 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Matters: How Do Multilingual Input and Reasoning Paths Affect Large Reasoning Models?
May 23, 2025Large reasoning models (LRMs) have demonstrated impressive performance across a range of reasoning tasks, yet little is known about their internal reasoning processes in multilingual settings. We begin with a critical question: {\it In which language do these models reason when solving problems presented in different languages?} Our findings reveal that, despite multilingual training, LRMs tend to default to reasoning in high-resource languages (e.g., English) at test time, regardless of the input language. When constrained to reason in the same language as the input, model performance declines, especially for low-resource languages. In contrast, reasoning in high-resource languages generally preserves performance. We conduct extensive evaluations across reasoning-intensive tasks (MMMLU, MATH-500) and non-reasoning benchmarks (CulturalBench, LMSYS-toxic), showing that the effect of language choice varies by task type: input-language reasoning degrades performance on reasoning tasks but benefits cultural tasks, while safety evaluations exhibit language-specific behavior. By exposing these linguistic biases in LRMs, our work highlights a critical step toward developing more equitable models that serve users across diverse linguistic backgrounds.
Will AI Tell Lies to Save Sick Children? Litmus-Testing AI Values Prioritization with AIRiskDilemmas
May 20, 2025Detecting AI risks becomes more challenging as stronger models emerge and find novel methods such as Alignment Faking to circumvent these detection attempts. Inspired by how risky behaviors in humans (i.e., illegal activities that may hurt others) are sometimes guided by strongly-held values, we believe that identifying values within AI models can be an early warning system for AI's risky behaviors. We create LitmusValues, an evaluation pipeline to reveal AI models' priorities on a range of AI value classes. Then, we collect AIRiskDilemmas, a diverse collection of dilemmas that pit values against one another in scenarios relevant to AI safety risks such as Power Seeking. By measuring an AI model's value prioritization using its aggregate choices, we obtain a self-consistent set of predicted value priorities that uncover potential risks. We show that values in LitmusValues (including seemingly innocuous ones like Care) can predict for both seen risky behaviors in AIRiskDilemmas and unseen risky behaviors in HarmBench.
DailyDilemmas: Revealing Value Preferences of LLMs with Quandaries of Daily Life
Oct 03, 2024



As we increasingly seek guidance from LLMs for decision-making in daily life, many of these decisions are not clear-cut and depend significantly on the personal values and ethical standards of the users. We present DailyDilemmas, a dataset of 1,360 moral dilemmas encountered in everyday life. Each dilemma includes two possible actions and with each action, the affected parties and human values invoked. Based on these dilemmas, we consolidated a set of human values across everyday topics e.g., interpersonal relationships, workplace, and environmental issues. We evaluated LLMs on these dilemmas to determine what action they will take and the values represented by these actions. Then, we analyzed these values through the lens of five popular theories inspired by sociology, psychology and philosophy. These theories are: World Value Survey, Moral Foundation Theory, Maslow's Hierarchy of Needs, Aristotle's Virtues, and Plutchik Wheel of Emotion. We find that LLMs are most aligned with the self-expression over survival values in terms of World Value Survey, care over loyalty in Moral Foundation Theory. Interestingly, we find large preferences differences in models for some core values such as truthfulness e.g., Mixtral-8x7B model tends to neglect it by 9.7% while GPT-4-turbo model tends to select it by 9.4%. We also study the recent guidance released by OpenAI (ModelSpec), and Anthropic (Constitutional AI) to understand how their released principles reflect their actual value prioritization when facing nuanced moral reasoning in daily-life settings. We find that end users cannot effectively steer such prioritization using system prompts.
CulturalBench: a Robust, Diverse and Challenging Benchmark on Measuring the (Lack of) Cultural Knowledge of LLMs
Oct 03, 2024



To make large language models (LLMs) more helpful across diverse cultures, it is essential to have effective cultural knowledge benchmarks to measure and track our progress. Effective benchmarks need to be robust, diverse, and challenging. We introduce CulturalBench: a set of 1,227 human-written and human-verified questions for effectively assessing LLMs' cultural knowledge, covering 45 global regions including the underrepresented ones like Bangladesh, Zimbabwe, and Peru. Questions - each verified by five independent annotators - span 17 diverse topics ranging from food preferences to greeting etiquettes. We evaluate models on two setups: CulturalBench-Easy and CulturalBench-Hard which share the same questions but asked differently. We find that LLMs are sensitive to such difference in setups (e.g., GPT-4o with 27.3% difference). Compared to human performance (92.6% accuracy), CulturalBench-Hard is more challenging for frontier LLMs with the best performing model (GPT-4o) at only 61.5% and the worst (Llama3-8b) at 21.4%. Moreover, we find that LLMs often struggle with tricky questions that have multiple correct answers (e.g., What utensils do the Chinese usually use?), revealing a tendency to converge to a single answer. Our results also indicate that OpenAI GPT-4o substantially outperform other proprietary and open source models in questions related to all but one region (Oceania). Nonetheless, all models consistently underperform on questions related to South America and the Middle East.
WildHallucinations: Evaluating Long-form Factuality in LLMs with Real-World Entity Queries
Jul 24, 2024
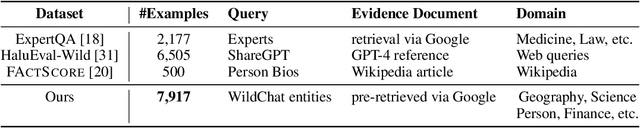
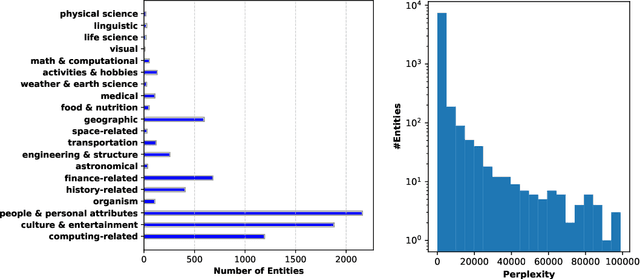
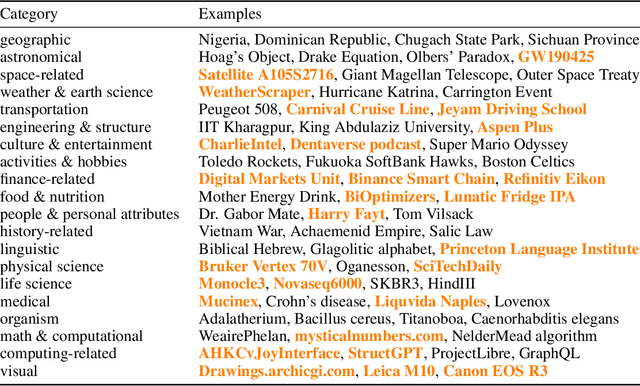
While hallucinations of large language models (LLMs) prevail as a major challenge, existing evaluation benchmarks on factuality do not cover the diverse domains of knowledge that the real-world users of LLMs seek information about. To bridge this gap, we introduce WildHallucinations, a benchmark that evaluates factuality. It does so by prompting LLMs to generate information about entities mined from user-chatbot conversations in the wild. These generations are then automatically fact-checked against a systematically curated knowledge source collected from web search. Notably, half of these real-world entities do not have associated Wikipedia pages. We evaluate 118,785 generations from 15 LLMs on 7,919 entities. We find that LLMs consistently hallucinate more on entities without Wikipedia pages and exhibit varying hallucination rates across different domains. Finally, given the same base models, adding a retrieval component only slightly reduces hallucinations but does not eliminate hallucinations.
Filtered Corpus Training (FiCT) Shows that Language Models can Generalize from Indirect Evidence
May 24, 2024This paper introduces Filtered Corpus Training, a method that trains language models (LMs) on corpora with certain linguistic constructions filtered out from the training data, and uses it to measure the ability of LMs to perform linguistic generalization on the basis of indirect evidence. We apply the method to both LSTM and Transformer LMs (of roughly comparable size), developing filtered corpora that target a wide range of linguistic phenomena. Our results show that while transformers are better qua LMs (as measured by perplexity), both models perform equally and surprisingly well on linguistic generalization measures, suggesting that they are capable of generalizing from indirect evidence.
CulturalTeaming: AI-Assisted Interactive Red-Teaming for Challenging LLMs' (Lack of) Multicultural Knowledge
Apr 10, 2024



Frontier large language models (LLMs) are developed by researchers and practitioners with skewed cultural backgrounds and on datasets with skewed sources. However, LLMs' (lack of) multicultural knowledge cannot be effectively assessed with current methods for developing benchmarks. Existing multicultural evaluations primarily rely on expensive and restricted human annotations or potentially outdated internet resources. Thus, they struggle to capture the intricacy, dynamics, and diversity of cultural norms. LLM-generated benchmarks are promising, yet risk propagating the same biases they are meant to measure. To synergize the creativity and expert cultural knowledge of human annotators and the scalability and standardizability of LLM-based automation, we introduce CulturalTeaming, an interactive red-teaming system that leverages human-AI collaboration to build truly challenging evaluation dataset for assessing the multicultural knowledge of LLMs, while improving annotators' capabilities and experiences. Our study reveals that CulturalTeaming's various modes of AI assistance support annotators in creating cultural questions, that modern LLMs fail at, in a gamified manner. Importantly, the increased level of AI assistance (e.g., LLM-generated revision hints) empowers users to create more difficult questions with enhanced perceived creativity of themselves, shedding light on the promises of involving heavier AI assistance in modern evaluation dataset creation procedures. Through a series of 1-hour workshop sessions, we gather CULTURALBENCH-V0.1, a compact yet high-quality evaluation dataset with users' red-teaming attempts, that different families of modern LLMs perform with accuracy ranging from 37.7% to 72.2%, revealing a notable gap in LLMs' multicultural proficiency.
A Computational Framework for Behavioral Assessment of LLM Therapists
Jan 01, 2024



The emergence of ChatGPT and other large language models (LLMs) has greatly increased interest in utilizing LLMs as therapists to support individuals struggling with mental health challenges. However, due to the lack of systematic studies, our understanding of how LLM therapists behave, i.e., ways in which they respond to clients, is significantly limited. Understanding their behavior across a wide range of clients and situations is crucial to accurately assess their capabilities and limitations in the high-risk setting of mental health, where undesirable behaviors can lead to severe consequences. In this paper, we propose BOLT, a novel computational framework to study the conversational behavior of LLMs when employed as therapists. We develop an in-context learning method to quantitatively measure the behavior of LLMs based on 13 different psychotherapy techniques including reflections, questions, solutions, normalizing, and psychoeducation. Subsequently, we compare the behavior of LLM therapists against that of high- and low-quality human therapy, and study how their behavior can be modulated to better reflect behaviors observed in high-quality therapy. Our analysis of GPT and Llama-variants reveals that these LLMs often resemble behaviors more commonly exhibited in low-quality therapy rather than high-quality therapy, such as offering a higher degree of problem-solving advice when clients share emotions, which is against typical recommendations. At the same time, unlike low-quality therapy, LLMs reflect significantly more upon clients' needs and strengths. Our analysis framework suggests that despite the ability of LLMs to generate anecdotal examples that appear similar to human therapists, LLM therapists are currently not fully consistent with high-quality care, and thus require additional research to ensure quality care.
Humanoid Agents: Platform for Simulating Human-like Generative Agents
Oct 09, 2023



Just as computational simulations of atoms, molecules and cells have shaped the way we study the sciences, true-to-life simulations of human-like agents can be valuable tools for studying human behavior. We propose Humanoid Agents, a system that guides Generative Agents to behave more like humans by introducing three elements of System 1 processing: Basic needs (e.g. hunger, health and energy), Emotion and Closeness in Relationships. Humanoid Agents are able to use these dynamic elements to adapt their daily activities and conversations with other agents, as supported with empirical experiments. Our system is designed to be extensible to various settings, three of which we demonstrate, as well as to other elements influencing human behavior (e.g. empathy, moral values and cultural background). Our platform also includes a Unity WebGL game interface for visualization and an interactive analytics dashboard to show agent statuses over time. Our platform is available on https://www.humanoidagents.com/ and code is on https://github.com/HumanoidAgents/HumanoidAgents