 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Capacitive Touch Images Enhance Mobile Keyboard Decoding?
Oct 03, 2024Capacitive touch sensors capture the two-dimensional spatial profile (referred to as a touch heatmap) of a finger's contact with a mobile touchscreen. However, the research and design of touchscreen mobile keyboards -- one of the most speed and accuracy demanding touch interfaces -- has focused on the location of the touch centroid derived from the touch image heatmap as the input, discarding the rest of the raw spatial signals. In this paper, we investigate whether touch heatmaps can be leveraged to further improve the tap decoding accuracy for mobile touchscreen keyboards. Specifically, we developed and evaluated machine-learning models that interpret user taps by using the centroids and/or the heatmaps as their input and studied the contribution of the heatmaps to model performance. The results show that adding the heatmap into the input feature set led to 21.4% relative reduction of character error rates on average, compared to using the centroid alone. Furthermore, we conducted a live user study with the centroid-based and heatmap-based decoders built into Pixel 6 Pro devices and observed lower error rate, faster typing speed, and higher self-reported satisfaction score based on the heatmap-based decoder than the centroid-based decoder. These findings underline the promise of utilizing touch heatmaps for improving typing experience in mobile keyboards.
Proofread: Fixes All Errors with One Tap
Jun 06, 2024The impressive capabilities in Large Language Models (LLMs) provide a powerful approach to reimagine users' typing experience. This paper demonstrates Proofread, a novel Gboard feature powered by a server-side LLM in Gboard, enabling seamless sentence-level and paragraph-level corrections with a single tap. We describe the complete system in this paper, from data generation, metrics design to model tuning and deployment. To obtain models with sufficient quality, we implement a careful data synthetic pipeline tailored to online use cases, design multifaceted metrics, employ a two-stage tuning approach to acquire the dedicated LLM for the feature: the Supervised Fine Tuning (SFT) for foundational quality, followed by the Reinforcement Learning (RL) tuning approach for targeted refinement. Specifically, we find sequential tuning on Rewrite and proofread tasks yields the best quality in SFT stage, and propose global and direct rewards in the RL tuning stage to seek further improvement. Extensive experiments on a human-labeled golden set showed our tuned PaLM2-XS model achieved 85.56\% good ratio. We launched the feature to Pixel 8 devices by serving the model on TPU v5 in Google Cloud, with thousands of daily active users. Serving latency was significantly reduced by quantization, bucket inference, text segmentation, and speculative decoding. Our demo could be seen in \href{https://youtu.be/4ZdcuiwFU7I}{Youtube}.
Parameter Efficient Tuning Allows Scalable Personalization of LLMs for Text Entry: A Case Study on Abbreviation Expansion
Dec 21, 2023Abbreviation expansion is a strategy used to speed up communication by limiting the amount of typing and using a language model to suggest expansions. Here we look at personalizing a Large Language Model's (LLM) suggestions based on prior conversations to enhance the relevance of predictions, particularly when the user data is small (~1000 samples). Specifically, we compare fine-tuning, prompt-tuning, and retrieval augmented generation of expanded text suggestions for abbreviated inputs. Our case study with a deployed 8B parameter LLM on a real user living with ALS, and experiments on movie character personalization indicates that (1) customization may be necessary in some scenarios and prompt-tuning generalizes well to those, (2) fine-tuning on in-domain data (with as few as 600 samples) still shows some gains, however (3) retrieval augmented few-shot selection also outperforms fine-tuning. (4) Parameter efficient tuning allows for efficient and scalable personalization. For prompt-tuning, we also find that initializing the learned "soft-prompts" to user relevant concept tokens leads to higher accuracy than random initialization.
Using Large Language Models to Accelerate Communication for Users with Severe Motor Impairments
Dec 03, 2023



Finding ways to accelerate text input for individuals with profound motor impairments has been a long-standing area of research. Closing the speed gap for augmentative and alternative communication (AAC) devices such as eye-tracking keyboards is important for improving the quality of life for such individuals. Recent advances in neural networks of natural language pose new opportunities for re-thinking strategies and user interfaces for enhanced text-entry for AAC users. In this paper, we present SpeakFaster, consisting of large language models (LLMs) and a co-designed user interface for text entry in a highly-abbreviated form, allowing saving 57% more motor actions than traditional predictive keyboards in offline simulation. A pilot study with 19 non-AAC participants typing on a mobile device by hand demonstrated gains in motor savings in line with the offline simulation, while introducing relatively small effects on overall typing speed. Lab and field testing on two eye-gaze typing users with amyotrophic lateral sclerosis (ALS) demonstrated text-entry rates 29-60% faster than traditional baselines, due to significant saving of expensive keystrokes achieved through phrase and word predictions from context-aware LLMs. These findings provide a strong foundation for further exploration of substantially-accelerated text communication for motor-impaired users and demonstrate a direction for applying LLMs to text-based user interfaces.
Context-Aware Abbreviation Expansion Using Large Language Models
May 11, 2022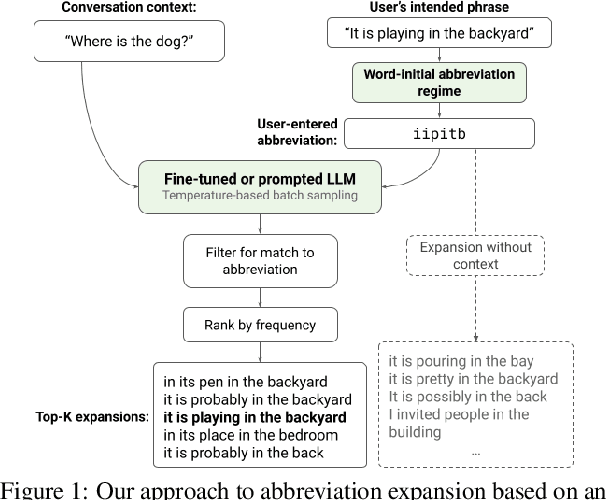


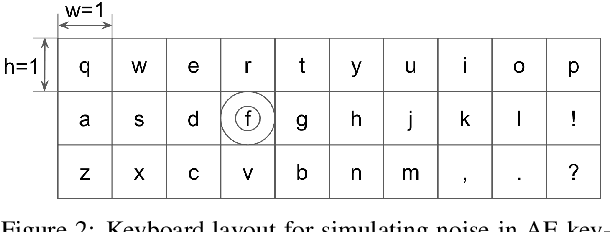
Motivated by the need for accelerating text entry in augmentative and alternative communication (AAC) for people with severe motor impairments, we propose a paradigm in which phrases are abbreviated aggressively as primarily word-initial letters. Our approach is to expand the abbreviations into full-phrase options by leveraging conversation context with the power of pretrained large language models (LLMs). Through zero-shot, few-shot, and fine-tuning experiments on four public conversation datasets, we show that for replies to the initial turn of a dialog, an LLM with 64B parameters is able to exactly expand over 70% of phrases with abbreviation length up to 10, leading to an effective keystroke saving rate of up to about 77% on these exact expansions. Including a small amount of context in the form of a single conversation turn more than doubles abbreviation expansion accuracies compared to having no context, an effect that is more pronounced for longer phrases. Additionally, the robustness of models against typo noise can be enhanced through fine-tuning on noisy data.
TensorFlow Eager: A Multi-Stage, Python-Embedded DSL for Machine Learning
Feb 27, 2019

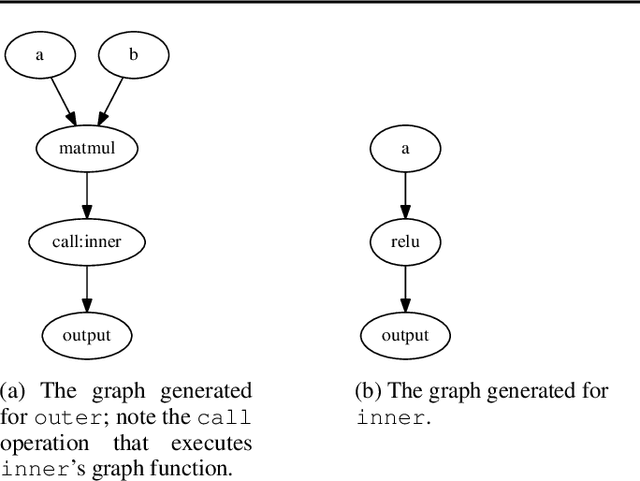
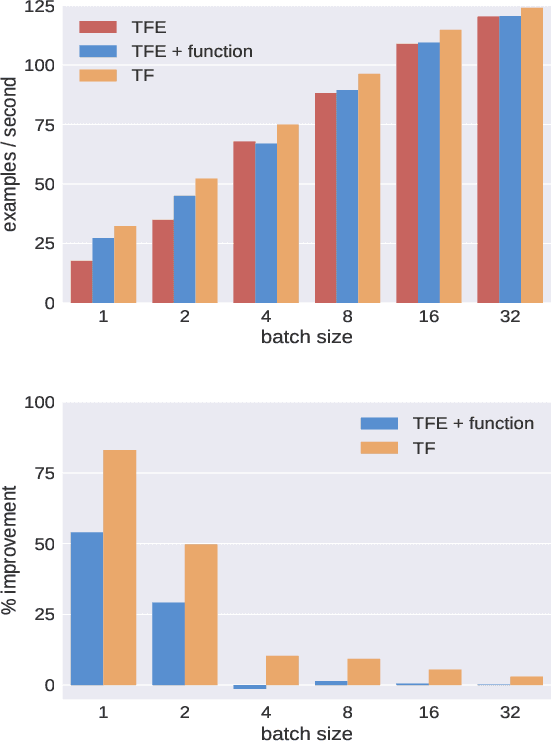
TensorFlow Eager is a multi-stage, Python-embedded domain-specific language for hardware-accelerated machine learning, suitable for both interactive research and production. TensorFlow, which TensorFlow Eager extends, requires users to represent computations as dataflow graphs; this permits compiler optimizations and simplifies deployment but hinders rapid prototyping and run-time dynamism. TensorFlow Eager eliminates these usability costs without sacrificing the benefits furnished by graphs: It provides an imperative front-end to TensorFlow that executes operations immediately and a JIT tracer that translates Python functions composed of TensorFlow operations into executable dataflow graphs. TensorFlow Eager thus offers a multi-stage programming model that makes it easy to interpolate between imperative and staged execution in a single package.
TensorFlow.js: Machine Learning for the Web and Beyond
Jan 16, 2019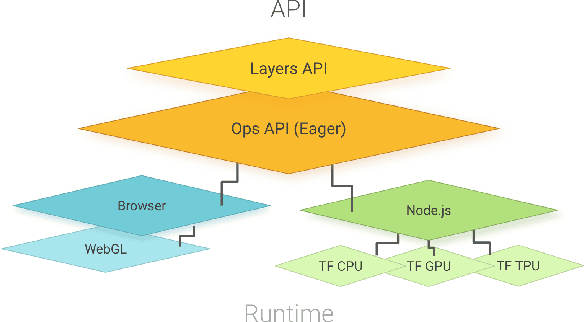
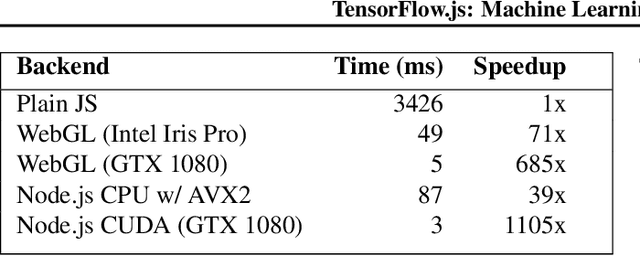


TensorFlow.js is a library for building and executing machine learning algorithms in JavaScript. TensorFlow.js models run in a web browser and in the Node.js environment. The library is part of the TensorFlow ecosystem, providing a set of APIs that are compatible with those in Python, allowing models to be ported between the Python and JavaScript ecosystems. TensorFlow.js has empowered a new set of developers from the extensive JavaScript community to build and deploy machine learning models and enabled new classes of on-device computation. This paper describes the design, API, and implementation of TensorFlow.js, and highlights some of the impactful use cases.