 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHARPA: A Testability-Driven, Literature-Grounded Framework for Research Ideation
Oct 01, 2025While there has been a surge of interest in automated scientific discovery (ASD), especially with the emergence of LLMs, it remains challenging for tools to generate hypotheses that are both testable and grounded in the scientific literature. Additionally, existing ideation tools are not adaptive to prior experimental outcomes. We developed HARPA to address these challenges by incorporating the ideation workflow inspired by human researchers. HARPA first identifies emerging research trends through literature mining, then explores hypothesis design spaces, and finally converges on precise, testable hypotheses by pinpointing research gaps and justifying design choices. Our evaluations show that HARPA-generated hypothesis-driven research proposals perform comparably to a strong baseline AI-researcher across most qualitative dimensions (e.g., specificity, novelty, overall quality), but achieve significant gains in feasibility(+0.78, p$<0.05$, bootstrap) and groundedness (+0.85, p$<0.01$, bootstrap) on a 10-point Likert scale. When tested with the ASD agent (CodeScientist), HARPA produced more successful executions (20 vs. 11 out of 40) and fewer failures (16 vs. 21 out of 40), showing that expert feasibility judgments track with actual execution success. Furthermore, to simulate how researchers continuously refine their understanding of what hypotheses are both testable and potentially interesting from experience, HARPA learns a reward model that scores new hypotheses based on prior experimental outcomes, achieving approx. a 28\% absolute gain over HARPA's untrained baseline scorer. Together, these methods represent a step forward in the field of AI-driven scientific discovery.
Cocoa: Co-Planning and Co-Execution with AI Agents
Dec 14, 2024



We present Cocoa, a system that implements a novel interaction design pattern -- interactive plans -- for users to collaborate with an AI agent on complex, multi-step tasks in a document editor. Cocoa harmonizes human and AI efforts and enables flexible delegation of agency through two actions: Co-planning (where users collaboratively compose a plan of action with the agent) and Co-execution (where users collaboratively execute plan steps with the agent). Using scientific research as a sample domain, we motivate the design of Cocoa through a formative study with 9 researchers while also drawing inspiration from the design of computational notebooks. We evaluate Cocoa through a user study with 16 researchers and find that when compared to a strong chat baseline, Cocoa improved agent steerability without sacrificing ease of use. A deeper investigation of the general utility of both systems uncovered insights into usage contexts where interactive plans may be more appropriate than chat, and vice versa. Our work surfaces numerous practical implications and paves new paths for interactive interfaces that foster more effective collaboration between humans and agentic AI systems.
ArxivDIGESTables: Synthesizing Scientific Literature into Tables using Language Models
Oct 25, 2024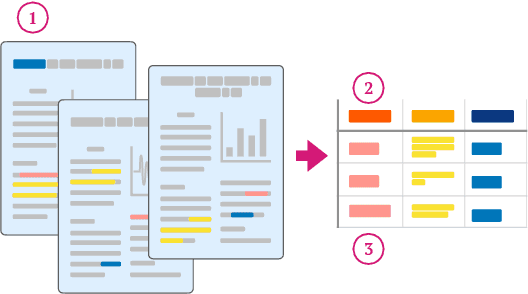

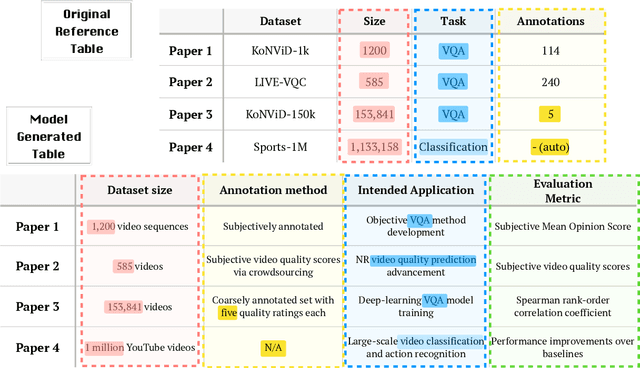
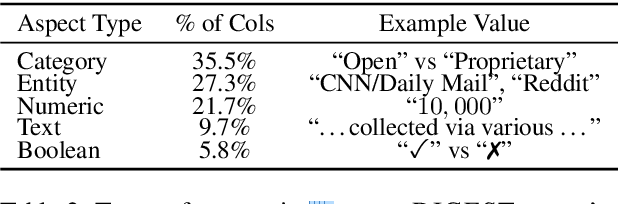
When conducting literature reviews, scientists often create literature review tables - tables whose rows are publications and whose columns constitute a schema, a set of aspects used to compare and contrast the papers. Can we automatically generate these tables using language models (LMs)? In this work, we introduce a framework that leverages LMs to perform this task by decomposing it into separate schema and value generation steps. To enable experimentation, we address two main challenges: First, we overcome a lack of high-quality datasets to benchmark table generation by curating and releasing arxivDIGESTables, a new dataset of 2,228 literature review tables extracted from ArXiv papers that synthesize a total of 7,542 research papers. Second, to support scalable evaluation of model generations against human-authored reference tables, we develop DecontextEval, an automatic evaluation method that aligns elements of tables with the same underlying aspects despite differing surface forms. Given these tools, we evaluate LMs' abilities to reconstruct reference tables, finding this task benefits from additional context to ground the generation (e.g. table captions, in-text references). Finally, through a human evaluation study we find that even when LMs fail to fully reconstruct a reference table, their generated novel aspects can still be useful.
IdeaSynth: Iterative Research Idea Development Through Evolving and Composing Idea Facets with Literature-Grounded Feedback
Oct 05, 2024



Research ideation involves broad exploring and deep refining ideas. Both require deep engagement with literature. Existing tools focus primarily on idea broad generation, yet offer little support for iterative specification, refinement, and evaluation needed to further develop initial ideas. To bridge this gap, we introduce IdeaSynth, a research idea development system that uses LLMs to provide literature-grounded feedback for articulating research problems, solutions, evaluations, and contributions. IdeaSynth represents these idea facets as nodes on a canvas, and allow researchers to iteratively refine them by creating and exploring variations and composing them. Our lab study (N=20) showed that participants, while using IdeaSynth, explored more alternative ideas and expanded initial ideas with more details compared to a strong LLM-based baseline. Our deployment study (N=7) demonstrated that participants effectively used IdeaSynth for real-world research projects at various ideation stages from developing initial ideas to revising framings of mature manuscripts, highlighting the possibilities to adopt IdeaSynth in researcher's workflows.
Scideator: Human-LLM Scientific Idea Generation Grounded in Research-Paper Facet Recombination
Sep 23, 2024



The scientific ideation process often involves blending salient aspects of existing papers to create new ideas. To see if large language models (LLMs) can assist this process, we contribute Scideator, a novel mixed-initiative tool for scientific ideation. Starting from a user-provided set of papers, Scideator extracts key facets (purposes, mechanisms, and evaluations) from these and relevant papers, allowing users to explore the idea space by interactively recombining facets to synthesize inventive ideas. Scideator also helps users to gauge idea novelty by searching the literature for potential overlaps and showing automated novelty assessments and explanations. To support these tasks, Scideator introduces four LLM-powered retrieval-augmented generation (RAG) modules: Analogous Paper Facet Finder, Faceted Idea Generator, Idea Novelty Checker, and Idea Novelty Iterator. In a within-subjects user study, 19 computer-science researchers identified significantly more interesting ideas using Scideator compared to a strong baseline combining a scientific search engine with LLM interaction.
A Design Space for Intelligent and Interactive Writing Assistants
Mar 26, 2024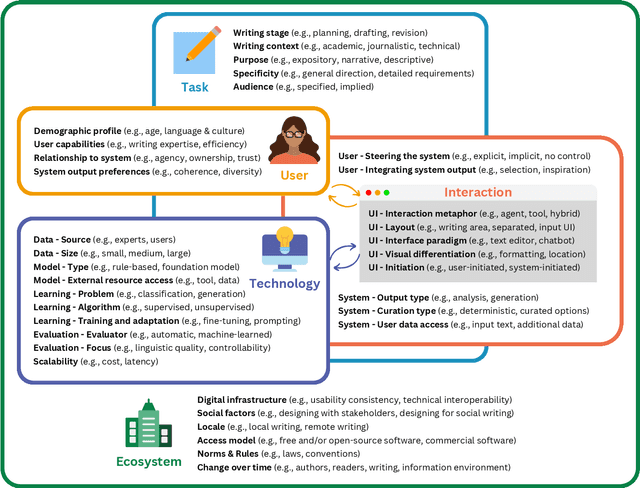
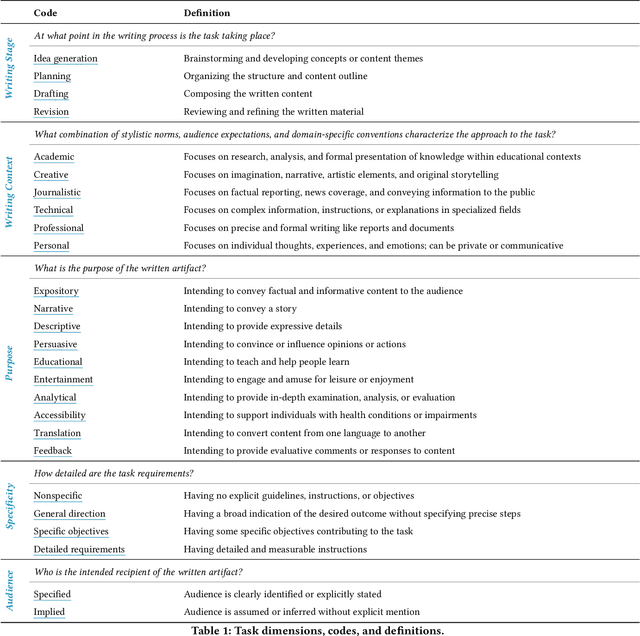
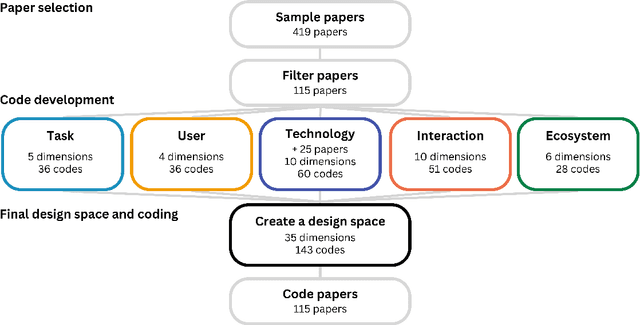
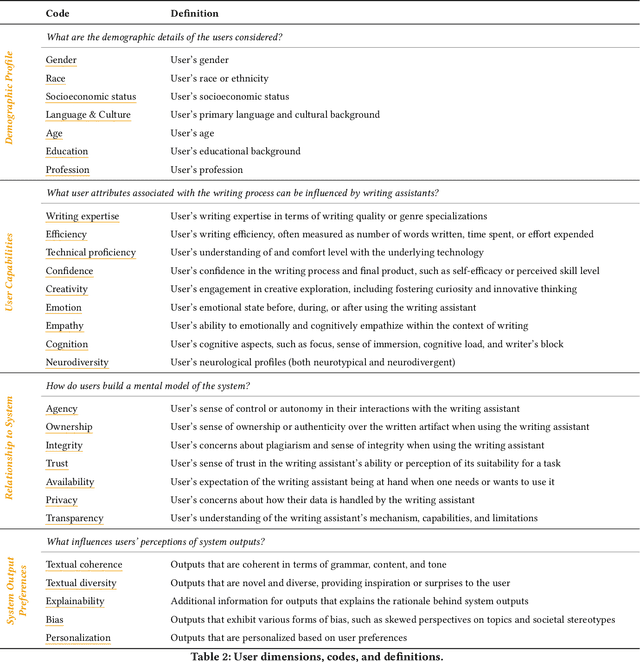
In our era of rapid technological advancement, the research landscape for writing assistants has become increasingly fragmented across various research communities. We seek to address this challenge by proposing a design space as a structured way to examine and explore the multidimensional space of intelligent and interactive writing assistants. Through a large community collaboration, we explore five aspects of writing assistants: task, user, technology, interaction, and ecosystem. Within each aspect, we define dimensions (i.e., fundamental components of an aspect) and codes (i.e., potential options for each dimension) by systematically reviewing 115 papers. Our design space aims to offer researchers and designers a practical tool to navigate, comprehend, and compare the various possibilities of writing assistants, and aid in the envisioning and design of new writing assistants.
PaperWeaver: Enriching Topical Paper Alerts by Contextualizing Recommended Papers with User-collected Papers
Mar 05, 2024With the rapid growth of scholarly archives, researchers subscribe to "paper alert" systems that periodically provide them with recommendations of recently published papers that are similar to previously collected papers. However, researchers sometimes struggle to make sense of nuanced connections between recommended papers and their own research context, as existing systems only present paper titles and abstracts. To help researchers spot these connections, we present PaperWeaver, an enriched paper alerts system that provides contextualized text descriptions of recommended papers based on user-collected papers. PaperWeaver employs a computational method based on Large Language Models (LLMs) to infer users' research interests from their collected papers, extract context-specific aspects of papers, and compare recommended and collected papers on these aspects. Our user study (N=15) showed that participants using PaperWeaver were able to better understand the relevance of recommended papers and triage them more confidently when compared to a baseline that presented the related work sections from recommended papers.
Beyond Summarization: Designing AI Support for Real-World Expository Writing Tasks
Apr 05, 2023Large language models have introduced exciting new opportunities and challenges in designing and developing new AI-assisted writing support tools. Recent work has shown that leveraging this new technology can transform writing in many scenarios such as ideation during creative writing, editing support, and summarization. However, AI-supported expository writing--including real-world tasks like scholars writing literature reviews or doctors writing progress notes--is relatively understudied. In this position paper, we argue that developing AI supports for expository writing has unique and exciting research challenges and can lead to high real-world impacts. We characterize expository writing as evidence-based and knowledge-generating: it contains summaries of external documents as well as new information or knowledge. It can be seen as the product of authors' sensemaking process over a set of source documents, and the interplay between reading, reflection, and writing opens up new opportunities for designing AI support. We sketch three components for AI support design and discuss considerations for future research.
The Semantic Reader Project: Augmenting Scholarly Documents through AI-Powered Interactive Reading Interfaces
Mar 25, 2023



Scholarly publications are key to the transfer of knowledge from scholars to others. However, research papers are information-dense, and as the volume of the scientific literature grows, the need for new technology to support the reading process grows. In contrast to the process of finding papers, which has been transformed by Internet technology, the experience of reading research papers has changed little in decades. The PDF format for sharing research papers is widely used due to its portability, but it has significant downsides including: static content, poor accessibility for low-vision readers, and difficulty reading on mobile devices. This paper explores the question "Can recent advances in AI and HCI power intelligent, interactive, and accessible reading interfaces -- even for legacy PDFs?" We describe the Semantic Reader Project, a collaborative effort across multiple institutions to explore automatic creation of dynamic reading interfaces for research papers. Through this project, we've developed ten research prototype interfaces and conducted usability studies with more than 300 participants and real-world users showing improved reading experiences for scholars. We've also released a production reading interface for research papers that will incorporate the best features as they mature. We structure this paper around challenges scholars and the public face when reading research papers -- Discovery, Efficiency, Comprehension, Synthesis, and Accessibility -- and present an overview of our progress and remaining open challenges.