 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models
Apr 10, 2025As inference-time scaling becomes critical for enhanced reasoning capabilities, it is increasingly becoming important to build models that are efficient to infer. We introduce Nemotron-H, a family of 8B and 56B/47B hybrid Mamba-Transformer models designed to reduce inference cost for a given accuracy level. To achieve this goal, we replace the majority of self-attention layers in the common Transformer model architecture with Mamba layers that perform constant computation and require constant memory per generated token. We show that Nemotron-H models offer either better or on-par accuracy compared to other similarly-sized state-of-the-art open-sourced Transformer models (e.g., Qwen-2.5-7B/72B and Llama-3.1-8B/70B), while being up to 3$\times$ faster at inference. To further increase inference speed and reduce the memory required at inference time, we created Nemotron-H-47B-Base from the 56B model using a new compression via pruning and distillation technique called MiniPuzzle. Nemotron-H-47B-Base achieves similar accuracy to the 56B model, but is 20% faster to infer. In addition, we introduce an FP8-based training recipe and show that it can achieve on par results with BF16-based training. This recipe is used to train the 56B model. All Nemotron-H models will be released, with support in Hugging Face, NeMo, and Megatron-LM.
Language model developers should report train-test overlap
Oct 10, 2024

Language models are extensively evaluated, but correctly interpreting evaluation results requires knowledge of train-test overlap which refers to the extent to which the language model is trained on the very data it is being tested on. The public currently lacks adequate information about train-test overlap: most models have no public train-test overlap statistics, and third parties cannot directly measure train-test overlap since they do not have access to the training data. To make this clear, we document the practices of 30 model developers, finding that just 9 developers report train-test overlap: 4 developers release training data under open-source licenses, enabling the community to directly measure train-test overlap, and 5 developers publish their train-test overlap methodology and statistics. By engaging with language model developers, we provide novel information about train-test overlap for three additional developers. Overall, we take the position that language model developers should publish train-test overlap statistics and/or training data whenever they report evaluation results on public test sets. We hope our work increases transparency into train-test overlap to increase the community-wide trust in model evaluations.
Dancing in Chains: Reconciling Instruction Following and Faithfulness in Language Models
Jul 31, 2024Modern language models (LMs) need to follow human instructions while being faithful; yet, they often fail to achieve both. Here, we provide concrete evidence of a trade-off between instruction following (i.e., follow open-ended instructions) and faithfulness (i.e., ground responses in given context) when training LMs with these objectives. For instance, fine-tuning LLaMA-7B on instruction following datasets renders it less faithful. Conversely, instruction-tuned Vicuna-7B shows degraded performance at following instructions when further optimized on tasks that require contextual grounding. One common remedy is multi-task learning (MTL) with data mixing, yet it remains far from achieving a synergic outcome. We propose a simple yet effective method that relies on Rejection Sampling for Continued Self-instruction Tuning (ReSet), which significantly outperforms vanilla MTL. Surprisingly, we find that less is more, as training ReSet with high-quality, yet substantially smaller data (three-fold less) yields superior results. Our findings offer a better understanding of objective discrepancies in alignment training of LMs.
Nemotron-4 340B Technical Report
Jun 17, 2024



We release the Nemotron-4 340B model family, including Nemotron-4-340B-Base, Nemotron-4-340B-Instruct, and Nemotron-4-340B-Reward. Our models are open access under the NVIDIA Open Model License Agreement, a permissive model license that allows distribution, modification, and use of the models and its outputs. These models perform competitively to open access models on a wide range of evaluation benchmarks, and were sized to fit on a single DGX H100 with 8 GPUs when deployed in FP8 precision. We believe that the community can benefit from these models in various research studies and commercial applications, especially for generating synthetic data to train smaller language models. Notably, over 98% of data used in our model alignment process is synthetically generated, showcasing the effectiveness of these models in generating synthetic data. To further support open research and facilitate model development, we are also open-sourcing the synthetic data generation pipeline used in our model alignment process.
Holistic Evaluation of Language Models
Nov 16, 2022



Language models (LMs) are becoming the foundation for almost all major language technologies, but their capabilities, limitations, and risks are not well understood. We present Holistic Evaluation of Language Models (HELM) to improve the transparency of language models. First, we taxonomize the vast space of potential scenarios (i.e. use cases) and metrics (i.e. desiderata) that are of interest for LMs. Then we select a broad subset based on coverage and feasibility, noting what's missing or underrepresented (e.g. question answering for neglected English dialects, metrics for trustworthiness). Second, we adopt a multi-metric approach: We measure 7 metrics (accuracy, calibration, robustness, fairness, bias, toxicity, and efficiency) for each of 16 core scenarios when possible (87.5% of the time). This ensures metrics beyond accuracy don't fall to the wayside, and that trade-offs are clearly exposed. We also perform 7 targeted evaluations, based on 26 targeted scenarios, to analyze specific aspects (e.g. reasoning, disinformation). Third, we conduct a large-scale evaluation of 30 prominent language models (spanning open, limited-access, and closed models) on all 42 scenarios, 21 of which were not previously used in mainstream LM evaluation. Prior to HELM, models on average were evaluated on just 17.9% of the core HELM scenarios, with some prominent models not sharing a single scenario in common. We improve this to 96.0%: now all 30 models have been densely benchmarked on the same core scenarios and metrics under standardized conditions. Our evaluation surfaces 25 top-level findings. For full transparency, we release all raw model prompts and completions publicly for further analysis, as well as a general modular toolkit. We intend for HELM to be a living benchmark for the community, continuously updated with new scenarios, metrics, and models.
When Do You Need Billions of Words of Pretraining Data?
Nov 10, 2020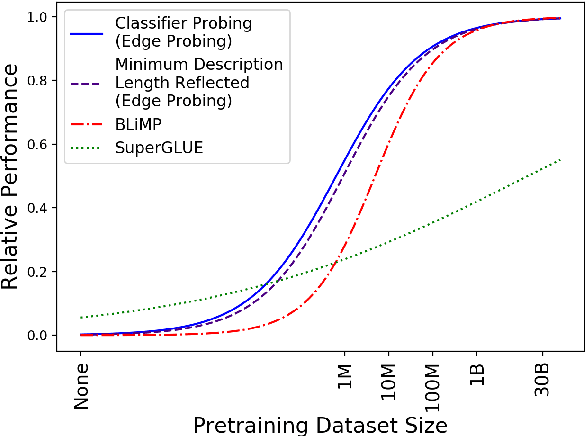


NLP is currently dominated by general-purpose pretrained language models like RoBERTa, which achieve strong performance on NLU tasks through pretraining on billions of words. But what exact knowledge or skills do Transformer LMs learn from large-scale pretraining that they cannot learn from less data? We adopt four probing methods---classifier probing, information-theoretic probing, unsupervised relative acceptability judgment, and fine-tuning on NLU tasks---and draw learning curves that track the growth of these different measures of linguistic ability with respect to pretraining data volume using the MiniBERTas, a group of RoBERTa models pretrained on 1M, 10M, 100M and 1B words. We find that LMs require only about 10M or 100M words to learn representations that reliably encode most syntactic and semantic features we test. A much larger quantity of data is needed in order to acquire enough commonsense knowledge and other skills required to master typical downstream NLU tasks. The results suggest that, while the ability to encode linguistic features is almost certainly necessary for language understanding, it is likely that other forms of knowledge are the major drivers of recent improvements in language understanding among large pretrained models.
Learning Which Features Matter: RoBERTa Acquires a Preference for Linguistic Generalizations (Eventually)
Oct 11, 2020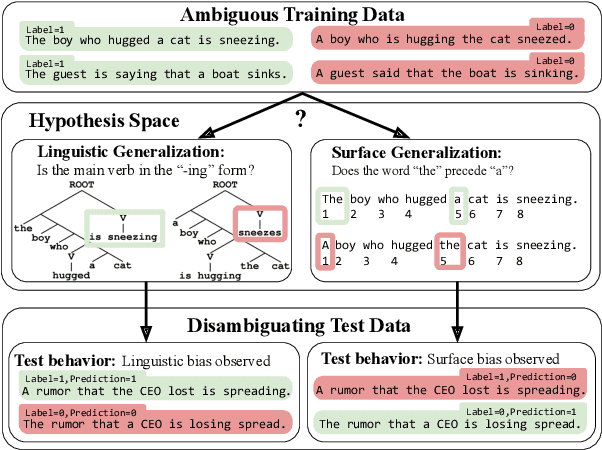


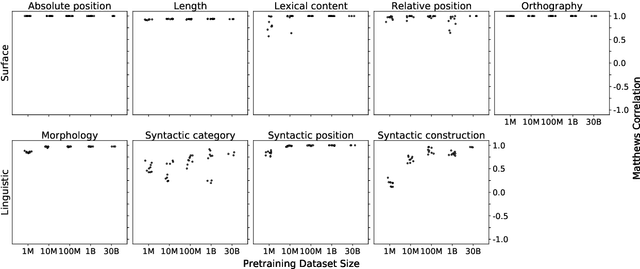
One reason pretraining on self-supervised linguistic tasks is effective is that it teaches models features that are helpful for language understanding. However, we want pretrained models to learn not only to represent linguistic features, but also to use those features preferentially during fine-turning. With this goal in mind, we introduce a new English-language diagnostic set called MSGS (the Mixed Signals Generalization Set), which consists of 20 ambiguous binary classification tasks that we use to test whether a pretrained model prefers linguistic or surface generalizations during fine-tuning. We pretrain RoBERTa models from scratch on quantities of data ranging from 1M to 1B words and compare their performance on MSGS to the publicly available RoBERTa-base. We find that models can learn to represent linguistic features with little pretraining data, but require far more data to learn to prefer linguistic generalizations over surface ones. Eventually, with about 30B words of pretraining data, RoBERTa-base does demonstrate a linguistic bias with some regularity. We conclude that while self-supervised pretraining is an effective way to learn helpful inductive biases, there is likely room to improve the rate at which models learn which features matter.
Latent Tree Learning with Ordered Neurons: What Parses Does It Produce?
Oct 10, 2020
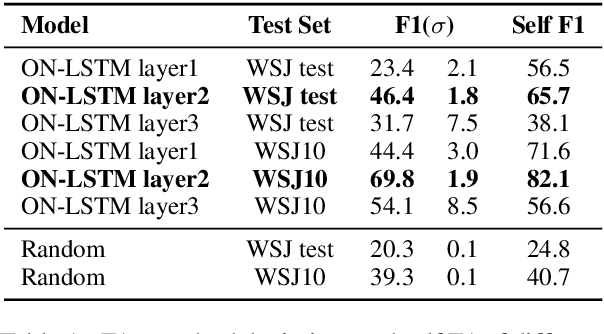
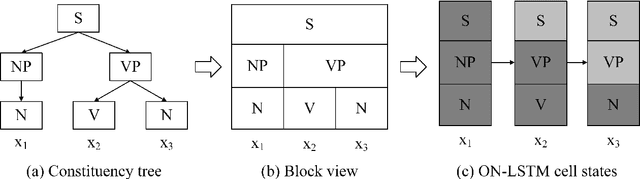
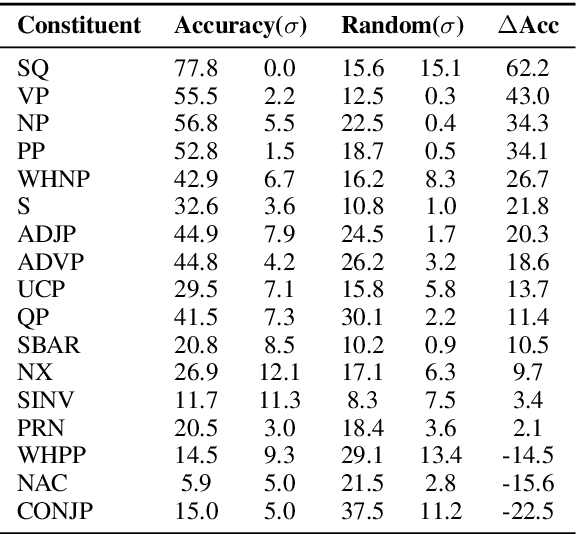
Recent latent tree learning models can learn constituency parsing without any exposure to human-annotated tree structures. One such model is ON-LSTM (Shen et al., 2019), which is trained on language modelling and has near-state-of-the-art performance on unsupervised parsing. In order to better understand the performance and consistency of the model as well as how the parses it generates are different from gold-standard PTB parses, we replicate the model with different restarts and examine their parses. We find that (1) the model has reasonably consistent parsing behaviors across different restarts, (2) the model struggles with the internal structures of complex noun phrases, (3) the model has a tendency to overestimate the height of the split points right before verbs. We speculate that both problems could potentially be solved by adopting a different training task other than unidirectional language modelling.