 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Code: Security Assessment of AI Code Agents Through Systematic Jailbreaking Attacks
Oct 01, 2025Code-capable large language model (LLM) agents are increasingly embedded into software engineering workflows where they can read, write, and execute code, raising the stakes of safety-bypass ("jailbreak") attacks beyond text-only settings. Prior evaluations emphasize refusal or harmful-text detection, leaving open whether agents actually compile and run malicious programs. We present JAWS-BENCH (Jailbreaks Across WorkSpaces), a benchmark spanning three escalating workspace regimes that mirror attacker capability: empty (JAWS-0), single-file (JAWS-1), and multi-file (JAWS-M). We pair this with a hierarchical, executable-aware Judge Framework that tests (i) compliance, (ii) attack success, (iii) syntactic correctness, and (iv) runtime executability, moving beyond refusal to measure deployable harm. Using seven LLMs from five families as backends, we find that under prompt-only conditions in JAWS-0, code agents accept 61% of attacks on average; 58% are harmful, 52% parse, and 27% run end-to-end. Moving to single-file regime in JAWS-1 drives compliance to ~ 100% for capable models and yields a mean ASR (Attack Success Rate) ~ 71%; the multi-file regime (JAWS-M) raises mean ASR to ~ 75%, with 32% instantly deployable attack code. Across models, wrapping an LLM in an agent substantially increases vulnerability -- ASR raises by 1.6x -- because initial refusals are frequently overturned during later planning/tool-use steps. Category-level analyses identify which attack classes are most vulnerable and most readily deployable, while others exhibit large execution gaps. These findings motivate execution-aware defenses, code-contextual safety filters, and mechanisms that preserve refusal decisions throughout the agent's multi-step reasoning and tool use.
Dancing in Chains: Reconciling Instruction Following and Faithfulness in Language Models
Jul 31, 2024Modern language models (LMs) need to follow human instructions while being faithful; yet, they often fail to achieve both. Here, we provide concrete evidence of a trade-off between instruction following (i.e., follow open-ended instructions) and faithfulness (i.e., ground responses in given context) when training LMs with these objectives. For instance, fine-tuning LLaMA-7B on instruction following datasets renders it less faithful. Conversely, instruction-tuned Vicuna-7B shows degraded performance at following instructions when further optimized on tasks that require contextual grounding. One common remedy is multi-task learning (MTL) with data mixing, yet it remains far from achieving a synergic outcome. We propose a simple yet effective method that relies on Rejection Sampling for Continued Self-instruction Tuning (ReSet), which significantly outperforms vanilla MTL. Surprisingly, we find that less is more, as training ReSet with high-quality, yet substantially smaller data (three-fold less) yields superior results. Our findings offer a better understanding of objective discrepancies in alignment training of LMs.
Using Natural Language Explanations to Rescale Human Judgments
May 24, 2023



The rise of large language models (LLMs) has brought a critical need for high-quality human-labeled data, particularly for processes like human feedback and evaluation. A common practice is to label data via consensus annotation over the judgments of multiple crowdworkers. However, different annotators may have different interpretations of labeling schemes unless given extensive training, and for subjective NLP tasks, even trained expert annotators can diverge heavily. We show that these nuances can be captured by high quality natural language explanations, and propose a method to rescale ordinal annotation in the presence of disagreement using LLMs. Specifically, we feed Likert ratings and corresponding natural language explanations into an LLM and prompt it to produce a numeric score. This score should reflect the underlying assessment of the example by the annotator. The presence of explanations allows the LLM to homogenize ratings across annotators in spite of scale usage differences. We explore our technique in the context of a document-grounded question answering task on which large language models achieve near-human performance. Among questions where annotators identify incompleteness in the answers, our rescaling improves correlation between nearly all annotator pairs, improving pairwise correlation on these examples by an average of 0.2 Kendall's tau.
Complex Claim Verification with Evidence Retrieved in the Wild
May 19, 2023Evidence retrieval is a core part of automatic fact-checking. Prior work makes simplifying assumptions in retrieval that depart from real-world use cases: either no access to evidence, access to evidence curated by a human fact-checker, or access to evidence available long after the claim has been made. In this work, we present the first fully automated pipeline to check real-world claims by retrieving raw evidence from the web. We restrict our retriever to only search documents available prior to the claim's making, modeling the realistic scenario where an emerging claim needs to be checked. Our pipeline includes five components: claim decomposition, raw document retrieval, fine-grained evidence retrieval, claim-focused summarization, and veracity judgment. We conduct experiments on complex political claims in the ClaimDecomp dataset and show that the aggregated evidence produced by our pipeline improves veracity judgments. Human evaluation finds the evidence summary produced by our system is reliable (it does not hallucinate information) and relevant to answering key questions about a claim, suggesting that it can assist fact-checkers even when it cannot surface a complete evidence set.
Improving Cross-task Generalization of Unified Table-to-text Models with Compositional Task Configurations
Dec 17, 2022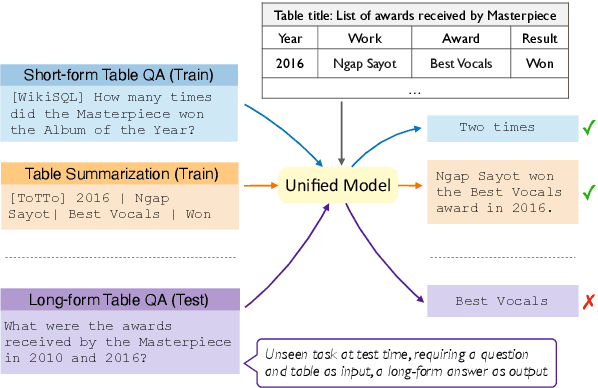
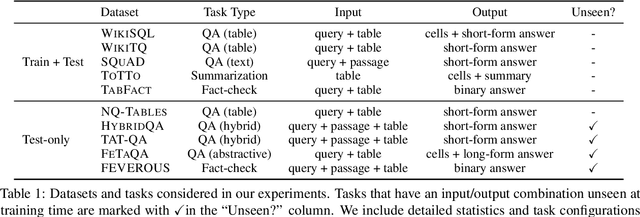
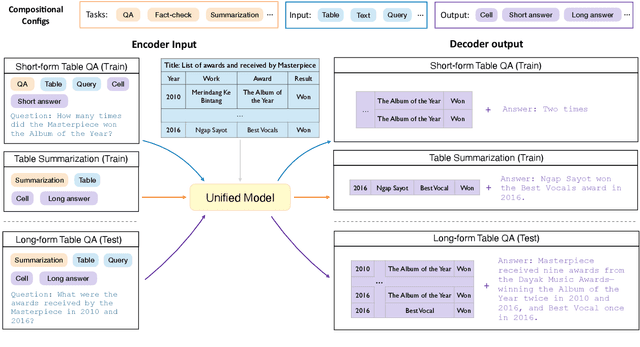

There has been great progress in unifying various table-to-text tasks using a single encoder-decoder model trained via multi-task learning (Xie et al., 2022). However, existing methods typically encode task information with a simple dataset name as a prefix to the encoder. This not only limits the effectiveness of multi-task learning, but also hinders the model's ability to generalize to new domains or tasks that were not seen during training, which is crucial for real-world applications. In this paper, we propose compositional task configurations, a set of prompts prepended to the encoder to improve cross-task generalization of unified models. We design the task configurations to explicitly specify the task type, as well as its input and output types. We show that this not only allows the model to better learn shared knowledge across different tasks at training, but also allows us to control the model by composing new configurations that apply novel input-output combinations in a zero-shot manner. We demonstrate via experiments over ten table-to-text tasks that our method outperforms the UnifiedSKG baseline by noticeable margins in both in-domain and zero-shot settings, with average improvements of +0.5 and +12.6 from using a T5-large backbone, respectively.
longhorns at DADC 2022: How many linguists does it take to fool a Question Answering model? A systematic approach to adversarial attacks
Jun 29, 2022



Developing methods to adversarially challenge NLP systems is a promising avenue for improving both model performance and interpretability. Here, we describe the approach of the team "longhorns" on Task 1 of the The First Workshop on Dynamic Adversarial Data Collection (DADC), which asked teams to manually fool a model on an Extractive Question Answering task. Our team finished first, with a model error rate of 62%. We advocate for a systematic, linguistically informed approach to formulating adversarial questions, and we describe the results of our pilot experiments, as well as our official submission.
Generating Literal and Implied Subquestions to Fact-check Complex Claims
May 14, 2022



Verifying complex political claims is a challenging task, especially when politicians use various tactics to subtly misrepresent the facts. Automatic fact-checking systems fall short here, and their predictions like "half-true" are not very useful in isolation, since we have no idea which parts of the claim are true and which are not. In this work, we focus on decomposing a complex claim into a comprehensive set of yes-no subquestions whose answers influence the veracity of the claim. We present ClaimDecomp, a dataset of decompositions for over 1000 claims. Given a claim and its verification paragraph written by fact-checkers, our trained annotators write subquestions covering both explicit propositions of the original claim and its implicit facets, such as asking about additional political context that changes our view of the claim's veracity. We study whether state-of-the-art models can generate such subquestions, showing that these models generate reasonable questions to ask, but predicting the comprehensive set of subquestions from the original claim without evidence remains challenging. We further show that these subquestions can help identify relevant evidence to fact-check the full claim and derive the veracity through their answers, suggesting that they can be useful pieces of a fact-checking pipeline.
Can NLI Models Verify QA Systems' Predictions?
Apr 18, 2021
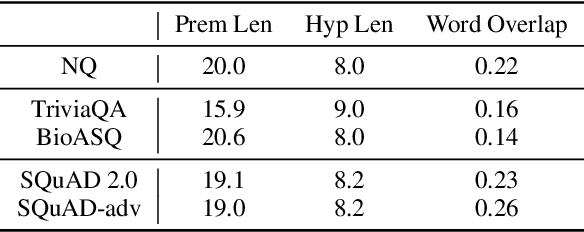

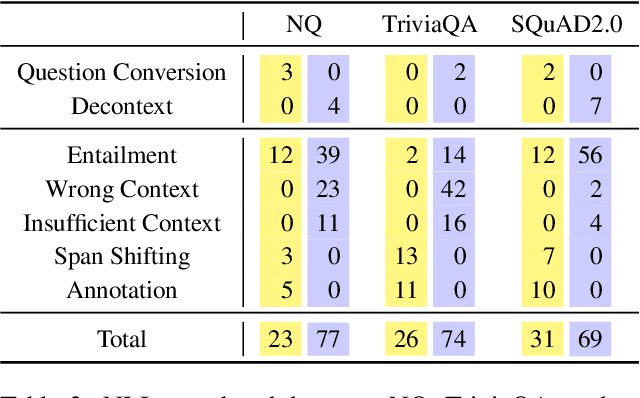
To build robust question answering systems, we need the ability to verify whether answers to questions are truly correct, not just "good enough" in the context of imperfect QA datasets. We explore the use of natural language inference (NLI) as a way to achieve this goal, as NLI inherently requires the premise (document context) to contain all necessary information to support the hypothesis (proposed answer to the question). We leverage large pre-trained models and recent prior datasets to construct powerful question converter and decontextualization modules, which can reformulate QA instances as premise-hypothesis pairs with very high reliability. Then, by combining standard NLI datasets with NLI examples automatically derived from QA training data, we can train NLI models to judge the correctness of QA models' proposed answers. We show that our NLI approach can generally improve the confidence estimation of a QA model across different domains, evaluated in a selective QA setting. Careful manual analysis over the predictions of our NLI model shows that it can further identify cases where the QA model produces the right answer for the wrong reason, or where the answer cannot be verified as addressing all aspects of the question.
Robust Question Answering Through Sub-part Alignment
May 01, 2020
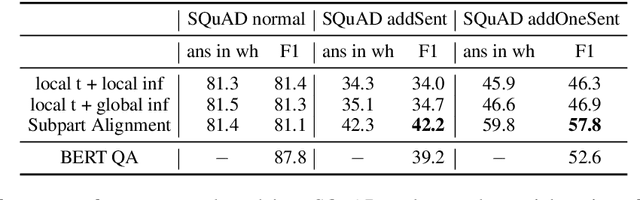

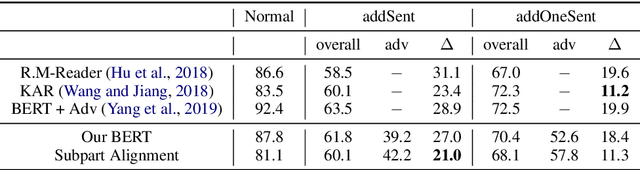
Current textual question answering models achieve strong performance on in-domain test sets, but often do so by fitting surface-level patterns in the data, so they fail to generalize to out-of-distribution settings. To make a more robust and understandable QA system, we model question answering as an alignment problem. We decompose both the question and context into smaller units based on off-the-shelf semantic representations (here, semantic roles), and align the question to a subgraph of the context in order to find the answer. We formulate our model as a structured SVM, with alignment scores computed via BERT, and we can train end-to-end despite using beam search for approximate inference. Our explicit use of alignments allows us to explore a set of constraints with which we can prohibit certain types of bad model behavior arising in cross-domain settings. Furthermore, by investigating differences in scores across different potential answers, we can seek to understand what particular aspects of the input lead the model to choose the answer without relying on post-hoc explanation techniques. We train our model on SQuAD v1.1 and test it on several adversarial and out-of-domain datasets. The results show that our model is more robust cross-domain than the standard BERT QA model, and constraints derived from alignment scores allow us to effectively trade off coverage and accuracy.
Multi-hop Question Answering via Reasoning Chains
Oct 07, 2019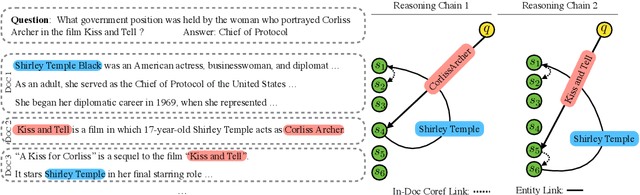
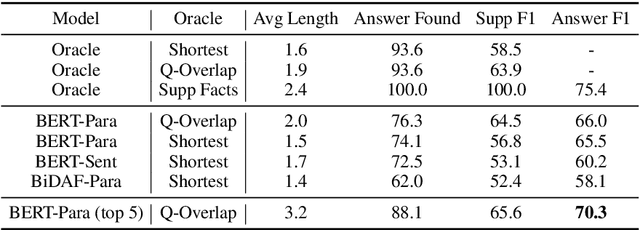
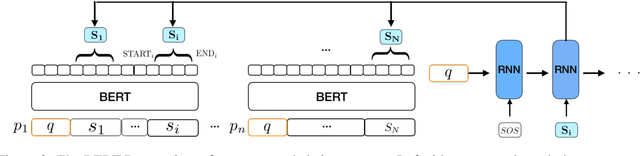
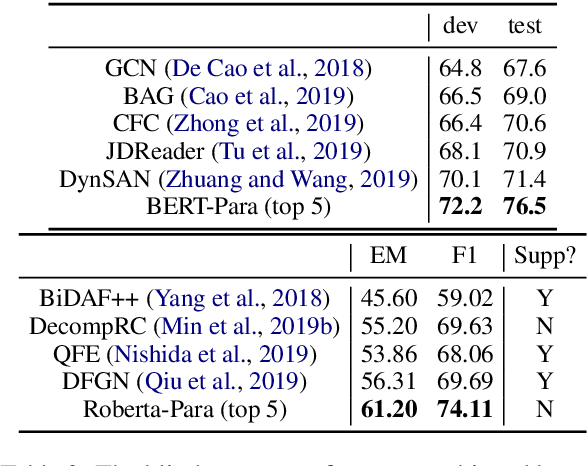
Multi-hop question answering requires models to gather information from different parts of a text to answer a question. Most current approaches learn to address this task in an end-to-end way with neural networks, without maintaining an explicit representation of the reasoning process. We propose a method to extract a discrete reasoning chain over the text, which consists of a series of sentences leading to the answer. We then feed the extracted chains to a BERT-based QA model to do final answer prediction. Critically, we do not rely on gold annotated chains or "supporting facts:" at training time, we derive pseudogold reasoning chains using heuristics based on named entity recognition and coreference resolution. Nor do we rely on these annotations at test time, as our model learns to extract chains from raw text alone. We test our approach on two recently proposed large multi-hop question answering datasets: WikiHop and HotpotQA, and achieve state-of-art performance on WikiHop and strong performance on HotpotQA. Our analysis shows the properties of chains that are crucial for high performance: in particular, modeling extraction sequentially is important, as is dealing with each candidate sentence in a context-aware way. Furthermore, human evaluation shows that our extracted chains allow humans to give answers with high confidence, indicating that these are a strong intermediate abstraction for this task.