 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLibra-Leaderboard: Towards Responsible AI through a Balanced Leaderboard of Safety and Capability
Dec 24, 2024



To address this gap, we introduce Libra-Leaderboard, a comprehensive framework designed to rank LLMs through a balanced evaluation of performance and safety. Combining a dynamic leaderboard with an interactive LLM arena, Libra-Leaderboard encourages the joint optimization of capability and safety. Unlike traditional approaches that average performance and safety metrics, Libra-Leaderboard uses a distance-to-optimal-score method to calculate the overall rankings. This approach incentivizes models to achieve a balance rather than excelling in one dimension at the expense of some other ones. In the first release, Libra-Leaderboard evaluates 26 mainstream LLMs from 14 leading organizations, identifying critical safety challenges even in state-of-the-art models.
Bridging the Data Provenance Gap Across Text, Speech and Video
Dec 19, 2024



Progress in AI is driven largely by the scale and quality of training data. Despite this, there is a deficit of empirical analysis examining the attributes of well-established datasets beyond text. In this work we conduct the largest and first-of-its-kind longitudinal audit across modalities--popular text, speech, and video datasets--from their detailed sourcing trends and use restrictions to their geographical and linguistic representation. Our manual analysis covers nearly 4000 public datasets between 1990-2024, spanning 608 languages, 798 sources, 659 organizations, and 67 countries. We find that multimodal machine learning applications have overwhelmingly turned to web-crawled, synthetic, and social media platforms, such as YouTube, for their training sets, eclipsing all other sources since 2019. Secondly, tracing the chain of dataset derivations we find that while less than 33% of datasets are restrictively licensed, over 80% of the source content in widely-used text, speech, and video datasets, carry non-commercial restrictions. Finally, counter to the rising number of languages and geographies represented in public AI training datasets, our audit demonstrates measures of relative geographical and multilingual representation have failed to significantly improve their coverage since 2013. We believe the breadth of our audit enables us to empirically examine trends in data sourcing, restrictions, and Western-centricity at an ecosystem-level, and that visibility into these questions are essential to progress in responsible AI. As a contribution to ongoing improvements in dataset transparency and responsible use, we release our entire multimodal audit, allowing practitioners to trace data provenance across text, speech, and video.
Second Language (Arabic) Acquisition of LLMs via Progressive Vocabulary Expansion
Dec 16, 2024



This paper addresses the critical need for democratizing large language models (LLM) in the Arab world, a region that has seen slower progress in developing models comparable to state-of-the-art offerings like GPT-4 or ChatGPT 3.5, due to a predominant focus on mainstream languages (e.g., English and Chinese). One practical objective for an Arabic LLM is to utilize an Arabic-specific vocabulary for the tokenizer that could speed up decoding. However, using a different vocabulary often leads to a degradation of learned knowledge since many words are initially out-of-vocabulary (OOV) when training starts. Inspired by the vocabulary learning during Second Language (Arabic) Acquisition for humans, the released AraLLaMA employs progressive vocabulary expansion, which is implemented by a modified BPE algorithm that progressively extends the Arabic subwords in its dynamic vocabulary during training, thereby balancing the OOV ratio at every stage. The ablation study demonstrated the effectiveness of Progressive Vocabulary Expansion. Moreover, AraLLaMA achieves decent performance comparable to the best Arabic LLMs across a variety of Arabic benchmarks. Models, training data, benchmarks, and codes will be all open-sourced.
A Design Space for Intelligent and Interactive Writing Assistants
Mar 26, 2024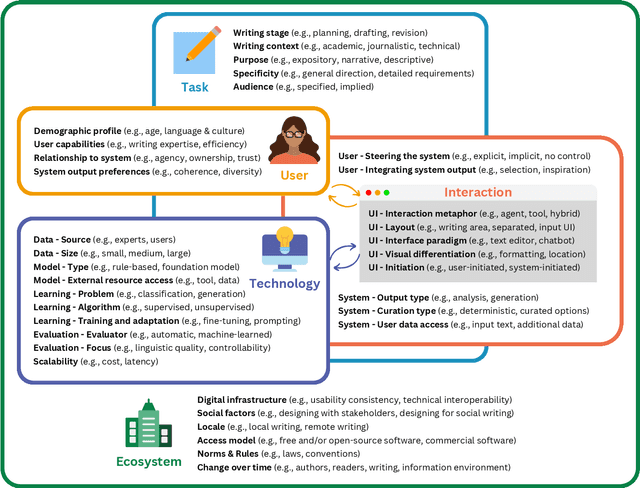
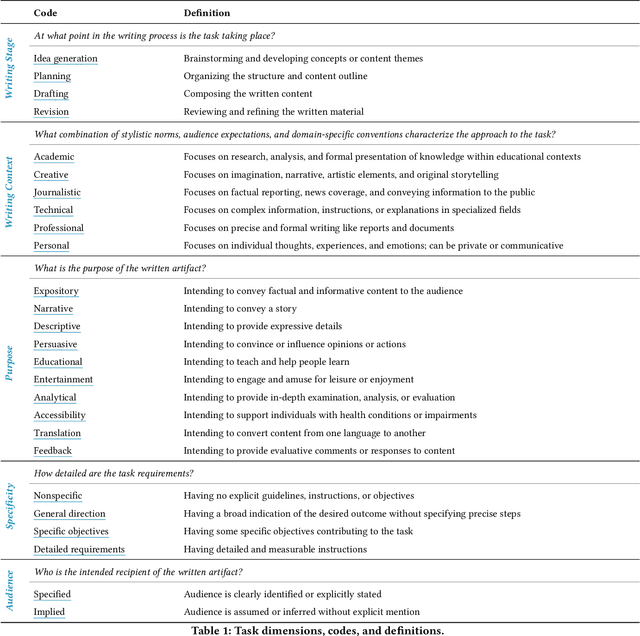
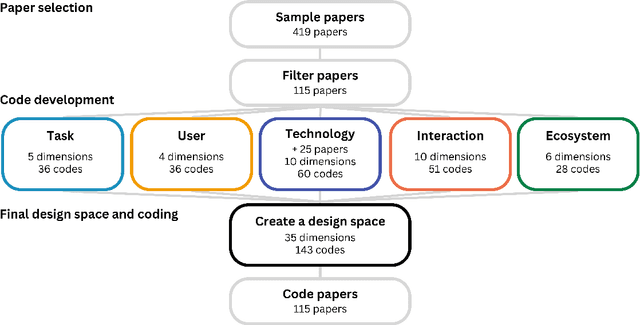
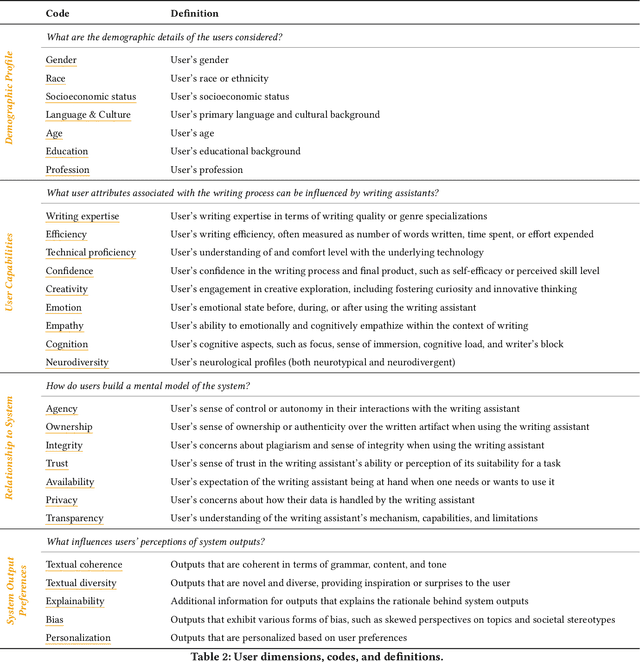
In our era of rapid technological advancement, the research landscape for writing assistants has become increasingly fragmented across various research communities. We seek to address this challenge by proposing a design space as a structured way to examine and explore the multidimensional space of intelligent and interactive writing assistants. Through a large community collaboration, we explore five aspects of writing assistants: task, user, technology, interaction, and ecosystem. Within each aspect, we define dimensions (i.e., fundamental components of an aspect) and codes (i.e., potential options for each dimension) by systematically reviewing 115 papers. Our design space aims to offer researchers and designers a practical tool to navigate, comprehend, and compare the various possibilities of writing assistants, and aid in the envisioning and design of new writing assistants.
AraTrust: An Evaluation of Trustworthiness for LLMs in Arabic
Mar 15, 2024



The swift progress and widespread acceptance of artificial intelligence (AI) systems highlight a pressing requirement to comprehend both the capabilities and potential risks associated with AI. Given the linguistic complexity, cultural richness, and underrepresented status of Arabic in AI research, there is a pressing need to focus on Large Language Models (LLMs) performance and safety for Arabic related tasks. Despite some progress in their development, there is a lack of comprehensive trustworthiness evaluation benchmarks which presents a major challenge in accurately assessing and improving the safety of LLMs when prompted in Arabic. In this paper, we introduce AraTrust, the first comprehensive trustworthiness benchmark for LLMs in Arabic. AraTrust comprises 516 human-written multiple-choice questions addressing diverse dimensions related to truthfulness, ethics, safety, physical health, mental health, unfairness, illegal activities, privacy, and offensive language. We evaluated a set of LLMs against our benchmark to assess their trustworthiness. GPT-4 was the most trustworthy LLM, while open-source models, particularly AceGPT 7B and Jais 13B, struggled to achieve a score of 60% in our benchmark.
SARD: A Human-AI Collaborative Story Generation
Mar 03, 2024


Generative artificial intelligence (GenAI) has ushered in a new era for storytellers, providing a powerful tool to ignite creativity and explore uncharted narrative territories. As technology continues to advance, the synergy between human creativity and AI-generated content holds the potential to redefine the landscape of storytelling. In this work, we propose SARD, a drag-and-drop visual interface for generating a multi-chapter story using large language models. Our evaluation of the usability of SARD and its creativity support shows that while node-based visualization of the narrative may help writers build a mental model, it exerts unnecessary mental overhead to the writer and becomes a source of distraction as the story becomes more elaborated. We also found that AI generates stories that are less lexically diverse, irrespective of the complexity of the story. We identified some patterns and limitations of our tool that can guide the development of future human-AI co-writing tools.
Aya Dataset: An Open-Access Collection for Multilingual Instruction Tuning
Feb 09, 2024
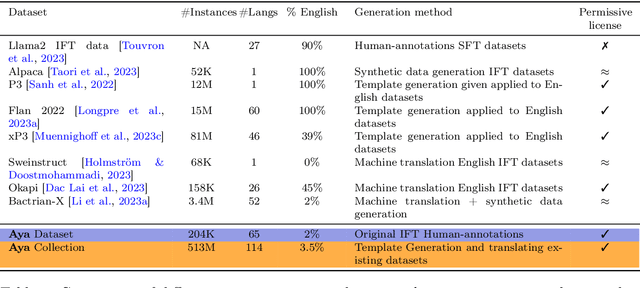
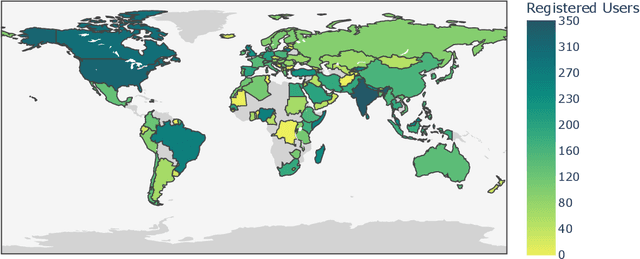
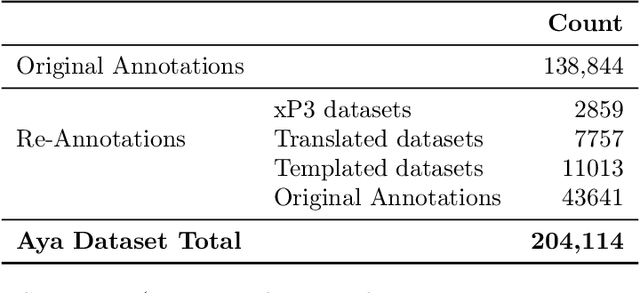
Datasets are foundational to many breakthroughs in modern artificial intelligence. Many recent achievements in the space of natural language processing (NLP) can be attributed to the finetuning of pre-trained models on a diverse set of tasks that enables a large language model (LLM) to respond to instructions. Instruction fine-tuning (IFT) requires specifically constructed and annotated datasets. However, existing datasets are almost all in the English language. In this work, our primary goal is to bridge the language gap by building a human-curated instruction-following dataset spanning 65 languages. We worked with fluent speakers of languages from around the world to collect natural instances of instructions and completions. Furthermore, we create the most extensive multilingual collection to date, comprising 513 million instances through templating and translating existing datasets across 114 languages. In total, we contribute four key resources: we develop and open-source the Aya Annotation Platform, the Aya Dataset, the Aya Collection, and the Aya Evaluation Suite. The Aya initiative also serves as a valuable case study in participatory research, involving collaborators from 119 countries. We see this as a valuable framework for future research collaborations that aim to bridge gaps in resources.
Domain Adaptation for Arabic Machine Translation: The Case of Financial Texts
Sep 22, 2023



Neural machine translation (NMT) has shown impressive performance when trained on large-scale corpora. However, generic NMT systems have demonstrated poor performance on out-of-domain translation. To mitigate this issue, several domain adaptation methods have recently been proposed which often lead to better translation quality than genetic NMT systems. While there has been some continuous progress in NMT for English and other European languages, domain adaption in Arabic has received little attention in the literature. The current study, therefore, aims to explore the effectiveness of domain-specific adaptation for Arabic MT (AMT), in yet unexplored domain, financial news articles. To this end, we developed carefully a parallel corpus for Arabic-English (AR- EN) translation in the financial domain for benchmarking different domain adaptation methods. We then fine-tuned several pre-trained NMT and Large Language models including ChatGPT-3.5 Turbo on our dataset. The results showed that the fine-tuning is successful using just a few well-aligned in-domain AR-EN segments. The quality of ChatGPT translation was superior than other models based on automatic and human evaluations. To the best of our knowledge, this is the first work on fine-tuning ChatGPT towards financial domain transfer learning. To contribute to research in domain translation, we made our datasets and fine-tuned models available at https://huggingface.co/asas-ai/.
Masader Plus: A New Interface for Exploring +500 Arabic NLP Datasets
Aug 01, 2022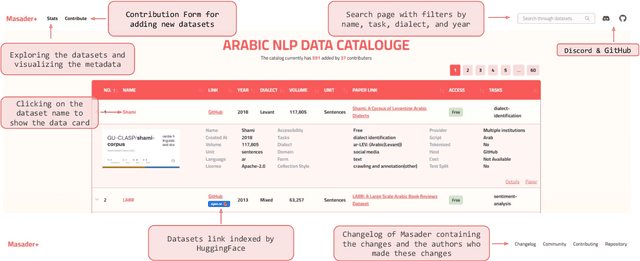
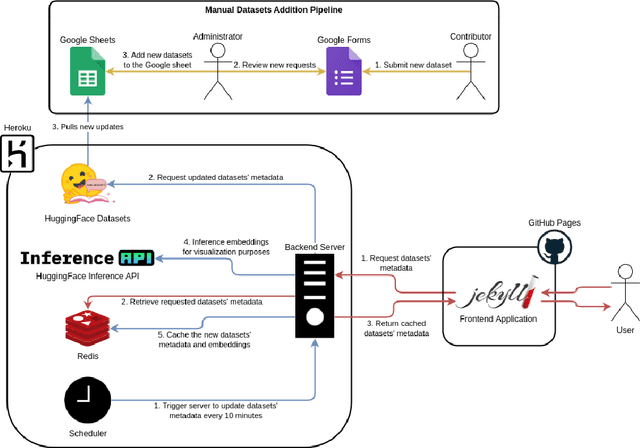
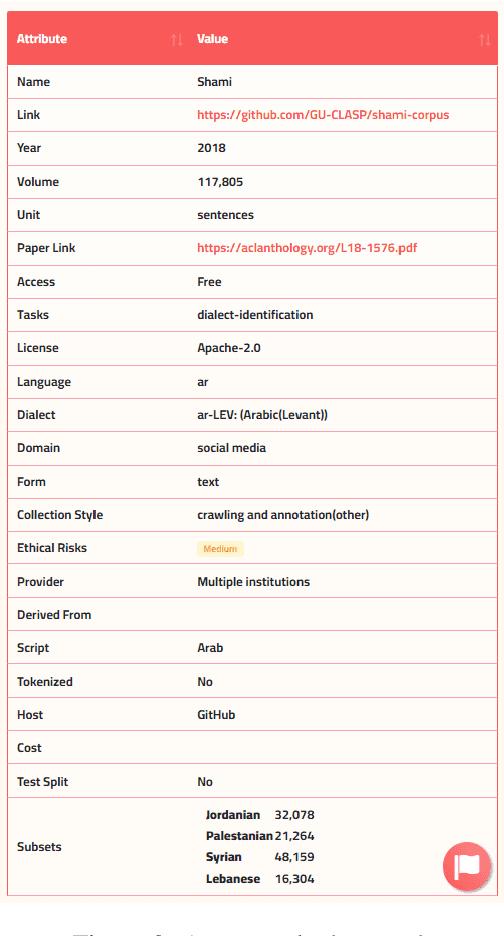
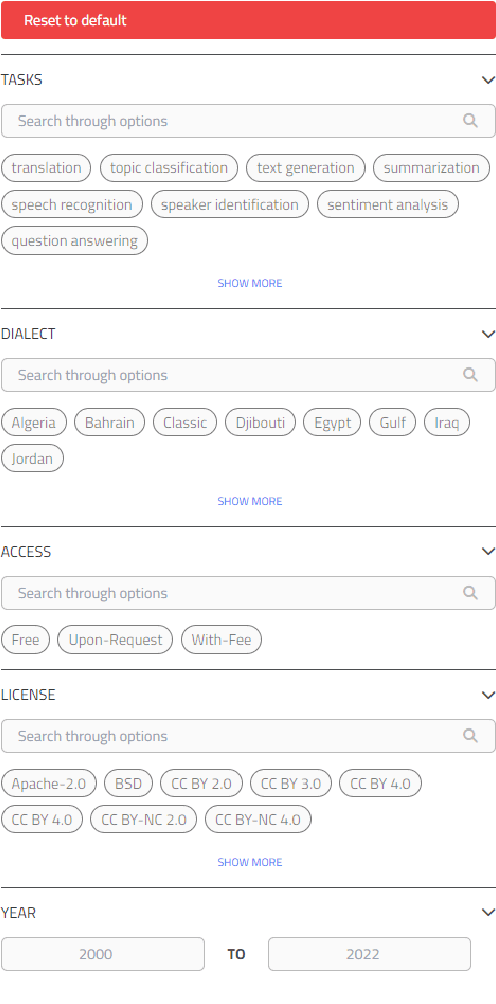
Masader (Alyafeai et al., 2021) created a metadata structure to be used for cataloguing Arabic NLP datasets. However, developing an easy way to explore such a catalogue is a challenging task. In order to give the optimal experience for users and researchers exploring the catalogue, several design and user experience challenges must be resolved. Furthermore, user interactions with the website may provide an easy approach to improve the catalogue. In this paper, we introduce Masader Plus, a web interface for users to browse Masader. We demonstrate data exploration, filtration, and a simple API that allows users to examine datasets from the backend. Masader Plus can be explored using this link https://arbml.github.io/masader. A video recording explaining the interface can be found here https://www.youtube.com/watch?v=SEtdlSeqchk.