 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Interspeech 2025 Speech Accessibility Project Challenge
Jul 29, 2025While the last decade has witnessed significant advancements in Automatic Speech Recognition (ASR) systems, performance of these systems for individuals with speech disabilities remains inadequate, partly due to limited public training data. To bridge this gap, the 2025 Interspeech Speech Accessibility Project (SAP) Challenge was launched, utilizing over 400 hours of SAP data collected and transcribed from more than 500 individuals with diverse speech disabilities. Hosted on EvalAI and leveraging the remote evaluation pipeline, the SAP Challenge evaluates submissions based on Word Error Rate and Semantic Score. Consequently, 12 out of 22 valid teams outperformed the whisper-large-v2 baseline in terms of WER, while 17 teams surpassed the baseline on SemScore. Notably, the top team achieved the lowest WER of 8.11\%, and the highest SemScore of 88.44\% at the same time, setting new benchmarks for future ASR systems in recognizing impaired speech.
A Cookbook for Community-driven Data Collection of Impaired Speech in LowResource Languages
Jul 03, 2025This study presents an approach for collecting speech samples to build Automatic Speech Recognition (ASR) models for impaired speech, particularly, low-resource languages. It aims to democratize ASR technology and data collection by developing a "cookbook" of best practices and training for community-driven data collection and ASR model building. As a proof-of-concept, this study curated the first open-source dataset of impaired speech in Akan: a widely spoken indigenous language in Ghana. The study involved participants from diverse backgrounds with speech impairments. The resulting dataset, along with the cookbook and open-source tools, are publicly available to enable researchers and practitioners to create inclusive ASR technologies tailored to the unique needs of speech impaired individuals. In addition, this study presents the initial results of fine-tuning open-source ASR models to better recognize impaired speech in Akan.
Have LLMs Made Active Learning Obsolete? Surveying the NLP Community
Mar 12, 2025



Supervised learning relies on annotated data, which is expensive to obtain. A longstanding strategy to reduce annotation costs is active learning, an iterative process, in which a human annotates only data instances deemed informative by a model. Large language models (LLMs) have pushed the effectiveness of active learning, but have also improved methods such as few- or zero-shot learning, and text synthesis - thereby introducing potential alternatives. This raises the question: has active learning become obsolete? To answer this fully, we must look beyond literature to practical experiences. We conduct an online survey in the NLP community to collect previously intangible insights on the perceived relevance of data annotation, particularly focusing on active learning, including best practices, obstacles and expected future developments. Our findings show that annotated data remains a key factor, and active learning continues to be relevant. While the majority of active learning users find it effective, a comparison with a community survey from over a decade ago reveals persistent challenges: setup complexity, estimation of cost reduction, and tooling. We publish an anonymized version of the collected dataset
Towards a Single ASR Model That Generalizes to Disordered Speech
Dec 26, 2024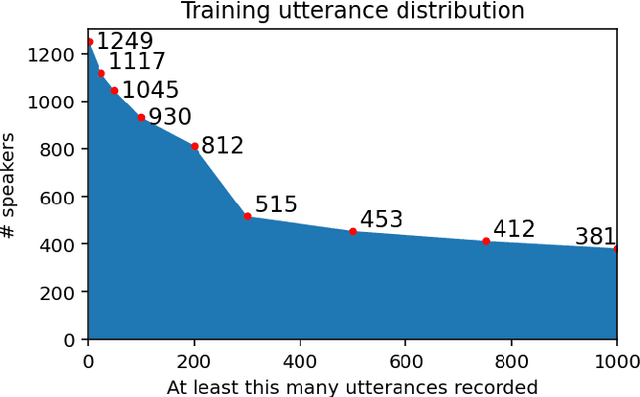
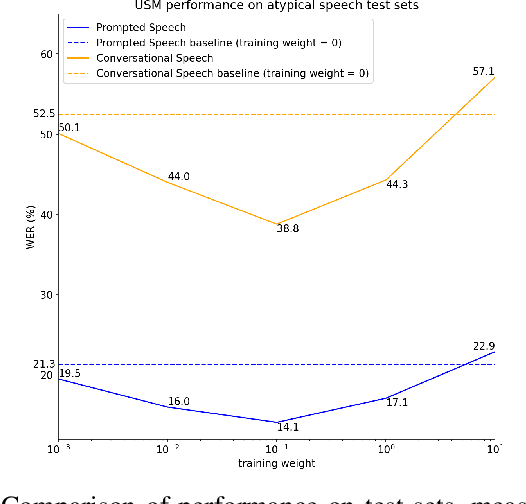
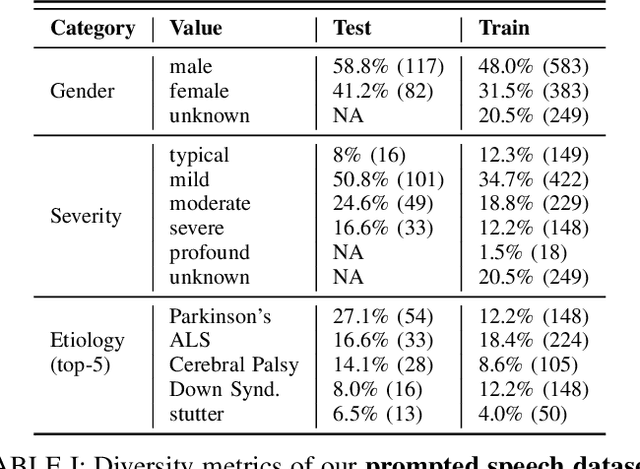
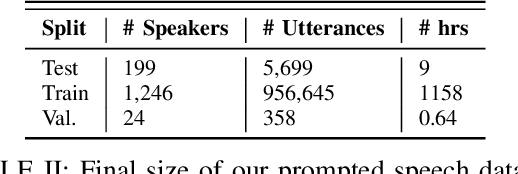
This study investigates the impact of integrating a dataset of disordered speech recordings ($\sim$1,000 hours) into the fine-tuning of a near state-of-the-art ASR baseline system. Contrary to what one might expect, despite the data being less than 1% of the training data of the ASR system, we find a considerable improvement in disordered speech recognition accuracy. Specifically, we observe a 33% improvement on prompted speech, and a 26% improvement on a newly gathered spontaneous, conversational dataset of disordered speech. Importantly, there is no significant performance decline on standard speech recognition benchmarks. Further, we observe that the proposed tuning strategy helps close the gap between the baseline system and personalized models by 64% highlighting the significant progress as well as the room for improvement. Given the substantial benefits of our findings, this experiment suggests that from a fairness perspective, incorporating a small fraction of high quality disordered speech data in a training recipe is an easy step that could be done to make speech technology more accessible for users with speech disabilities.
Learnings from curating a trustworthy, well-annotated, and useful dataset of disordered English speech
Sep 13, 2024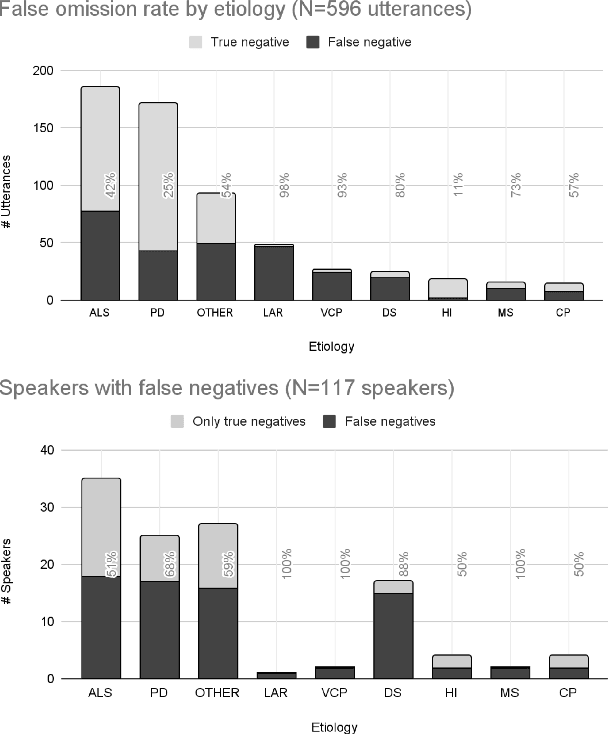
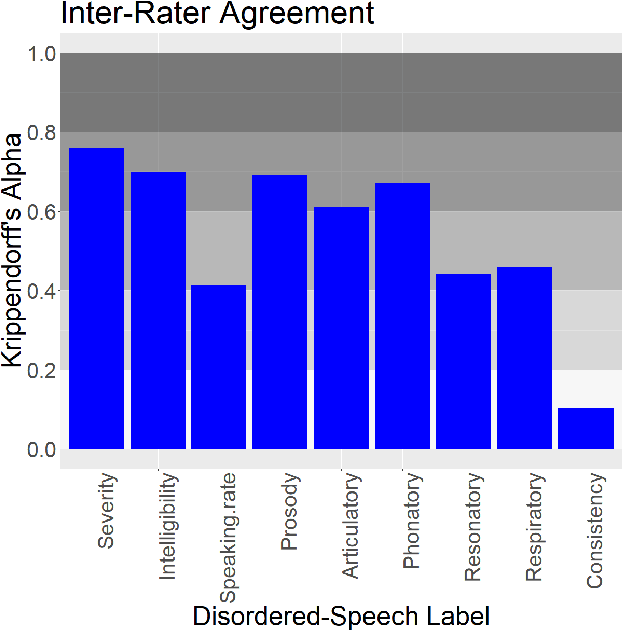
Project Euphonia, a Google initiative, is dedicated to improving automatic speech recognition (ASR) of disordered speech. A central objective of the project is to create a large, high-quality, and diverse speech corpus. This report describes the project's latest advancements in data collection and annotation methodologies, such as expanding speaker diversity in the database, adding human-reviewed transcript corrections and audio quality tags to 350K (of the 1.2M total) audio recordings, and amassing a comprehensive set of metadata (including more than 40 speech characteristic labels) for over 75\% of the speakers in the database. We report on the impact of transcript corrections on our machine-learning (ML) research, inter-rater variability of assessments of disordered speech patterns, and our rationale for gathering speech metadata. We also consider the limitations of using automated off-the-shelf annotation methods for assessing disordered speech.
Detecting Hallucination and Coverage Errors in Retrieval Augmented Generation for Controversial Topics
Mar 13, 2024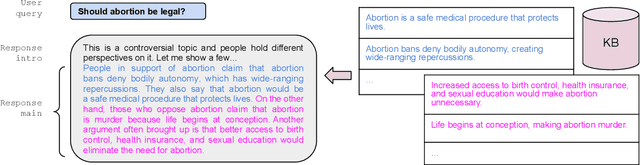



We explore a strategy to handle controversial topics in LLM-based chatbots based on Wikipedia's Neutral Point of View (NPOV) principle: acknowledge the absence of a single true answer and surface multiple perspectives. We frame this as retrieval augmented generation, where perspectives are retrieved from a knowledge base and the LLM is tasked with generating a fluent and faithful response from the given perspectives. As a starting point, we use a deterministic retrieval system and then focus on common LLM failure modes that arise during this approach to text generation, namely hallucination and coverage errors. We propose and evaluate three methods to detect such errors based on (1) word-overlap, (2) salience, and (3) LLM-based classifiers. Our results demonstrate that LLM-based classifiers, even when trained only on synthetic errors, achieve high error detection performance, with ROC AUC scores of 95.3% for hallucination and 90.5% for coverage error detection on unambiguous error cases. We show that when no training data is available, our other methods still yield good results on hallucination (84.0%) and coverage error (85.2%) detection.
Parameter Efficient Tuning Allows Scalable Personalization of LLMs for Text Entry: A Case Study on Abbreviation Expansion
Dec 21, 2023Abbreviation expansion is a strategy used to speed up communication by limiting the amount of typing and using a language model to suggest expansions. Here we look at personalizing a Large Language Model's (LLM) suggestions based on prior conversations to enhance the relevance of predictions, particularly when the user data is small (~1000 samples). Specifically, we compare fine-tuning, prompt-tuning, and retrieval augmented generation of expanded text suggestions for abbreviated inputs. Our case study with a deployed 8B parameter LLM on a real user living with ALS, and experiments on movie character personalization indicates that (1) customization may be necessary in some scenarios and prompt-tuning generalizes well to those, (2) fine-tuning on in-domain data (with as few as 600 samples) still shows some gains, however (3) retrieval augmented few-shot selection also outperforms fine-tuning. (4) Parameter efficient tuning allows for efficient and scalable personalization. For prompt-tuning, we also find that initializing the learned "soft-prompts" to user relevant concept tokens leads to higher accuracy than random initialization.
Using Large Language Models to Accelerate Communication for Users with Severe Motor Impairments
Dec 03, 2023



Finding ways to accelerate text input for individuals with profound motor impairments has been a long-standing area of research. Closing the speed gap for augmentative and alternative communication (AAC) devices such as eye-tracking keyboards is important for improving the quality of life for such individuals. Recent advances in neural networks of natural language pose new opportunities for re-thinking strategies and user interfaces for enhanced text-entry for AAC users. In this paper, we present SpeakFaster, consisting of large language models (LLMs) and a co-designed user interface for text entry in a highly-abbreviated form, allowing saving 57% more motor actions than traditional predictive keyboards in offline simulation. A pilot study with 19 non-AAC participants typing on a mobile device by hand demonstrated gains in motor savings in line with the offline simulation, while introducing relatively small effects on overall typing speed. Lab and field testing on two eye-gaze typing users with amyotrophic lateral sclerosis (ALS) demonstrated text-entry rates 29-60% faster than traditional baselines, due to significant saving of expensive keystrokes achieved through phrase and word predictions from context-aware LLMs. These findings provide a strong foundation for further exploration of substantially-accelerated text communication for motor-impaired users and demonstrate a direction for applying LLMs to text-based user interfaces.
Towards Agile Text Classifiers for Everyone
Feb 13, 2023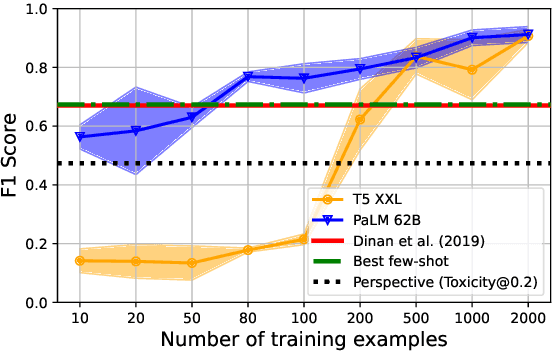
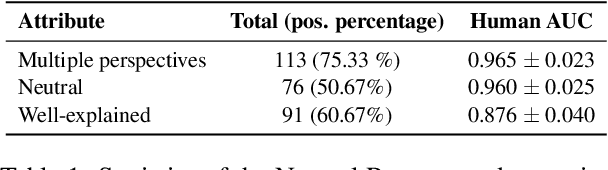
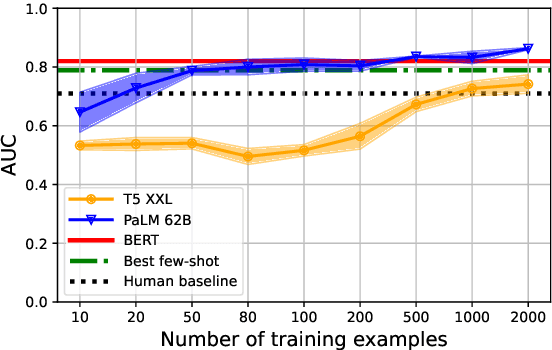
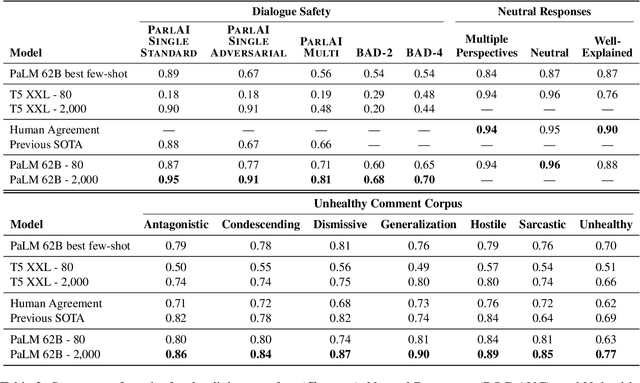
Text-based safety classifiers are widely used for content moderation and increasingly to tune generative language model behavior - a topic of growing concern for the safety of digital assistants and chatbots. However, different policies require different classifiers, and safety policies themselves improve from iteration and adaptation. This paper introduces and evaluates methods for agile text classification, whereby classifiers are trained using small, targeted datasets that can be quickly developed for a particular policy. Experimenting with 7 datasets from three safety-related domains, comprising 15 annotation schemes, led to our key finding: prompt-tuning large language models, like PaLM 62B, with a labeled dataset of as few as 80 examples can achieve state-of-the-art performance. We argue that this enables a paradigm shift for text classification, especially for models supporting safer online discourse. Instead of collecting millions of examples to attempt to create universal safety classifiers over months or years, classifiers could be tuned using small datasets, created by individuals or small organizations, tailored for specific use cases, and iterated on and adapted in the time-span of a day.
An analysis of degenerating speech due to progressive dysarthria on ASR performance
Oct 31, 2022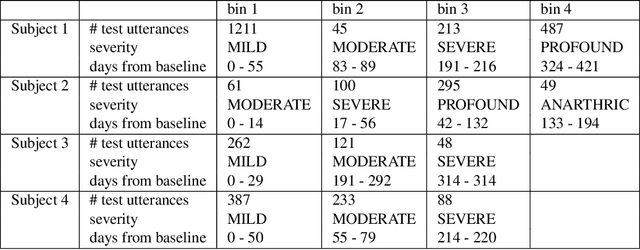
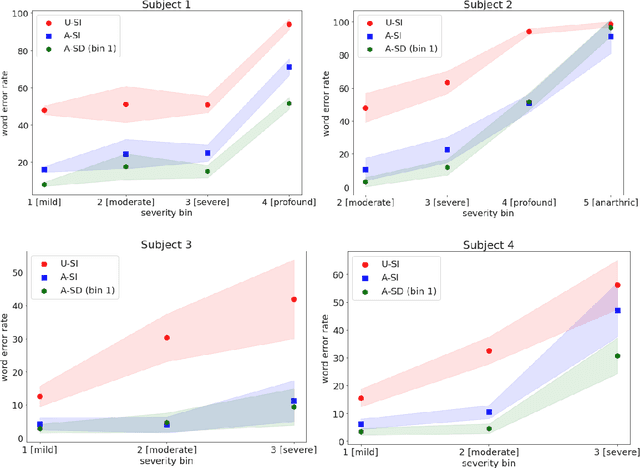

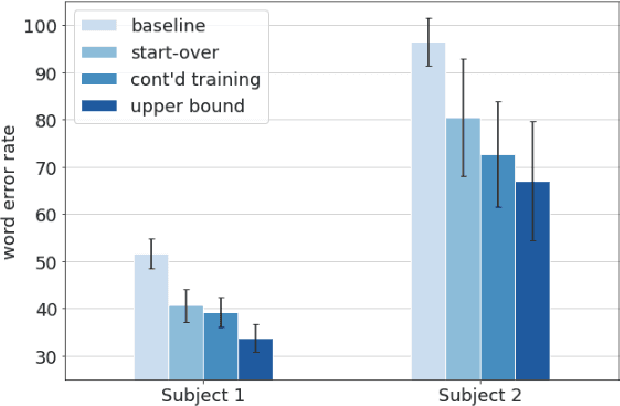
Although personalized automatic speech recognition (ASR) models have recently been designed to recognize even severely impaired speech, model performance may degrade over time for persons with degenerating speech. The aims of this study were to (1) analyze the change of performance of ASR over time in individuals with degrading speech, and (2) explore mitigation strategies to optimize recognition throughout disease progression. Speech was recorded by four individuals with degrading speech due to amyotrophic lateral sclerosis (ALS). Word error rates (WER) across recording sessions were computed for three ASR models: Unadapted Speaker Independent (U-SI), Adapted Speaker Independent (A-SI), and Adapted Speaker Dependent (A-SD or personalized). The performance of all three models degraded significantly over time as speech became more impaired, but the performance of the A-SD model improved markedly when it was updated with recordings from the severe stages of speech progression. Recording additional utterances early in the disease before speech degraded significantly did not improve the performance of A-SD models. Overall, our findings emphasize the importance of continuous recording (and model retraining) when providing personalized models for individuals with progressive speech impairments.