 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Mixed Training: Scaling Parametric Knowledge Acquisition Beyond RAG
Mar 24, 2026Synthetic data augmentation helps language models learn new knowledge in data-constrained domains. However, naively scaling existing synthetic data methods by training on more synthetic tokens or using stronger generators yields diminishing returns below the performance of RAG. To break the RAG ceiling, we introduce Synthetic Mixed Training, which combines synthetic QAs and synthetic documents. This leverages their complementary training signals, and enables log-linear improvements as both synthetic data volume and generator strength increase. This allows the model to outperform RAG by a 2.6\% relative gain on QuaLITY, a long-document reading comprehension benchmark. In addition, we introduce Focal Rewriting, a simple technique for synthetic document generation that explicitly conditions document generation on specific questions, improving the diversity of synthetic documents and yielding a steeper log-linear scaling curve. On QuaLITY, our final recipe trains a Llama 8B model that outperforms RAG by 4.4\% relatively. Across models and benchmarks (QuaLITY, LongHealth, FinanceBench), our training enables models to beat RAG in five of six settings, outperforms by 2.6\%, and achieves a 9.1\% gain when combined with RAG.
FDARxBench: Benchmarking Regulatory and Clinical Reasoning on FDA Generic Drug Assessment
Mar 20, 2026We introduce an expert curated, real-world benchmark for evaluating document-grounded question-answering (QA) motivated by generic drug assessment, using the U.S. Food and Drug Administration (FDA) drug label documents. Drug labels contain rich but heterogeneous clinical and regulatory information, making accurate question answering difficult for current language models. In collaboration with FDA regulatory assessors, we introduce FDARxBench, and construct a multi-stage pipeline for generating high-quality, expert curated, QA examples spanning factual, multi-hop, and refusal tasks, and design evaluation protocols to assess both open-book and closed-book reasoning. Experiments across proprietary and open-weight models reveal substantial gaps in factual grounding, long-context retrieval, and safe refusal behavior. While motivated by FDA generic drug assessment needs, this benchmark also provides a substantial foundation for challenging regulatory-grade evaluation of label comprehension. The benchmark is designed to support evaluation of LLM behavior on drug-label questions.
Verifying the Verifiers: Unveiling Pitfalls and Potentials in Fact Verifiers
Jun 16, 2025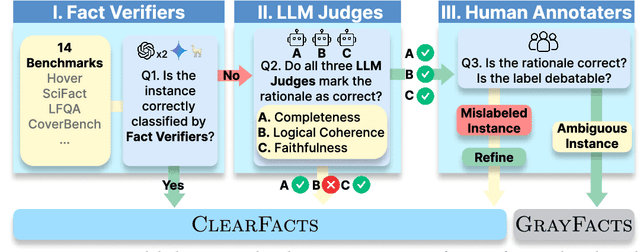

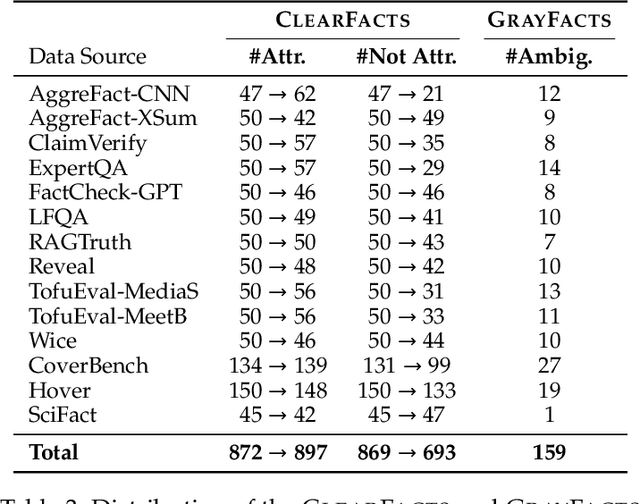
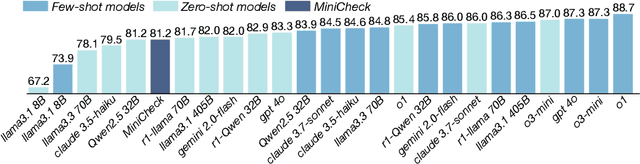
Fact verification is essential for ensuring the reliability of LLM applications. In this study, we evaluate 12 pre-trained LLMs and one specialized fact-verifier, including frontier LLMs and open-weight reasoning LLMs, using a collection of examples from 14 fact-checking benchmarks. We share three findings intended to guide future development of more robust fact verifiers. First, we highlight the importance of addressing annotation errors and ambiguity in datasets, demonstrating that approximately 16\% of ambiguous or incorrectly labeled data substantially influences model rankings. Neglecting this issue may result in misleading conclusions during comparative evaluations, and we suggest using a systematic pipeline utilizing LLM-as-a-judge to help identify these issues at scale. Second, we discover that frontier LLMs with few-shot in-context examples, often overlooked in previous works, achieve top-tier performance. We therefore recommend future studies include comparisons with these simple yet highly effective baselines. Lastly, despite their effectiveness, frontier LLMs incur substantial costs, motivating the development of small, fine-tuned fact verifiers. We show that these small models still have room for improvement, particularly on instances that require complex reasoning. Encouragingly, we demonstrate that augmenting training with synthetic multi-hop reasoning data significantly enhances their capabilities in such instances. We release our code, model, and dataset at https://github.com/just1nseo/verifying-the-verifiers
ArxivDIGESTables: Synthesizing Scientific Literature into Tables using Language Models
Oct 25, 2024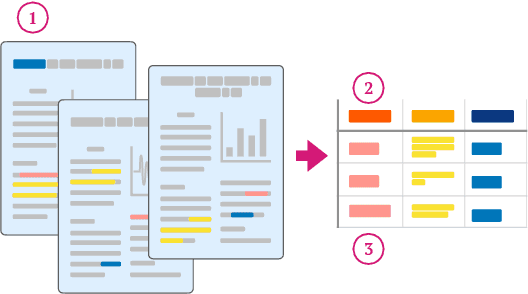

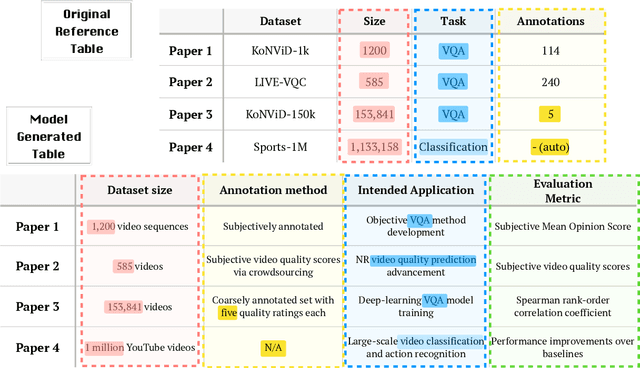
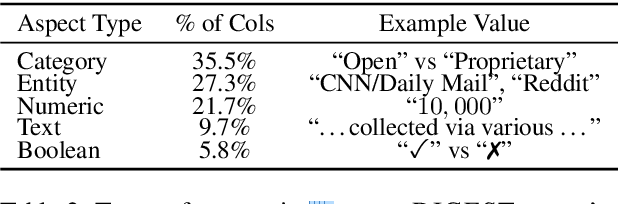
When conducting literature reviews, scientists often create literature review tables - tables whose rows are publications and whose columns constitute a schema, a set of aspects used to compare and contrast the papers. Can we automatically generate these tables using language models (LMs)? In this work, we introduce a framework that leverages LMs to perform this task by decomposing it into separate schema and value generation steps. To enable experimentation, we address two main challenges: First, we overcome a lack of high-quality datasets to benchmark table generation by curating and releasing arxivDIGESTables, a new dataset of 2,228 literature review tables extracted from ArXiv papers that synthesize a total of 7,542 research papers. Second, to support scalable evaluation of model generations against human-authored reference tables, we develop DecontextEval, an automatic evaluation method that aligns elements of tables with the same underlying aspects despite differing surface forms. Given these tools, we evaluate LMs' abilities to reconstruct reference tables, finding this task benefits from additional context to ground the generation (e.g. table captions, in-text references). Finally, through a human evaluation study we find that even when LMs fail to fully reconstruct a reference table, their generated novel aspects can still be useful.
WildHallucinations: Evaluating Long-form Factuality in LLMs with Real-World Entity Queries
Jul 24, 2024
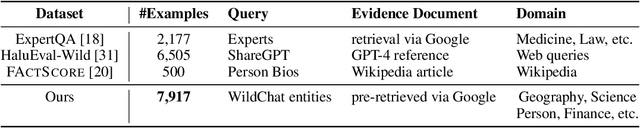
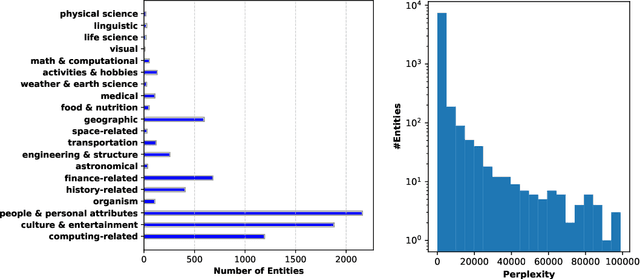
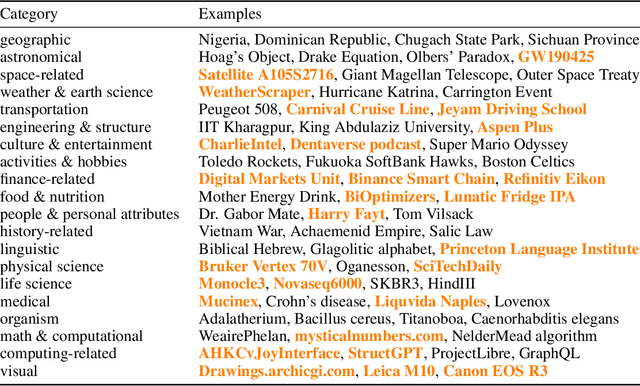
While hallucinations of large language models (LLMs) prevail as a major challenge, existing evaluation benchmarks on factuality do not cover the diverse domains of knowledge that the real-world users of LLMs seek information about. To bridge this gap, we introduce WildHallucinations, a benchmark that evaluates factuality. It does so by prompting LLMs to generate information about entities mined from user-chatbot conversations in the wild. These generations are then automatically fact-checked against a systematically curated knowledge source collected from web search. Notably, half of these real-world entities do not have associated Wikipedia pages. We evaluate 118,785 generations from 15 LLMs on 7,919 entities. We find that LLMs consistently hallucinate more on entities without Wikipedia pages and exhibit varying hallucination rates across different domains. Finally, given the same base models, adding a retrieval component only slightly reduces hallucinations but does not eliminate hallucinations.
Assessment of Sports Concussion in Female Athletes: A Role for Neuroinformatics?
Jan 23, 2024Over the past decade, the intricacies of sports-related concussions among female athletes have become readily apparent. Traditional clinical methods for diagnosing concussions suffer limitations when applied to female athletes, often failing to capture subtle changes in brain structure and function. Advanced neuroinformatics techniques and machine learning models have become invaluable assets in this endeavor. While these technologies have been extensively employed in understanding concussion in male athletes, there remains a significant gap in our comprehension of their effectiveness for female athletes. With its remarkable data analysis capacity, machine learning offers a promising avenue to bridge this deficit. By harnessing the power of machine learning, researchers can link observed phenotypic neuroimaging data to sex-specific biological mechanisms, unraveling the mysteries of concussions in female athletes. Furthermore, embedding methods within machine learning enable examining brain architecture and its alterations beyond the conventional anatomical reference frame. In turn, allows researchers to gain deeper insights into the dynamics of concussions, treatment responses, and recovery processes. To guarantee that female athletes receive the optimal care they deserve, researchers must employ advanced neuroimaging techniques and sophisticated machine-learning models. These tools enable an in-depth investigation of the underlying mechanisms responsible for concussion symptoms stemming from neuronal dysfunction in female athletes. This paper endeavors to address the crucial issue of sex differences in multimodal neuroimaging experimental design and machine learning approaches within female athlete populations, ultimately ensuring that they receive the tailored care they require when facing the challenges of concussions.
The Generative AI Paradox: "What It Can Create, It May Not Understand"
Oct 31, 2023
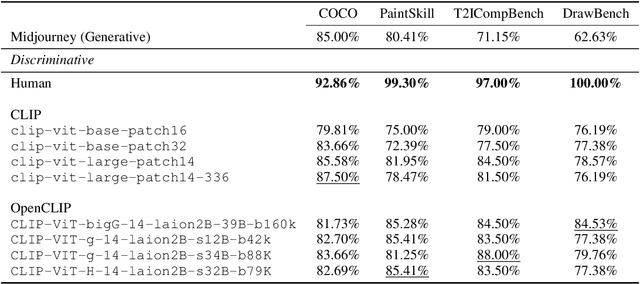
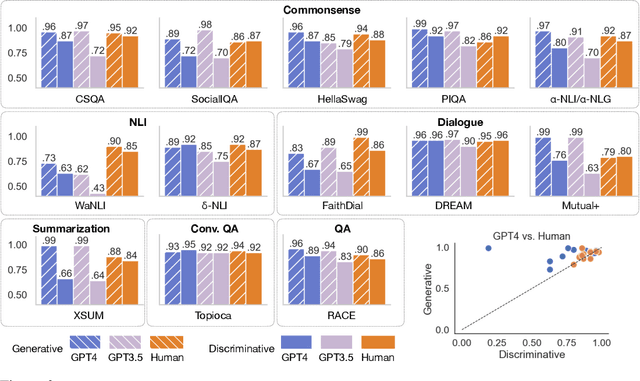
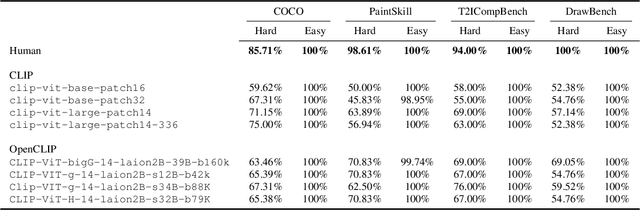
The recent wave of generative AI has sparked unprecedented global attention, with both excitement and concern over potentially superhuman levels of artificial intelligence: models now take only seconds to produce outputs that would challenge or exceed the capabilities even of expert humans. At the same time, models still show basic errors in understanding that would not be expected even in non-expert humans. This presents us with an apparent paradox: how do we reconcile seemingly superhuman capabilities with the persistence of errors that few humans would make? In this work, we posit that this tension reflects a divergence in the configuration of intelligence in today's generative models relative to intelligence in humans. Specifically, we propose and test the Generative AI Paradox hypothesis: generative models, having been trained directly to reproduce expert-like outputs, acquire generative capabilities that are not contingent upon -- and can therefore exceed -- their ability to understand those same types of outputs. This contrasts with humans, for whom basic understanding almost always precedes the ability to generate expert-level outputs. We test this hypothesis through controlled experiments analyzing generation vs. understanding in generative models, across both language and image modalities. Our results show that although models can outperform humans in generation, they consistently fall short of human capabilities in measures of understanding, as well as weaker correlation between generation and understanding performance, and more brittleness to adversarial inputs. Our findings support the hypothesis that models' generative capability may not be contingent upon understanding capability, and call for caution in interpreting artificial intelligence by analogy to human intelligence.
A Controllable QA-based Framework for Decontextualization
May 24, 2023Many real-world applications require surfacing extracted snippets to users, whether motivated by assistive tools for literature surveys or document cross-referencing, or needs to mitigate and recover from model generated inaccuracies., Yet, these passages can be difficult to consume when divorced from their original document context. In this work, we explore the limits of LLMs to perform decontextualization of document snippets in user-facing scenarios, focusing on two real-world settings - question answering and citation context previews for scientific documents. We propose a question-answering framework for decontextualization that allows for better handling of user information needs and preferences when determining the scope of rewriting. We present results showing state-of-the-art LLMs under our framework remain competitive with end-to-end approaches. We also explore incorporating user preferences into the system, finding our framework allows for controllability.
Comparing Sentence-Level Suggestions to Message-Level Suggestions in AI-Mediated Communication
Feb 26, 2023



Traditionally, writing assistance systems have focused on short or even single-word suggestions. Recently, large language models like GPT-3 have made it possible to generate significantly longer natural-sounding suggestions, offering more advanced assistance opportunities. This study explores the trade-offs between sentence- vs. message-level suggestions for AI-mediated communication. We recruited 120 participants to act as staffers from legislators' offices who often need to respond to large volumes of constituent concerns. Participants were asked to reply to emails with different types of assistance. The results show that participants receiving message-level suggestions responded faster and were more satisfied with the experience, as they mainly edited the suggested drafts. In addition, the texts they wrote were evaluated as more helpful by others. In comparison, participants receiving sentence-level assistance retained a higher sense of agency, but took longer for the task as they needed to plan the flow of their responses and decide when to use suggestions. Our findings have implications for designing task-appropriate communication assistance systems.
Holistic Evaluation of Language Models
Nov 16, 2022



Language models (LMs) are becoming the foundation for almost all major language technologies, but their capabilities, limitations, and risks are not well understood. We present Holistic Evaluation of Language Models (HELM) to improve the transparency of language models. First, we taxonomize the vast space of potential scenarios (i.e. use cases) and metrics (i.e. desiderata) that are of interest for LMs. Then we select a broad subset based on coverage and feasibility, noting what's missing or underrepresented (e.g. question answering for neglected English dialects, metrics for trustworthiness). Second, we adopt a multi-metric approach: We measure 7 metrics (accuracy, calibration, robustness, fairness, bias, toxicity, and efficiency) for each of 16 core scenarios when possible (87.5% of the time). This ensures metrics beyond accuracy don't fall to the wayside, and that trade-offs are clearly exposed. We also perform 7 targeted evaluations, based on 26 targeted scenarios, to analyze specific aspects (e.g. reasoning, disinformation). Third, we conduct a large-scale evaluation of 30 prominent language models (spanning open, limited-access, and closed models) on all 42 scenarios, 21 of which were not previously used in mainstream LM evaluation. Prior to HELM, models on average were evaluated on just 17.9% of the core HELM scenarios, with some prominent models not sharing a single scenario in common. We improve this to 96.0%: now all 30 models have been densely benchmarked on the same core scenarios and metrics under standardized conditions. Our evaluation surfaces 25 top-level findings. For full transparency, we release all raw model prompts and completions publicly for further analysis, as well as a general modular toolkit. We intend for HELM to be a living benchmark for the community, continuously updated with new scenarios, metrics, and models.