 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChartMuseum: Testing Visual Reasoning Capabilities of Large Vision-Language Models
May 19, 2025Chart understanding presents a unique challenge for large vision-language models (LVLMs), as it requires the integration of sophisticated textual and visual reasoning capabilities. However, current LVLMs exhibit a notable imbalance between these skills, falling short on visual reasoning that is difficult to perform in text. We conduct a case study using a synthetic dataset solvable only through visual reasoning and show that model performance degrades significantly with increasing visual complexity, while human performance remains robust. We then introduce ChartMuseum, a new Chart Question Answering (QA) benchmark containing 1,162 expert-annotated questions spanning multiple reasoning types, curated from real-world charts across 184 sources, specifically built to evaluate complex visual and textual reasoning. Unlike prior chart understanding benchmarks -- where frontier models perform similarly and near saturation -- our benchmark exposes a substantial gap between model and human performance, while effectively differentiating model capabilities: although humans achieve 93% accuracy, the best-performing model Gemini-2.5-Pro attains only 63.0%, and the leading open-source LVLM Qwen2.5-VL-72B-Instruct achieves only 38.5%. Moreover, on questions requiring primarily visual reasoning, all models experience a 35%-55% performance drop from text-reasoning-heavy question performance. Lastly, our qualitative error analysis reveals specific categories of visual reasoning that are challenging for current LVLMs.
KRISTEVA: Close Reading as a Novel Task for Benchmarking Interpretive Reasoning
May 14, 2025Each year, tens of millions of essays are written and graded in college-level English courses. Students are asked to analyze literary and cultural texts through a process known as close reading, in which they gather textual details to formulate evidence-based arguments. Despite being viewed as a basis for critical thinking and widely adopted as a required element of university coursework, close reading has never been evaluated on large language models (LLMs), and multi-discipline benchmarks like MMLU do not include literature as a subject. To fill this gap, we present KRISTEVA, the first close reading benchmark for evaluating interpretive reasoning, consisting of 1331 multiple-choice questions adapted from classroom data. With KRISTEVA, we propose three progressively more difficult sets of tasks to approximate different elements of the close reading process, which we use to test how well LLMs may seem to understand and reason about literary works: 1) extracting stylistic features, 2) retrieving relevant contextual information from parametric knowledge, and 3) multi-hop reasoning between style and external contexts. Our baseline results find that, while state-of-the-art LLMs possess some college-level close reading competency (accuracy 49.7% - 69.7%), their performances still trail those of experienced human evaluators on 10 out of our 11 tasks.
RankAlign: A Ranking View of the Generator-Validator Gap in Large Language Models
Apr 15, 2025



Although large language models (LLMs) have become generally more capable and accurate across many tasks, some fundamental sources of unreliability remain in their behavior. One key limitation is their inconsistency at reporting the the same information when prompts are changed. In this paper, we consider the discrepancy between a model's generated answer and their own verification of that answer, the generator-validator gap. We define this gap in a more stringent way than prior work: we expect correlation of scores from a generator and a validator over the entire set of candidate answers. We show that according to this measure, a large gap exists in various settings, including question answering, lexical semantics tasks, and next-word prediction. We then propose RankAlign, a ranking-based training method, and show that it significantly closes the gap by 31.8% on average, surpassing all baseline methods. Moreover, this approach generalizes well to out-of-domain tasks and lexical items.
Parameterized Synthetic Text Generation with SimpleStories
Apr 12, 2025We present SimpleStories, a large synthetic story dataset in simple language, consisting of 2 million stories each in English and Japanese. Our method employs parametrization of prompts with features at multiple levels of abstraction, allowing for systematic control over story characteristics to ensure broad syntactic and semantic diversity. Building on and addressing limitations in the TinyStories dataset, our approach demonstrates that simplicity and variety can be achieved simultaneously in synthetic text generation at scale.
Characterizing the Role of Similarity in the Property Inferences of Language Models
Oct 29, 2024



Property inheritance -- a phenomenon where novel properties are projected from higher level categories (e.g., birds) to lower level ones (e.g., sparrows) -- provides a unique window into how humans organize and deploy conceptual knowledge. It is debated whether this ability arises due to explicitly stored taxonomic knowledge vs. simple computations of similarity between mental representations. How are these mechanistic hypotheses manifested in contemporary language models? In this work, we investigate how LMs perform property inheritance with behavioral and causal representational analysis experiments. We find that taxonomy and categorical similarities are not mutually exclusive in LMs' property inheritance behavior. That is, LMs are more likely to project novel properties from one category to the other when they are taxonomically related and at the same time, highly similar. Our findings provide insight into the conceptual structure of language models and may suggest new psycholinguistic experiments for human subjects.
To CoT or not to CoT? Chain-of-thought helps mainly on math and symbolic reasoning
Sep 18, 2024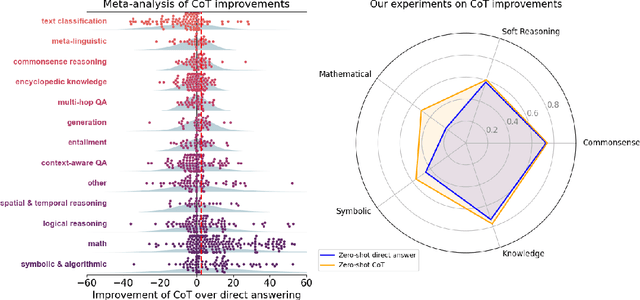


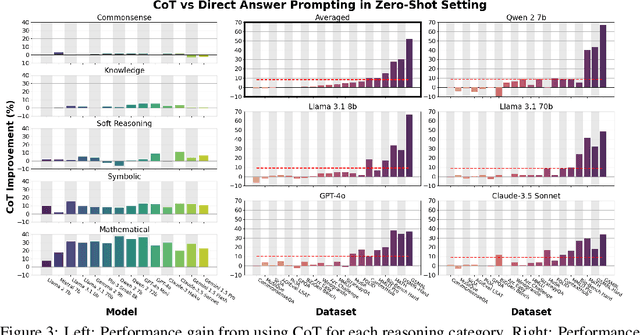
Chain-of-thought (CoT) via prompting is the de facto method for eliciting reasoning capabilities from large language models (LLMs). But for what kinds of tasks is this extra ``thinking'' really helpful? To analyze this, we conducted a quantitative meta-analysis covering over 100 papers using CoT and ran our own evaluations of 20 datasets across 14 models. Our results show that CoT gives strong performance benefits primarily on tasks involving math or logic, with much smaller gains on other types of tasks. On MMLU, directly generating the answer without CoT leads to almost identical accuracy as CoT unless the question or model's response contains an equals sign, indicating symbolic operations and reasoning. Following this finding, we analyze the behavior of CoT on these problems by separating planning and execution and comparing against tool-augmented LLMs. Much of CoT's gain comes from improving symbolic execution, but it underperforms relative to using a symbolic solver. Our results indicate that CoT can be applied selectively, maintaining performance while saving inference costs. Furthermore, they suggest a need to move beyond prompt-based CoT to new paradigms that better leverage intermediate computation across the whole range of LLM applications.
Lil-Bevo: Explorations of Strategies for Training Language Models in More Humanlike Ways
Oct 26, 2023



We present Lil-Bevo, our submission to the BabyLM Challenge. We pretrained our masked language models with three ingredients: an initial pretraining with music data, training on shorter sequences before training on longer ones, and masking specific tokens to target some of the BLiMP subtasks. Overall, our baseline models performed above chance, but far below the performance levels of larger LLMs trained on more data. We found that training on short sequences performed better than training on longer sequences.Pretraining on music may help performance marginally, but, if so, the effect seems small. Our targeted Masked Language Modeling augmentation did not seem to improve model performance in general, but did seem to help on some of the specific BLiMP tasks that we were targeting (e.g., Negative Polarity Items). Training performant LLMs on small amounts of data is a difficult but potentially informative task. While some of our techniques showed some promise, more work is needed to explore whether they can improve performance more than the modest gains here. Our code is available at https://github.com/venkatasg/Lil-Bevo and out models at https://huggingface.co/collections/venkatasg/babylm-653591cdb66f4bf68922873a
X-PARADE: Cross-Lingual Textual Entailment and Information Divergence across Paragraphs
Sep 16, 2023



Understanding when two pieces of text convey the same information is a goal touching many subproblems in NLP, including textual entailment and fact-checking. This problem becomes more complex when those two pieces of text are in different languages. Here, we introduce X-PARADE (Cross-lingual Paragraph-level Analysis of Divergences and Entailments), the first cross-lingual dataset of paragraph-level information divergences. Annotators label a paragraph in a target language at the span level and evaluate it with respect to a corresponding paragraph in a source language, indicating whether a given piece of information is the same, new, or new but can be inferred. This last notion establishes a link with cross-language NLI. Aligned paragraphs are sourced from Wikipedia pages in different languages, reflecting real information divergences observed in the wild. Armed with our dataset, we investigate a diverse set of approaches for this problem, including classic token alignment from machine translation, textual entailment methods that localize their decisions, and prompting of large language models. Our results show that these methods vary in their capability to handle inferable information, but they all fall short of human performance.
WiCE: Real-World Entailment for Claims in Wikipedia
Mar 02, 2023
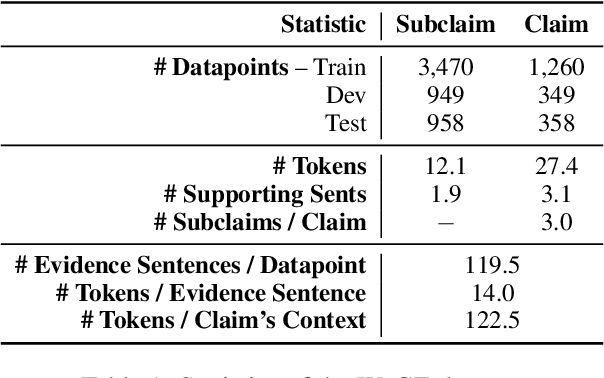

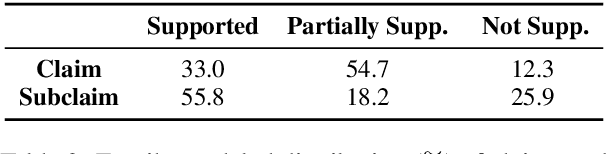
Models for textual entailment have increasingly been applied to settings like fact-checking, presupposition verification in question answering, and validating that generation models' outputs are faithful to a source. However, such applications are quite far from the settings that existing datasets are constructed in. We propose WiCE, a new textual entailment dataset centered around verifying claims in text, built on real-world claims and evidence in Wikipedia with fine-grained annotations. We collect sentences in Wikipedia that cite one or more webpages and annotate whether the content on those pages entails those sentences. Negative examples arise naturally, from slight misinterpretation of text to minor aspects of the sentence that are not attested in the evidence. Our annotations are over sub-sentence units of the hypothesis, decomposed automatically by GPT-3, each of which is labeled with a subset of evidence sentences from the source document. We show that real claims in our dataset involve challenging verification problems, and we benchmark existing approaches on this dataset. In addition, we show that reducing the complexity of claims by decomposing them by GPT-3 can improve entailment models' performance on various domains.
NL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Dec 06, 2021



Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository (\url{https://github.com/GEM-benchmark/NL-Augmenter}).