 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCRM: A Heuristic to Measure Response Pair Quality in Preference Optimization
Jun 17, 2025



Recent research has attempted to associate preference optimization (PO) performance with the underlying preference datasets. In this work, our observation is that the differences between the preferred response $y^+$ and dispreferred response $y^-$ influence what LLMs can learn, which may not match the desirable differences to learn. Therefore, we use distance and reward margin to quantify these differences, and combine them to get Distance Calibrated Reward Margin (DCRM), a metric that measures the quality of a response pair for PO. Intuitively, DCRM encourages minimal noisy differences and maximal desired differences. With this, we study 3 types of commonly used preference datasets, classified along two axes: the source of the responses and the preference labeling function. We establish a general correlation between higher DCRM of the training set and better learning outcome. Inspired by this, we propose a best-of-$N^2$ pairing method that selects response pairs with the highest DCRM. Empirically, in various settings, our method produces training datasets that can further improve models' performance on AlpacaEval, MT-Bench, and Arena-Hard over the existing training sets.
Memorization vs. Reasoning: Updating LLMs with New Knowledge
Apr 16, 2025



Large language models (LLMs) encode vast amounts of pre-trained knowledge in their parameters, but updating them as real-world information evolves remains a challenge. Existing methodologies and benchmarks primarily target entity substitutions, failing to capture the full breadth of complex real-world dynamics. In this paper, we introduce Knowledge Update Playground (KUP), an automatic pipeline for simulating realistic knowledge updates reflected in an evidence corpora. KUP's evaluation framework includes direct and indirect probes to both test memorization of updated facts and reasoning over them, for any update learning methods. Next, we present a lightweight method called memory conditioned training (MCT), which conditions tokens in the update corpus on self-generated "memory" tokens during training. Our strategy encourages LLMs to surface and reason over newly memorized knowledge at inference. Our results on two strong LLMs show that (1) KUP benchmark is highly challenging, with the best CPT models achieving $<2\%$ in indirect probing setting (reasoning) and (2) MCT training significantly outperforms prior continued pre-training (CPT) baselines, improving direct probing (memorization) results by up to $25.4\%$.
Recycled Attention: Efficient inference for long-context language models
Nov 08, 2024Generating long sequences of tokens given a long-context input imposes a heavy computational burden for large language models (LLMs). One of the computational bottleneck comes from computing attention over a long sequence of input at each generation step. In this paper, we propose Recycled Attention, an inference-time method which alternates between full context attention and attention over a subset of input tokens. When performing partial attention, we recycle the attention pattern of a previous token that has performed full attention and attend only to the top K most attended tokens, reducing the cost of data movement and attention computation. Compared to previously proposed inference-time acceleration method which attends only to local context or tokens with high accumulative attention scores, our approach flexibly chooses tokens that are relevant to the current decoding step. We evaluate our methods on RULER, a suite of tasks designed to comprehensively evaluate long-context abilities, and long-context language modeling tasks. Applying our method to off-the-shelf LLMs achieves comparable speedup to baselines which only consider local context while improving the performance by 2x. We further explore two ideas to improve performance-efficiency trade-offs: (1) dynamically decide when to perform recycled or full attention step based on the query similarities and (2) continued pre-training the model with Recycled Attention.
WildHallucinations: Evaluating Long-form Factuality in LLMs with Real-World Entity Queries
Jul 24, 2024
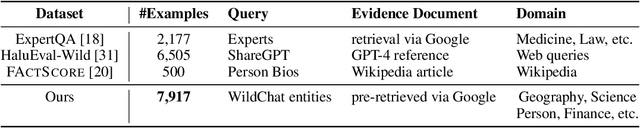
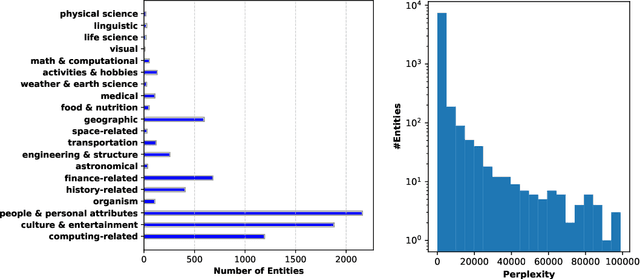
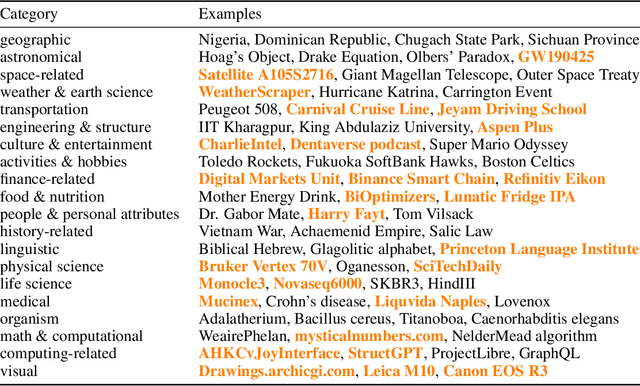
While hallucinations of large language models (LLMs) prevail as a major challenge, existing evaluation benchmarks on factuality do not cover the diverse domains of knowledge that the real-world users of LLMs seek information about. To bridge this gap, we introduce WildHallucinations, a benchmark that evaluates factuality. It does so by prompting LLMs to generate information about entities mined from user-chatbot conversations in the wild. These generations are then automatically fact-checked against a systematically curated knowledge source collected from web search. Notably, half of these real-world entities do not have associated Wikipedia pages. We evaluate 118,785 generations from 15 LLMs on 7,919 entities. We find that LLMs consistently hallucinate more on entities without Wikipedia pages and exhibit varying hallucination rates across different domains. Finally, given the same base models, adding a retrieval component only slightly reduces hallucinations but does not eliminate hallucinations.
One Thousand and One Pairs: A "novel" challenge for long-context language models
Jun 24, 2024Synthetic long-context LLM benchmarks (e.g., "needle-in-the-haystack") test only surface-level retrieval capabilities, but how well can long-context LLMs retrieve, synthesize, and reason over information across book-length inputs? We address this question by creating NoCha, a dataset of 1,001 minimally different pairs of true and false claims about 67 recently-published English fictional books, written by human readers of those books. In contrast to existing long-context benchmarks, our annotators confirm that the largest share of pairs in NoCha require global reasoning over the entire book to verify. Our experiments show that while human readers easily perform this task, it is enormously challenging for all ten long-context LLMs that we evaluate: no open-weight model performs above random chance (despite their strong performance on synthetic benchmarks), while GPT-4o achieves the highest accuracy at 55.8%. Further analysis reveals that (1) on average, models perform much better on pairs that require only sentence-level retrieval vs. global reasoning; (2) model-generated explanations for their decisions are often inaccurate even for correctly-labeled claims; and (3) models perform substantially worse on speculative fiction books that contain extensive world-building. The methodology proposed in NoCha allows for the evolution of the benchmark dataset and the easy analysis of future models.
D2PO: Discriminator-Guided DPO with Response Evaluation Models
May 02, 2024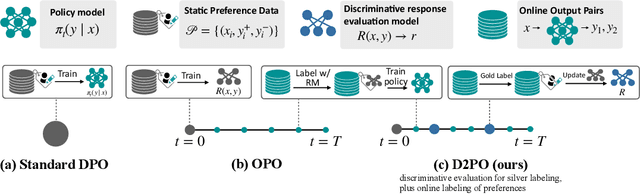
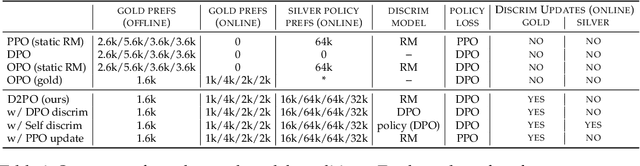
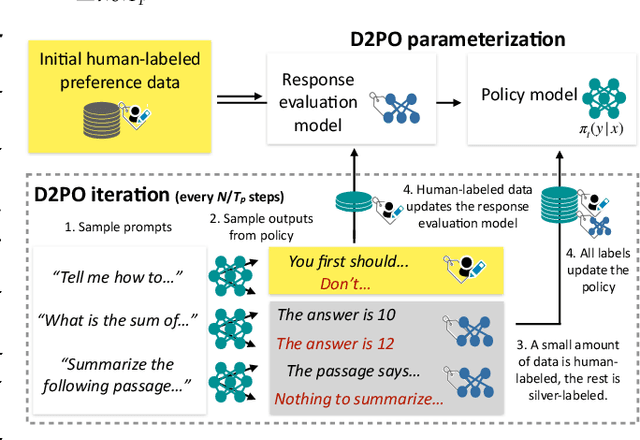
Varied approaches for aligning language models have been proposed, including supervised fine-tuning, RLHF, and direct optimization methods such as DPO. Although DPO has rapidly gained popularity due to its straightforward training process and competitive results, there is an open question of whether there remain practical advantages of using a discriminator, like a reward model, to evaluate responses. We propose D2PO, discriminator-guided DPO, an approach for the online setting where preferences are being collected throughout learning. As we collect gold preferences, we use these not only to train our policy, but to train a discriminative response evaluation model to silver-label even more synthetic data for policy training. We explore this approach across a set of diverse tasks, including a realistic chat setting, we find that our approach leads to higher-quality outputs compared to DPO with the same data budget, and greater efficiency in terms of preference data requirements. Furthermore, we show conditions under which silver labeling is most helpful: it is most effective when training the policy with DPO, outperforming traditional PPO, and benefits from maintaining a separate discriminator from the policy model.
FABLES: Evaluating faithfulness and content selection in book-length summarization
Apr 01, 2024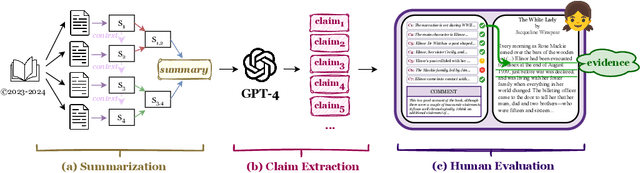
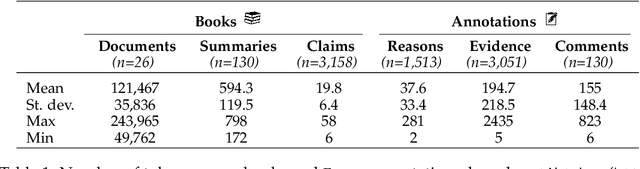


While long-context large language models (LLMs) can technically summarize book-length documents (>100K tokens), the length and complexity of the documents have so far prohibited evaluations of input-dependent aspects like faithfulness. In this paper, we conduct the first large-scale human evaluation of faithfulness and content selection on LLM-generated summaries of fictional books. Our study mitigates the issue of data contamination by focusing on summaries of books published in 2023 or 2024, and we hire annotators who have fully read each book prior to the annotation task to minimize cost and cognitive burden. We collect FABLES, a dataset of annotations on 3,158 claims made in LLM-generated summaries of 26 books, at a cost of $5.2K USD, which allows us to rank LLM summarizers based on faithfulness: Claude-3-Opus significantly outperforms all closed-source LLMs, while the open-source Mixtral is on par with GPT-3.5-Turbo. An analysis of the annotations reveals that most unfaithful claims relate to events and character states, and they generally require indirect reasoning over the narrative to invalidate. While LLM-based auto-raters have proven reliable for factuality and coherence in other settings, we implement several LLM raters of faithfulness and find that none correlates strongly with human annotations, especially with regard to detecting unfaithful claims. Our experiments suggest that detecting unfaithful claims is an important future direction not only for summarization evaluation but also as a testbed for long-context understanding. Finally, we move beyond faithfulness by exploring content selection errors in book-length summarization: we develop a typology of omission errors related to crucial narrative elements and also identify a systematic over-emphasis on events occurring towards the end of the book.
Evaluating Large Language Models at Evaluating Instruction Following
Oct 11, 2023



As research in large language models (LLMs) continues to accelerate, LLM-based evaluation has emerged as a scalable and cost-effective alternative to human evaluations for comparing the ever increasing list of models. This paper investigates the efficacy of these "LLM evaluators", particularly in using them to assess instruction following, a metric that gauges how closely generated text adheres to the given instruction. We introduce a challenging meta-evaluation benchmark, LLMBar, designed to test the ability of an LLM evaluator in discerning instruction-following outputs. The authors manually curated 419 pairs of outputs, one adhering to instructions while the other diverging, yet may possess deceptive qualities that mislead an LLM evaluator, e.g., a more engaging tone. Contrary to existing meta-evaluation, we discover that different evaluators (i.e., combinations of LLMs and prompts) exhibit distinct performance on LLMBar and even the highest-scoring ones have substantial room for improvement. We also present a novel suite of prompting strategies that further close the gap between LLM and human evaluators. With LLMBar, we hope to offer more insight into LLM evaluators and foster future research in developing better instruction-following models.
BooookScore: A systematic exploration of book-length summarization in the era of LLMs
Oct 05, 2023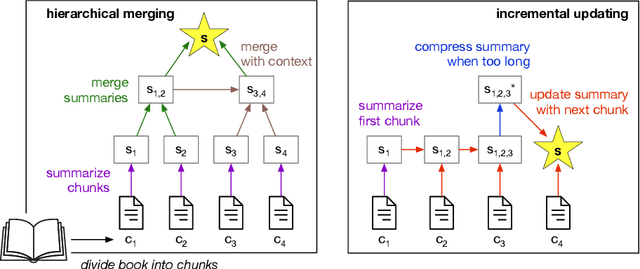
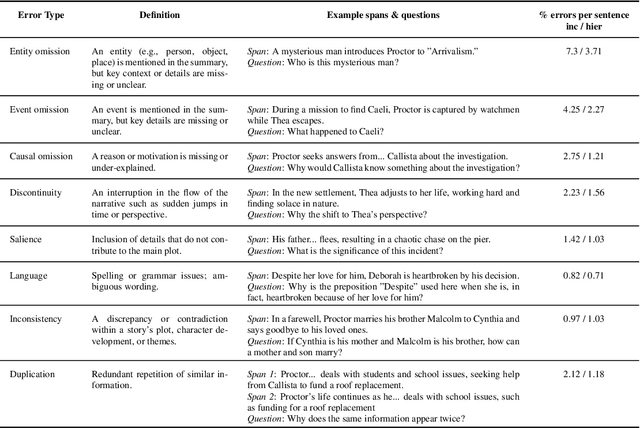
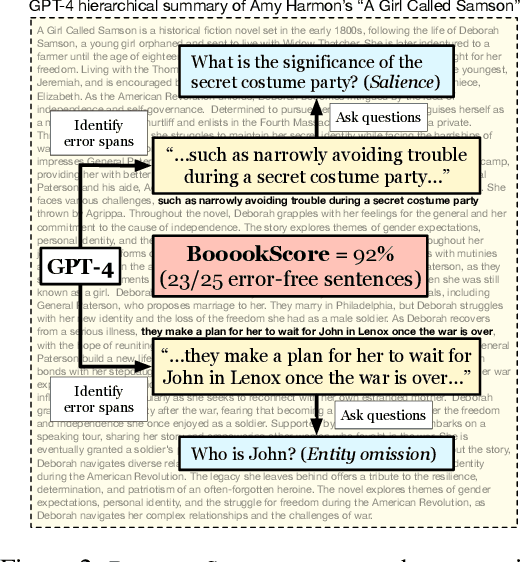
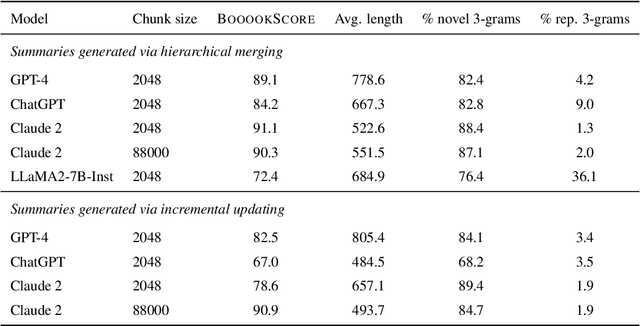
Summarizing book-length documents (>100K tokens) that exceed the context window size of large language models (LLMs) requires first breaking the input document into smaller chunks and then prompting an LLM to merge, update, and compress chunk-level summaries. Despite the complexity and importance of this task, it has yet to be meaningfully studied due to the challenges of evaluation: existing book-length summarization datasets (e.g., BookSum) are in the pretraining data of most public LLMs, and existing evaluation methods struggle to capture errors made by modern LLM summarizers. In this paper, we present the first study of the coherence of LLM-based book-length summarizers implemented via two prompting workflows: (1) hierarchically merging chunk-level summaries, and (2) incrementally updating a running summary. We obtain 1193 fine-grained human annotations on GPT-4 generated summaries of 100 recently-published books and identify eight common types of coherence errors made by LLMs. Because human evaluation is expensive and time-consuming, we develop an automatic metric, BooookScore, that measures the proportion of sentences in a summary that do not contain any of the identified error types. BooookScore has high agreement with human annotations and allows us to systematically evaluate the impact of many other critical parameters (e.g., chunk size, base LLM) while saving $15K and 500 hours in human evaluation costs. We find that closed-source LLMs such as GPT-4 and Claude 2 produce summaries with higher BooookScore than the oft-repetitive ones generated by LLaMA 2. Incremental updating yields lower BooookScore but higher level of detail than hierarchical merging, a trade-off sometimes preferred by human annotators. We release code and annotations after blind review to spur more principled research on book-length summarization.
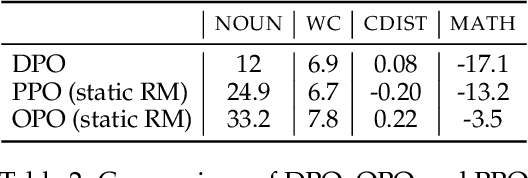
A Long Way to Go: Investigating Length Correlations in RLHF
Oct 05, 2023



Great successes have been reported using Reinforcement Learning from Human Feedback (RLHF) to align large language models. Open-source preference datasets and reward models have enabled wider experimentation beyond generic chat settings, particularly to make systems more "helpful" for tasks like web question answering, summarization, and multi-turn dialogue. When optimizing for helpfulness, RLHF has been consistently observed to drive models to produce longer outputs. This paper demonstrates that optimizing for response length is a significant factor behind RLHF's reported improvements in these settings. First, we study the relationship between reward and length for reward models trained on three open-source preference datasets for helpfulness. Here, length correlates strongly with reward, and improvements in reward score are driven in large part by shifting the distribution over output lengths. We then explore interventions during both RL and reward model learning to see if we can achieve the same downstream improvements as RLHF without increasing length. While our interventions mitigate length increases, they aren't uniformly effective across settings. Furthermore, we find that even running RLHF with a reward based solely on length can reproduce most of the downstream improvements over the initial policy model, showing that reward models in these settings have a long way to go.