 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRankAlign: A Ranking View of the Generator-Validator Gap in Large Language Models
Apr 15, 2025



Although large language models (LLMs) have become generally more capable and accurate across many tasks, some fundamental sources of unreliability remain in their behavior. One key limitation is their inconsistency at reporting the the same information when prompts are changed. In this paper, we consider the discrepancy between a model's generated answer and their own verification of that answer, the generator-validator gap. We define this gap in a more stringent way than prior work: we expect correlation of scores from a generator and a validator over the entire set of candidate answers. We show that according to this measure, a large gap exists in various settings, including question answering, lexical semantics tasks, and next-word prediction. We then propose RankAlign, a ranking-based training method, and show that it significantly closes the gap by 31.8% on average, surpassing all baseline methods. Moreover, this approach generalizes well to out-of-domain tasks and lexical items.
The Emergence of Grammar through Reinforcement Learning
Mar 03, 2025The evolution of grammatical systems of syntactic and semantic composition is modeled here with a novel application of reinforcement learning theory. To test the functionalist thesis that speakers' expressive purposes shape their language, we include within the model a probability distribution over different messages that could be expressed in a given context. The proposed learning and production algorithm then breaks down language learning into a sequence of simple steps, such that each step benefits from the message probabilities. The results are presented in the form of numerical simulations of language histories and analytic proofs. The potential for applying these mathematical models to the study of natural language is illustrated with two case studies from the history of English.
SAGA: A Participant-specific Examination of Story Alternatives and Goal Applicability for a Deeper Understanding of Complex Events
Aug 11, 2024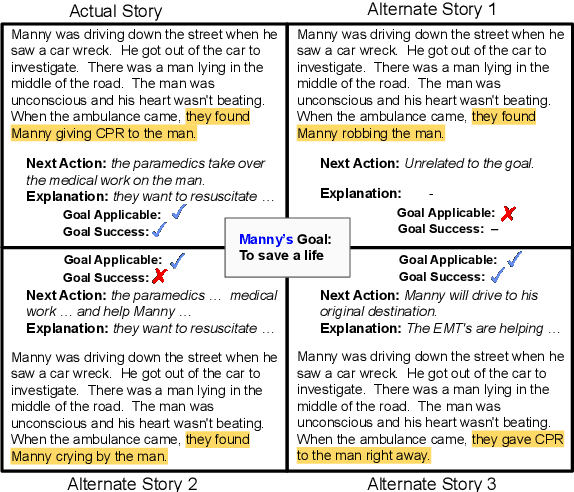

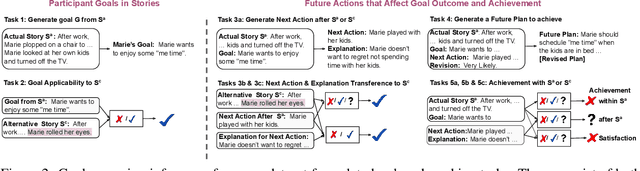
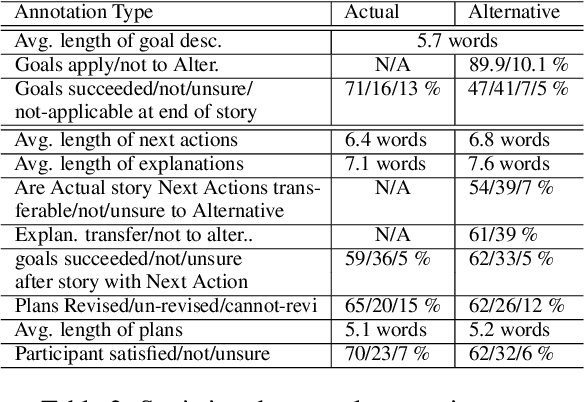
Interpreting and assessing goal driven actions is vital to understanding and reasoning over complex events. It is important to be able to acquire the knowledge needed for this understanding, though doing so is challenging. We argue that such knowledge can be elicited through a participant achievement lens. We analyze a complex event in a narrative according to the intended achievements of the participants in that narrative, the likely future actions of the participants, and the likelihood of goal success. We collect 6.3K high quality goal and action annotations reflecting our proposed participant achievement lens, with an average weighted Fleiss-Kappa IAA of 80%. Our collection contains annotated alternate versions of each narrative. These alternate versions vary minimally from the "original" story, but can license drastically different inferences. Our findings suggest that while modern large language models can reflect some of the goal-based knowledge we study, they find it challenging to fully capture the design and intent behind concerted actions, even when the model pretraining included the data from which we extracted the goal knowledge. We show that smaller models fine-tuned on our dataset can achieve performance surpassing larger models.
Adjusting Interpretable Dimensions in Embedding Space with Human Judgments
Apr 03, 2024Embedding spaces contain interpretable dimensions indicating gender, formality in style, or even object properties. This has been observed multiple times. Such interpretable dimensions are becoming valuable tools in different areas of study, from social science to neuroscience. The standard way to compute these dimensions uses contrasting seed words and computes difference vectors over them. This is simple but does not always work well. We combine seed-based vectors with guidance from human ratings of where words fall along a specific dimension, and evaluate on predicting both object properties like size and danger, and the stylistic properties of formality and complexity. We obtain interpretable dimensions with markedly better performance especially in cases where seed-based dimensions do not work well.
X-PARADE: Cross-Lingual Textual Entailment and Information Divergence across Paragraphs
Sep 16, 2023



Understanding when two pieces of text convey the same information is a goal touching many subproblems in NLP, including textual entailment and fact-checking. This problem becomes more complex when those two pieces of text are in different languages. Here, we introduce X-PARADE (Cross-lingual Paragraph-level Analysis of Divergences and Entailments), the first cross-lingual dataset of paragraph-level information divergences. Annotators label a paragraph in a target language at the span level and evaluate it with respect to a corresponding paragraph in a source language, indicating whether a given piece of information is the same, new, or new but can be inferred. This last notion establishes a link with cross-language NLI. Aligned paragraphs are sourced from Wikipedia pages in different languages, reflecting real information divergences observed in the wild. Armed with our dataset, we investigate a diverse set of approaches for this problem, including classic token alignment from machine translation, textual entailment methods that localize their decisions, and prompting of large language models. Our results show that these methods vary in their capability to handle inferable information, but they all fall short of human performance.
A Method for Studying Semantic Construal in Grammatical Constructions with Interpretable Contextual Embedding Spaces
May 29, 2023



We study semantic construal in grammatical constructions using large language models. First, we project contextual word embeddings into three interpretable semantic spaces, each defined by a different set of psycholinguistic feature norms. We validate these interpretable spaces and then use them to automatically derive semantic characterizations of lexical items in two grammatical constructions: nouns in subject or object position within the same sentence, and the AANN construction (e.g., `a beautiful three days'). We show that a word in subject position is interpreted as more agentive than the very same word in object position, and that the nouns in the AANN construction are interpreted as more measurement-like than when in the canonical alternation. Our method can probe the distributional meaning of syntactic constructions at a templatic level, abstracted away from specific lexemes.
POQue: Asking Participant-specific Outcome Questions for a Deeper Understanding of Complex Events
Dec 05, 2022



Knowledge about outcomes is critical for complex event understanding but is hard to acquire. We show that by pre-identifying a participant in a complex event, crowd workers are able to (1) infer the collective impact of salient events that make up the situation, (2) annotate the volitional engagement of participants in causing the situation, and (3) ground the outcome of the situation in state changes of the participants. By creating a multi-step interface and a careful quality control strategy, we collect a high quality annotated dataset of 8K short newswire narratives and ROCStories with high inter-annotator agreement (0.74-0.96 weighted Fleiss Kappa). Our dataset, POQue (Participant Outcome Questions), enables the exploration and development of models that address multiple aspects of semantic understanding. Experimentally, we show that current language models lag behind human performance in subtle ways through our task formulations that target abstract and specific comprehension of a complex event, its outcome, and a participant's influence over the event culmination.
longhorns at DADC 2022: How many linguists does it take to fool a Question Answering model? A systematic approach to adversarial attacks
Jun 29, 2022



Developing methods to adversarially challenge NLP systems is a promising avenue for improving both model performance and interpretability. Here, we describe the approach of the team "longhorns" on Task 1 of the The First Workshop on Dynamic Adversarial Data Collection (DADC), which asked teams to manually fool a model on an Extractive Question Answering task. Our team finished first, with a model error rate of 62%. We advocate for a systematic, linguistically informed approach to formulating adversarial questions, and we describe the results of our pilot experiments, as well as our official submission.
Did they answer? Subjective acts and intents in conversational discourse
Apr 09, 2021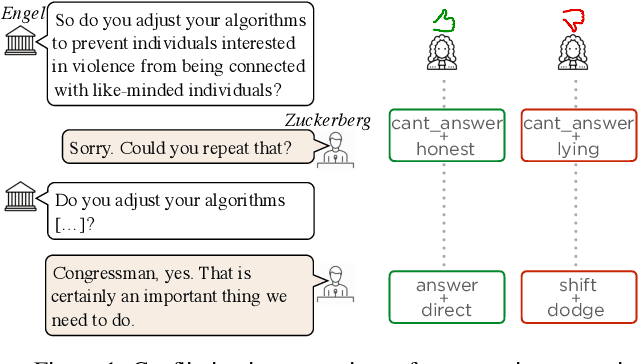
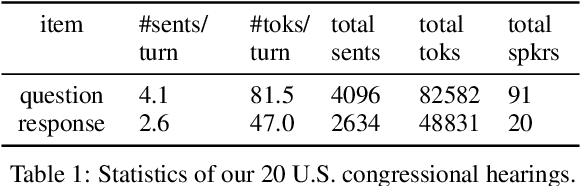

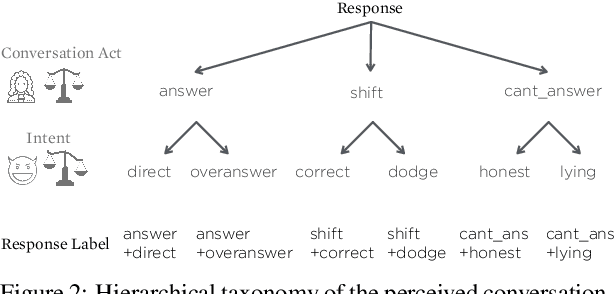
Discourse signals are often implicit, leaving it up to the interpreter to draw the required inferences. At the same time, discourse is embedded in a social context, meaning that interpreters apply their own assumptions and beliefs when resolving these inferences, leading to multiple, valid interpretations. However, current discourse data and frameworks ignore the social aspect, expecting only a single ground truth. We present the first discourse dataset with multiple and subjective interpretations of English conversation in the form of perceived conversation acts and intents. We carefully analyze our dataset and create computational models to (1) confirm our hypothesis that taking into account the bias of the interpreters leads to better predictions of the interpretations, (2) and show disagreements are nuanced and require a deeper understanding of the different contextual factors. We share our dataset and code at http://github.com/elisaF/subjective_discourse.
Help! Need Advice on Identifying Advice
Oct 06, 2020
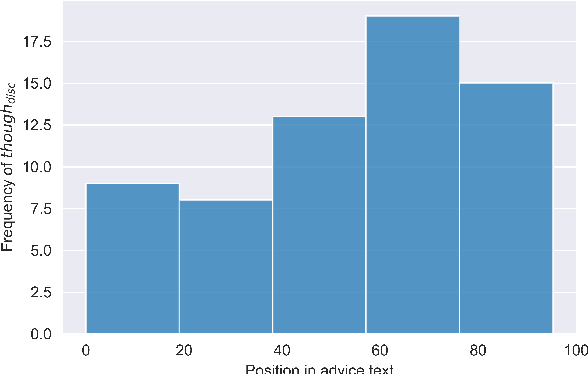


Humans use language to accomplish a wide variety of tasks - asking for and giving advice being one of them. In online advice forums, advice is mixed in with non-advice, like emotional support, and is sometimes stated explicitly, sometimes implicitly. Understanding the language of advice would equip systems with a better grasp of language pragmatics; practically, the ability to identify advice would drastically increase the efficiency of advice-seeking online, as well as advice-giving in natural language generation systems. We present a dataset in English from two Reddit advice forums - r/AskParents and r/needadvice - annotated for whether sentences in posts contain advice or not. Our analysis reveals rich linguistic phenomena in advice discourse. We present preliminary models showing that while pre-trained language models are able to capture advice better than rule-based systems, advice identification is challenging, and we identify directions for future research. Comments: To be presented at EMNLP 2020.