 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWiCE: Real-World Entailment for Claims in Wikipedia
Paper and Code

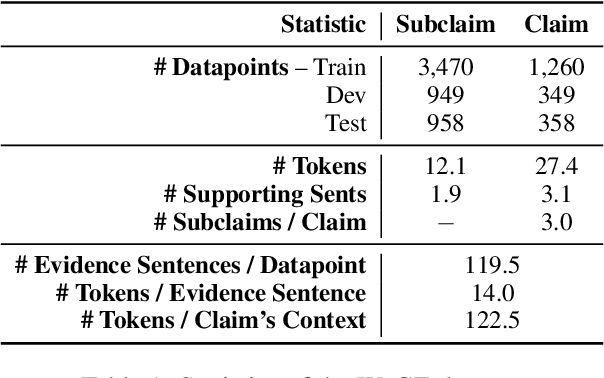

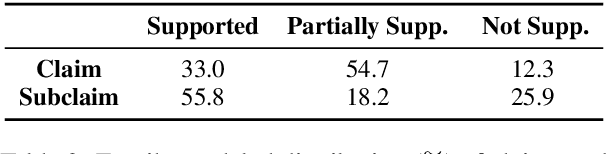
Models for textual entailment have increasingly been applied to settings like fact-checking, presupposition verification in question answering, and validating that generation models' outputs are faithful to a source. However, such applications are quite far from the settings that existing datasets are constructed in. We propose WiCE, a new textual entailment dataset centered around verifying claims in text, built on real-world claims and evidence in Wikipedia with fine-grained annotations. We collect sentences in Wikipedia that cite one or more webpages and annotate whether the content on those pages entails those sentences. Negative examples arise naturally, from slight misinterpretation of text to minor aspects of the sentence that are not attested in the evidence. Our annotations are over sub-sentence units of the hypothesis, decomposed automatically by GPT-3, each of which is labeled with a subset of evidence sentences from the source document. We show that real claims in our dataset involve challenging verification problems, and we benchmark existing approaches on this dataset. In addition, we show that reducing the complexity of claims by decomposing them by GPT-3 can improve entailment models' performance on various domains.