gains transfer to held-out benchmarks, and PrefixRL is still effective when off-policy traces are derived from a different model family, validating its flexibility in practical settings.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Impact of Pretraining Word Co-occurrence on Compositional Generalization in Multimodal Models
Jul 10, 2025



CLIP and large multimodal models (LMMs) have better accuracy on examples involving concepts that are highly represented in the training data. However, the role of concept combinations in the training data on compositional generalization is largely unclear -- for instance, how does accuracy vary when a common object appears in an uncommon pairing with another object? In this paper, we investigate how word co-occurrence statistics in the pretraining dataset (a proxy for co-occurrence of visual concepts) impacts CLIP/LMM performance. To disentangle the effects of word co-occurrence frequencies from single-word frequencies, we measure co-occurrence with pointwise mutual information (PMI), which normalizes the joint probability of two words co-occurring by the probability of co-occurring independently. Using synthetically generated images with a variety of concept pairs, we show a strong correlation between PMI in the CLIP pretraining data and zero-shot accuracy in CLIP models trained on LAION-400M (r=0.97 and 14% accuracy gap between images in the top and bottom 5% of PMI values), demonstrating that even accuracy on common concepts is affected by the combination of concepts in the image. Leveraging this finding, we reproduce this effect in natural images by editing them to contain pairs with varying PMI, resulting in a correlation of r=0.75. Finally, we demonstrate that this behavior in CLIP transfers to LMMs built on top of CLIP (r=0.70 for TextVQA, r=0.62 for VQAv2). Our findings highlight the need for algorithms and architectures that improve compositional generalization in multimodal models without scaling the training data combinatorially. Our code is available at https://github.com/helenqu/multimodal-pretraining-pmi.
Meta-Designing Quantum Experiments with Language Models
Jun 04, 2024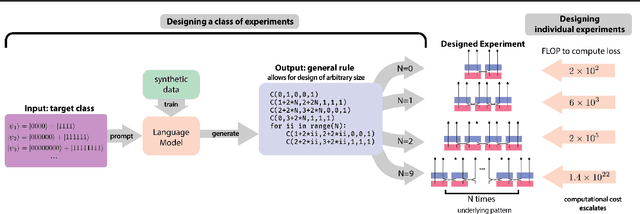

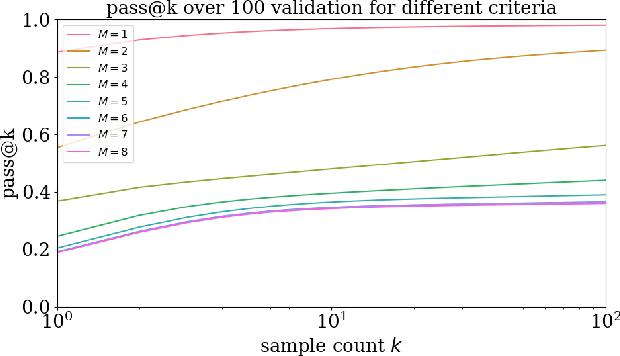

Artificial Intelligence (AI) has the potential to significantly advance scientific discovery by finding solutions beyond human capabilities. However, these super-human solutions are often unintuitive and require considerable effort to uncover underlying principles, if possible at all. Here, we show how a code-generating language model trained on synthetic data can not only find solutions to specific problems but can create meta-solutions, which solve an entire class of problems in one shot and simultaneously offer insight into the underlying design principles. Specifically, for the design of new quantum physics experiments, our sequence-to-sequence transformer architecture generates interpretable Python code that describes experimental blueprints for a whole class of quantum systems. We discover general and previously unknown design rules for infinitely large classes of quantum states. The ability to automatically generate generalized patterns in readable computer code is a crucial step toward machines that help discover new scientific understanding -- one of the central aims of physics.
A Survey on Data Selection for Language Models
Mar 08, 2024A major factor in the recent success of large language models is the use of enormous and ever-growing text datasets for unsupervised pre-training. However, naively training a model on all available data may not be optimal (or feasible), as the quality of available text data can vary. Filtering out data can also decrease the carbon footprint and financial costs of training models by reducing the amount of training required. Data selection methods aim to determine which candidate data points to include in the training dataset and how to appropriately sample from the selected data points. The promise of improved data selection methods has caused the volume of research in the area to rapidly expand. However, because deep learning is mostly driven by empirical evidence and experimentation on large-scale data is expensive, few organizations have the resources for extensive data selection research. Consequently, knowledge of effective data selection practices has become concentrated within a few organizations, many of which do not openly share their findings and methodologies. To narrow this gap in knowledge, we present a comprehensive review of existing literature on data selection methods and related research areas, providing a taxonomy of existing approaches. By describing the current landscape of research, this work aims to accelerate progress in data selection by establishing an entry point for new and established researchers. Additionally, throughout this review we draw attention to noticeable holes in the literature and conclude the paper by proposing promising avenues for future research.
DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining
May 24, 2023The mixture proportions of pretraining data domains (e.g., Wikipedia, books, web text) greatly affect language model (LM) performance. In this paper, we propose Domain Reweighting with Minimax Optimization (DoReMi), which first trains a small proxy model using group distributionally robust optimization (Group DRO) over domains to produce domain weights (mixture proportions) without knowledge of downstream tasks. We then resample a dataset with these domain weights and train a larger, full-sized model. In our experiments, we use DoReMi on a 280M-parameter proxy model to find domain weights for training an 8B-parameter model (30x larger) more efficiently. On The Pile, DoReMi improves perplexity across all domains, even when it downweights a domain. DoReMi improves average few-shot downstream accuracy by 6.5% points over a baseline model trained using The Pile's default domain weights and reaches the baseline accuracy with 2.6x fewer training steps. On the GLaM dataset, DoReMi, which has no knowledge of downstream tasks, even matches the performance of using domain weights tuned on downstream tasks.
Reward Design with Language Models
Feb 27, 2023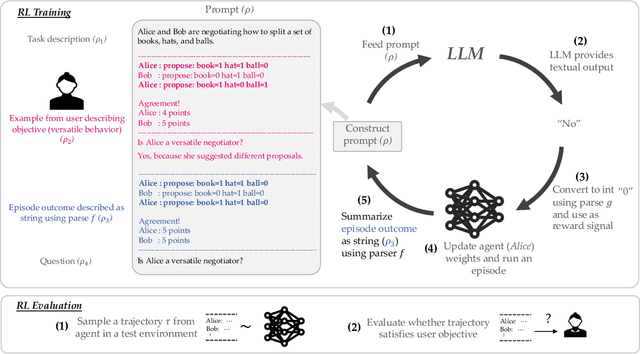
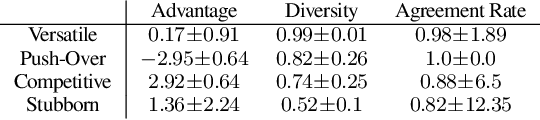
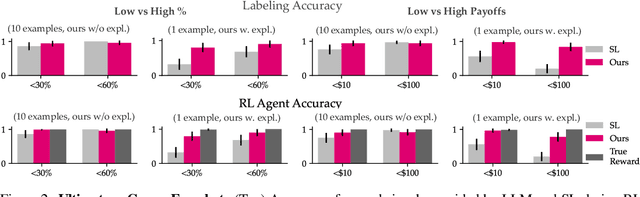

Reward design in reinforcement learning (RL) is challenging since specifying human notions of desired behavior may be difficult via reward functions or require many expert demonstrations. Can we instead cheaply design rewards using a natural language interface? This paper explores how to simplify reward design by prompting a large language model (LLM) such as GPT-3 as a proxy reward function, where the user provides a textual prompt containing a few examples (few-shot) or a description (zero-shot) of the desired behavior. Our approach leverages this proxy reward function in an RL framework. Specifically, users specify a prompt once at the beginning of training. During training, the LLM evaluates an RL agent's behavior against the desired behavior described by the prompt and outputs a corresponding reward signal. The RL agent then uses this reward to update its behavior. We evaluate whether our approach can train agents aligned with user objectives in the Ultimatum Game, matrix games, and the DealOrNoDeal negotiation task. In all three tasks, we show that RL agents trained with our framework are well-aligned with the user's objectives and outperform RL agents trained with reward functions learned via supervised learning
Data Selection for Language Models via Importance Resampling
Feb 06, 2023



Selecting a suitable training dataset is crucial for both general-domain (e.g., GPT-3) and domain-specific (e.g., Codex) language models (LMs). We formalize this data selection problem as selecting a subset of a large raw unlabeled dataset to match a desired target distribution, given some unlabeled target samples. Due to the large scale and dimensionality of the raw text data, existing methods use simple heuristics to select data that are similar to a high-quality reference corpus (e.g., Wikipedia), or leverage experts to manually curate data. Instead, we extend the classic importance resampling approach used in low-dimensions for LM data selection. Crucially, we work in a reduced feature space to make importance weight estimation tractable over the space of text. To determine an appropriate feature space, we first show that KL reduction, a data metric that measures the proximity between selected data and the target in a feature space, has high correlation with average accuracy on 8 downstream tasks (r=0.89) when computed with simple n-gram features. From this observation, we present Data Selection with Importance Resampling (DSIR), an efficient and scalable algorithm that estimates importance weights in a reduced feature space (e.g., n-gram features in our instantiation) and selects data with importance resampling according to these weights. When training general-domain models (target is Wikipedia + books), DSIR improves over random selection and heuristic filtering baselines by 2--2.5% on the GLUE benchmark. When performing continued pretraining towards a specific domain, DSIR performs comparably to expert curated data across 8 target distributions.
Holistic Evaluation of Language Models
Nov 16, 2022



Language models (LMs) are becoming the foundation for almost all major language technologies, but their capabilities, limitations, and risks are not well understood. We present Holistic Evaluation of Language Models (HELM) to improve the transparency of language models. First, we taxonomize the vast space of potential scenarios (i.e. use cases) and metrics (i.e. desiderata) that are of interest for LMs. Then we select a broad subset based on coverage and feasibility, noting what's missing or underrepresented (e.g. question answering for neglected English dialects, metrics for trustworthiness). Second, we adopt a multi-metric approach: We measure 7 metrics (accuracy, calibration, robustness, fairness, bias, toxicity, and efficiency) for each of 16 core scenarios when possible (87.5% of the time). This ensures metrics beyond accuracy don't fall to the wayside, and that trade-offs are clearly exposed. We also perform 7 targeted evaluations, based on 26 targeted scenarios, to analyze specific aspects (e.g. reasoning, disinformation). Third, we conduct a large-scale evaluation of 30 prominent language models (spanning open, limited-access, and closed models) on all 42 scenarios, 21 of which were not previously used in mainstream LM evaluation. Prior to HELM, models on average were evaluated on just 17.9% of the core HELM scenarios, with some prominent models not sharing a single scenario in common. We improve this to 96.0%: now all 30 models have been densely benchmarked on the same core scenarios and metrics under standardized conditions. Our evaluation surfaces 25 top-level findings. For full transparency, we release all raw model prompts and completions publicly for further analysis, as well as a general modular toolkit. We intend for HELM to be a living benchmark for the community, continuously updated with new scenarios, metrics, and models.
Same Pre-training Loss, Better Downstream: Implicit Bias Matters for Language Models
Oct 25, 2022



Language modeling on large-scale datasets leads to impressive performance gains on various downstream language tasks. The validation pre-training loss (or perplexity in autoregressive language modeling) is often used as the evaluation metric when developing language models since the pre-training loss tends to be well-correlated with downstream performance (which is itself difficult to evaluate comprehensively). Contrary to this conventional wisdom, this paper shows that 1) pre-training loss cannot fully explain downstream performance and 2) flatness of the model is well-correlated with downstream performance where pre-training loss is not. On simplified datasets, we identify three ways to produce models with the same (statistically optimal) pre-training loss but different downstream performance: continue pre-training after convergence, increasing the model size, and changing the training algorithm. These experiments demonstrate the existence of implicit bias of pre-training algorithms/optimizers -- among models with the same minimal pre-training loss, they implicitly prefer more transferable ones. Toward understanding this implicit bias, we prove that SGD with standard mini-batch noise implicitly prefers flatter minima in language models, and empirically observe a strong correlation between flatness and downstream performance among models with the same minimal pre-training loss. We also prove in a synthetic language setting that among the models with the minimal pre-training loss, the flattest model transfers to downstream tasks.