 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWAXAL: A Large-Scale Multilingual African Language Speech Corpus
Feb 02, 2026The advancement of speech technology has predominantly favored high-resource languages, creating a significant digital divide for speakers of most Sub-Saharan African languages. To address this gap, we introduce WAXAL, a large-scale, openly accessible speech dataset for 21 languages representing over 100 million speakers. The collection consists of two main components: an Automated Speech Recognition (ASR) dataset containing approximately 1,250 hours of transcribed, natural speech from a diverse range of speakers, and a Text-to-Speech (TTS) dataset with over 180 hours of high-quality, single-speaker recordings reading phonetically balanced scripts. This paper details our methodology for data collection, annotation, and quality control, which involved partnerships with four African academic and community organizations. We provide a detailed statistical overview of the dataset and discuss its potential limitations and ethical considerations. The WAXAL datasets are released at https://huggingface.co/datasets/google/WaxalNLP under the permissive CC-BY-4.0 license to catalyze research, enable the development of inclusive technologies, and serve as a vital resource for the digital preservation of these languages.
Expert Evaluation of LLM World Models: A High-$T_c$ Superconductivity Case Study
Nov 05, 2025Large Language Models (LLMs) show great promise as a powerful tool for scientific literature exploration. However, their effectiveness in providing scientifically accurate and comprehensive answers to complex questions within specialized domains remains an active area of research. Using the field of high-temperature cuprates as an exemplar, we evaluate the ability of LLM systems to understand the literature at the level of an expert. We construct an expert-curated database of 1,726 scientific papers that covers the history of the field, and a set of 67 expert-formulated questions that probe deep understanding of the literature. We then evaluate six different LLM-based systems for answering these questions, including both commercially available closed models and a custom retrieval-augmented generation (RAG) system capable of retrieving images alongside text. Experts then evaluate the answers of these systems against a rubric that assesses balanced perspectives, factual comprehensiveness, succinctness, and evidentiary support. Among the six systems two using RAG on curated literature outperformed existing closed models across key metrics, particularly in providing comprehensive and well-supported answers. We discuss promising aspects of LLM performances as well as critical short-comings of all the models. The set of expert-formulated questions and the rubric will be valuable for assessing expert level performance of LLM based reasoning systems.
FEABench: Evaluating Language Models on Multiphysics Reasoning Ability
Apr 08, 2025Building precise simulations of the real world and invoking numerical solvers to answer quantitative problems is an essential requirement in engineering and science. We present FEABench, a benchmark to evaluate the ability of large language models (LLMs) and LLM agents to simulate and solve physics, mathematics and engineering problems using finite element analysis (FEA). We introduce a comprehensive evaluation scheme to investigate the ability of LLMs to solve these problems end-to-end by reasoning over natural language problem descriptions and operating COMSOL Multiphysics$^\circledR$, an FEA software, to compute the answers. We additionally design a language model agent equipped with the ability to interact with the software through its Application Programming Interface (API), examine its outputs and use tools to improve its solutions over multiple iterations. Our best performing strategy generates executable API calls 88% of the time. LLMs that can successfully interact with and operate FEA software to solve problems such as those in our benchmark would push the frontiers of automation in engineering. Acquiring this capability would augment LLMs' reasoning skills with the precision of numerical solvers and advance the development of autonomous systems that can tackle complex problems in the real world. The code is available at https://github.com/google/feabench
Towards AI-assisted Academic Writing
Mar 17, 2025We present components of an AI-assisted academic writing system including citation recommendation and introduction writing. The system recommends citations by considering the user's current document context to provide relevant suggestions. It generates introductions in a structured fashion, situating the contributions of the research relative to prior work. We demonstrate the effectiveness of the components through quantitative evaluations. Finally, the paper presents qualitative research exploring how researchers incorporate citations into their writing workflows. Our findings indicate that there is demand for precise AI-assisted writing systems and simple, effective methods for meeting those needs.
Towards a Single ASR Model That Generalizes to Disordered Speech
Dec 26, 2024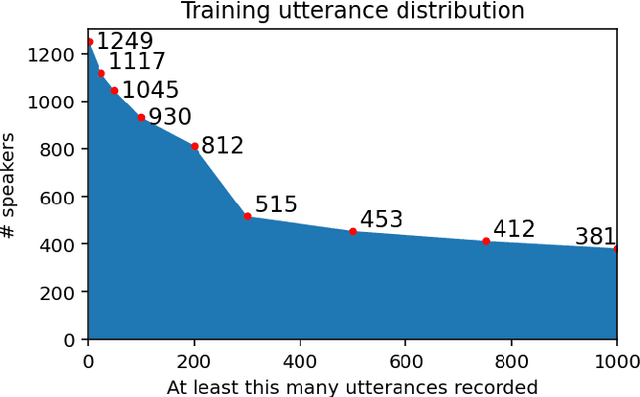
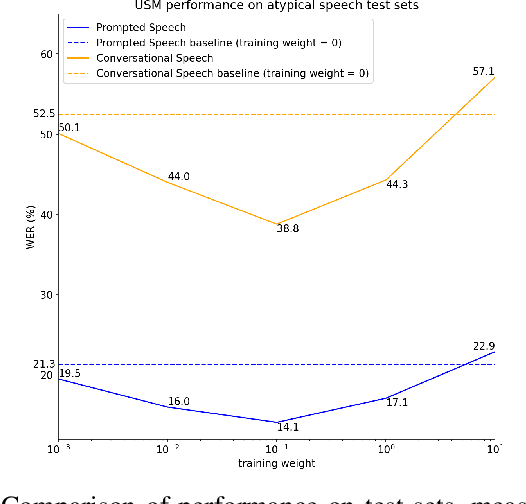
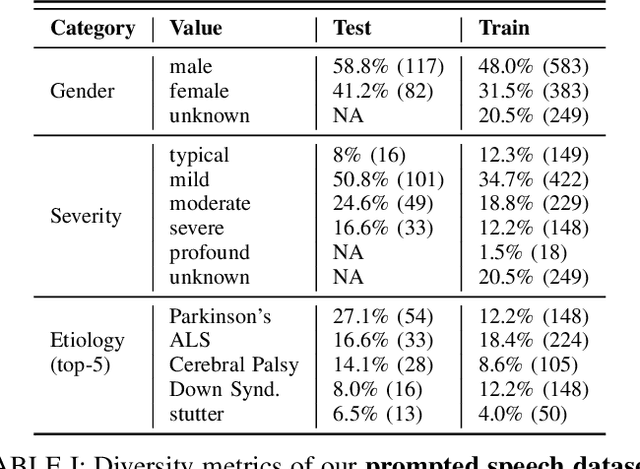
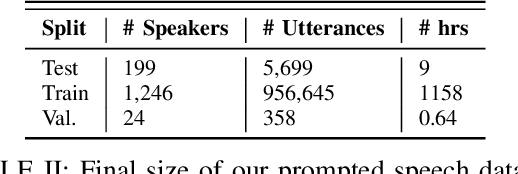
This study investigates the impact of integrating a dataset of disordered speech recordings ($\sim$1,000 hours) into the fine-tuning of a near state-of-the-art ASR baseline system. Contrary to what one might expect, despite the data being less than 1% of the training data of the ASR system, we find a considerable improvement in disordered speech recognition accuracy. Specifically, we observe a 33% improvement on prompted speech, and a 26% improvement on a newly gathered spontaneous, conversational dataset of disordered speech. Importantly, there is no significant performance decline on standard speech recognition benchmarks. Further, we observe that the proposed tuning strategy helps close the gap between the baseline system and personalized models by 64% highlighting the significant progress as well as the room for improvement. Given the substantial benefits of our findings, this experiment suggests that from a fairness perspective, incorporating a small fraction of high quality disordered speech data in a training recipe is an easy step that could be done to make speech technology more accessible for users with speech disabilities.
SPIQA: A Dataset for Multimodal Question Answering on Scientific Papers
Jul 12, 2024
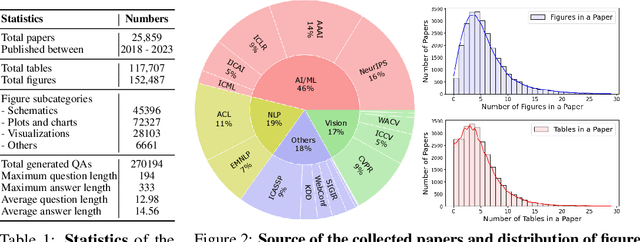

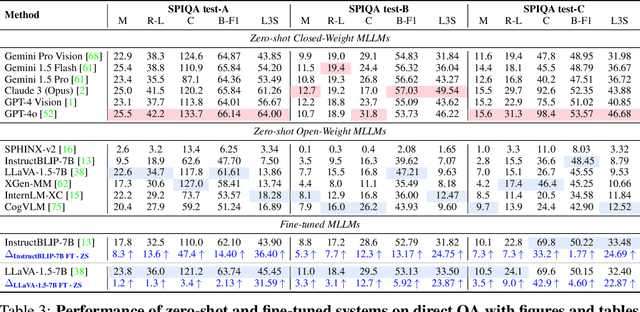
Seeking answers to questions within long scientific research articles is a crucial area of study that aids readers in quickly addressing their inquiries. However, existing question-answering (QA) datasets based on scientific papers are limited in scale and focus solely on textual content. To address this limitation, we introduce SPIQA (Scientific Paper Image Question Answering), the first large-scale QA dataset specifically designed to interpret complex figures and tables within the context of scientific research articles across various domains of computer science. Leveraging the breadth of expertise and ability of multimodal large language models (MLLMs) to understand figures, we employ automatic and manual curation to create the dataset. We craft an information-seeking task involving multiple images that cover a wide variety of plots, charts, tables, schematic diagrams, and result visualizations. SPIQA comprises 270K questions divided into training, validation, and three different evaluation splits. Through extensive experiments with 12 prominent foundational models, we evaluate the ability of current multimodal systems to comprehend the nuanced aspects of research articles. Additionally, we propose a Chain-of-Thought (CoT) evaluation strategy with in-context retrieval that allows fine-grained, step-by-step assessment and improves model performance. We further explore the upper bounds of performance enhancement with additional textual information, highlighting its promising potential for future research and the dataset's impact on revolutionizing how we interact with scientific literature.
A Design Space for Intelligent and Interactive Writing Assistants
Mar 26, 2024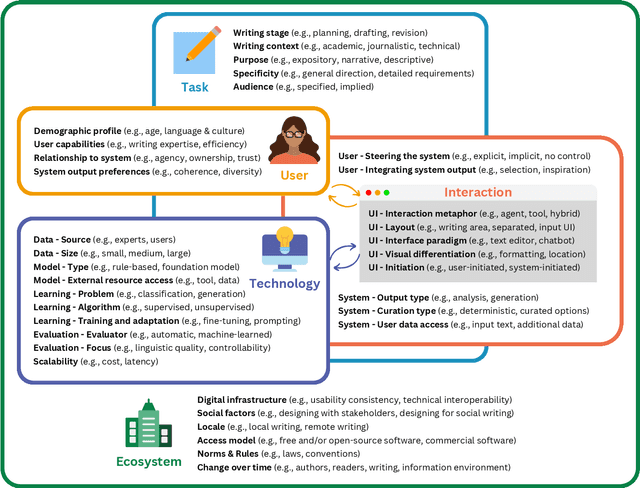
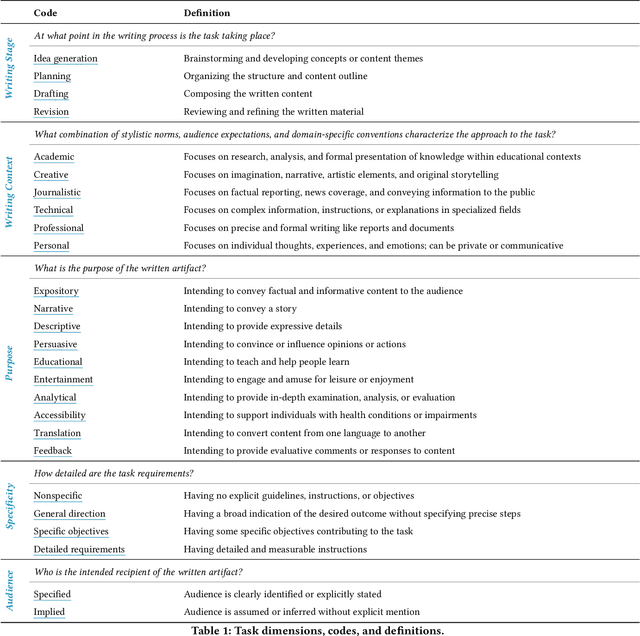
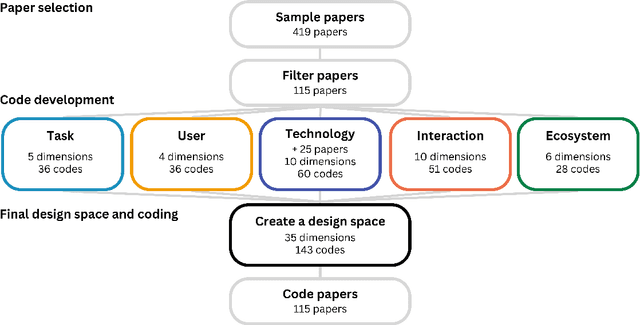
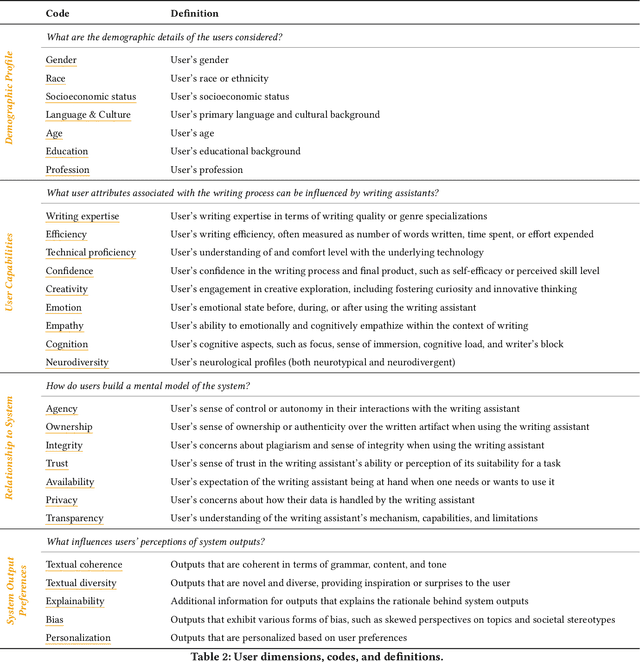
In our era of rapid technological advancement, the research landscape for writing assistants has become increasingly fragmented across various research communities. We seek to address this challenge by proposing a design space as a structured way to examine and explore the multidimensional space of intelligent and interactive writing assistants. Through a large community collaboration, we explore five aspects of writing assistants: task, user, technology, interaction, and ecosystem. Within each aspect, we define dimensions (i.e., fundamental components of an aspect) and codes (i.e., potential options for each dimension) by systematically reviewing 115 papers. Our design space aims to offer researchers and designers a practical tool to navigate, comprehend, and compare the various possibilities of writing assistants, and aid in the envisioning and design of new writing assistants.
Quantum Many-Body Physics Calculations with Large Language Models
Mar 05, 2024
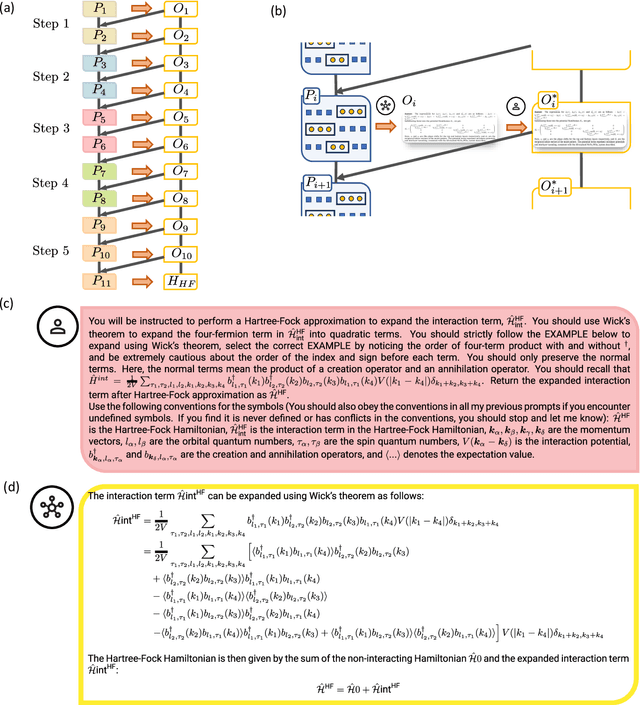
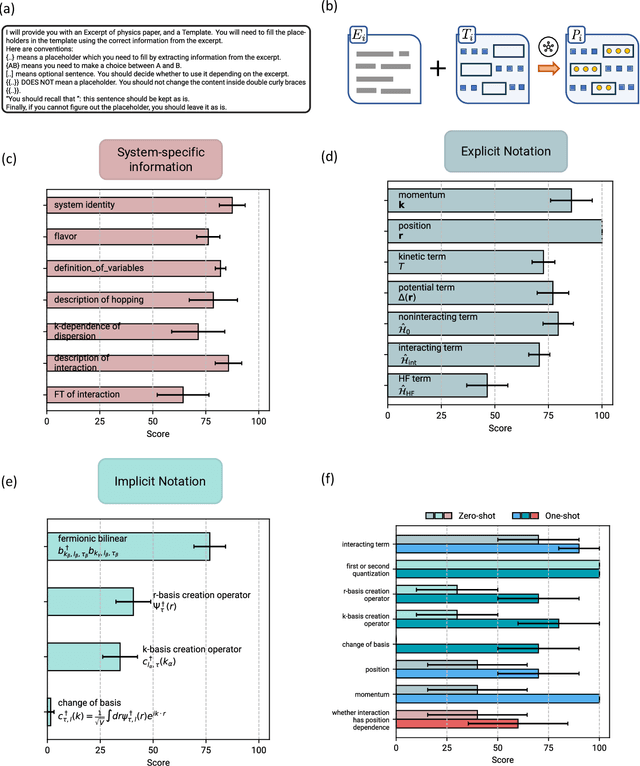
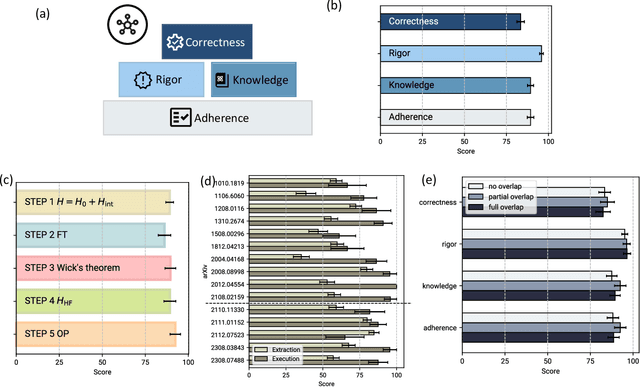
Large language models (LLMs) have demonstrated an unprecedented ability to perform complex tasks in multiple domains, including mathematical and scientific reasoning. We demonstrate that with carefully designed prompts, LLMs can accurately carry out key calculations in research papers in theoretical physics. We focus on a broadly used approximation method in quantum physics: the Hartree-Fock method, requiring an analytic multi-step calculation deriving approximate Hamiltonian and corresponding self-consistency equations. To carry out the calculations using LLMs, we design multi-step prompt templates that break down the analytic calculation into standardized steps with placeholders for problem-specific information. We evaluate GPT-4's performance in executing the calculation for 15 research papers from the past decade, demonstrating that, with correction of intermediate steps, it can correctly derive the final Hartree-Fock Hamiltonian in 13 cases and makes minor errors in 2 cases. Aggregating across all research papers, we find an average score of 87.5 (out of 100) on the execution of individual calculation steps. Overall, the requisite skill for doing these calculations is at the graduate level in quantum condensed matter theory. We further use LLMs to mitigate the two primary bottlenecks in this evaluation process: (i) extracting information from papers to fill in templates and (ii) automatic scoring of the calculation steps, demonstrating good results in both cases. The strong performance is the first step for developing algorithms that automatically explore theoretical hypotheses at an unprecedented scale.
Parameter Efficient Tuning Allows Scalable Personalization of LLMs for Text Entry: A Case Study on Abbreviation Expansion
Dec 21, 2023Abbreviation expansion is a strategy used to speed up communication by limiting the amount of typing and using a language model to suggest expansions. Here we look at personalizing a Large Language Model's (LLM) suggestions based on prior conversations to enhance the relevance of predictions, particularly when the user data is small (~1000 samples). Specifically, we compare fine-tuning, prompt-tuning, and retrieval augmented generation of expanded text suggestions for abbreviated inputs. Our case study with a deployed 8B parameter LLM on a real user living with ALS, and experiments on movie character personalization indicates that (1) customization may be necessary in some scenarios and prompt-tuning generalizes well to those, (2) fine-tuning on in-domain data (with as few as 600 samples) still shows some gains, however (3) retrieval augmented few-shot selection also outperforms fine-tuning. (4) Parameter efficient tuning allows for efficient and scalable personalization. For prompt-tuning, we also find that initializing the learned "soft-prompts" to user relevant concept tokens leads to higher accuracy than random initialization.
Using Large Language Models to Accelerate Communication for Users with Severe Motor Impairments
Dec 03, 2023



Finding ways to accelerate text input for individuals with profound motor impairments has been a long-standing area of research. Closing the speed gap for augmentative and alternative communication (AAC) devices such as eye-tracking keyboards is important for improving the quality of life for such individuals. Recent advances in neural networks of natural language pose new opportunities for re-thinking strategies and user interfaces for enhanced text-entry for AAC users. In this paper, we present SpeakFaster, consisting of large language models (LLMs) and a co-designed user interface for text entry in a highly-abbreviated form, allowing saving 57% more motor actions than traditional predictive keyboards in offline simulation. A pilot study with 19 non-AAC participants typing on a mobile device by hand demonstrated gains in motor savings in line with the offline simulation, while introducing relatively small effects on overall typing speed. Lab and field testing on two eye-gaze typing users with amyotrophic lateral sclerosis (ALS) demonstrated text-entry rates 29-60% faster than traditional baselines, due to significant saving of expensive keystrokes achieved through phrase and word predictions from context-aware LLMs. These findings provide a strong foundation for further exploration of substantially-accelerated text communication for motor-impaired users and demonstrate a direction for applying LLMs to text-based user interfaces.