 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearnings from curating a trustworthy, well-annotated, and useful dataset of disordered English speech
Sep 13, 2024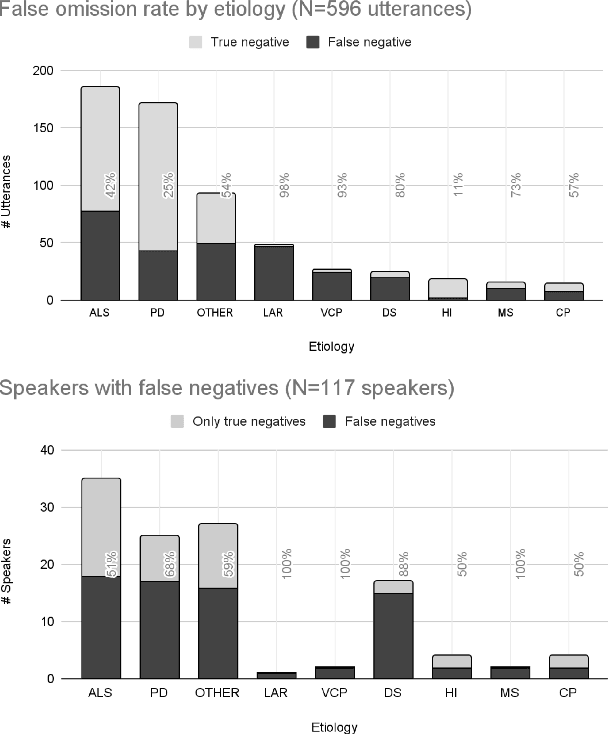
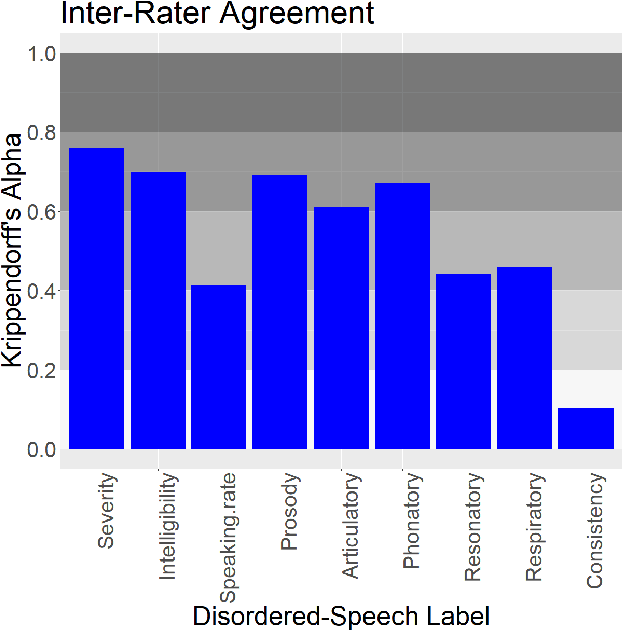
Project Euphonia, a Google initiative, is dedicated to improving automatic speech recognition (ASR) of disordered speech. A central objective of the project is to create a large, high-quality, and diverse speech corpus. This report describes the project's latest advancements in data collection and annotation methodologies, such as expanding speaker diversity in the database, adding human-reviewed transcript corrections and audio quality tags to 350K (of the 1.2M total) audio recordings, and amassing a comprehensive set of metadata (including more than 40 speech characteristic labels) for over 75\% of the speakers in the database. We report on the impact of transcript corrections on our machine-learning (ML) research, inter-rater variability of assessments of disordered speech patterns, and our rationale for gathering speech metadata. We also consider the limitations of using automated off-the-shelf annotation methods for assessing disordered speech.
An analysis of degenerating speech due to progressive dysarthria on ASR performance
Oct 31, 2022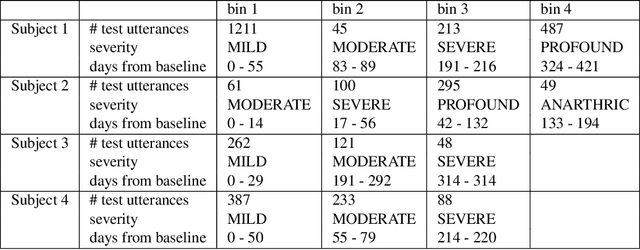
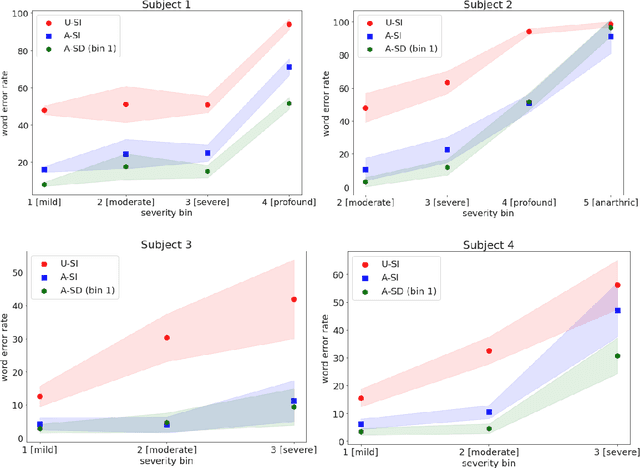

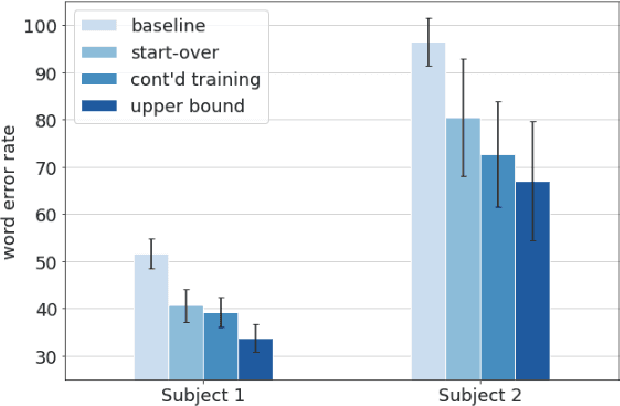
Although personalized automatic speech recognition (ASR) models have recently been designed to recognize even severely impaired speech, model performance may degrade over time for persons with degenerating speech. The aims of this study were to (1) analyze the change of performance of ASR over time in individuals with degrading speech, and (2) explore mitigation strategies to optimize recognition throughout disease progression. Speech was recorded by four individuals with degrading speech due to amyotrophic lateral sclerosis (ALS). Word error rates (WER) across recording sessions were computed for three ASR models: Unadapted Speaker Independent (U-SI), Adapted Speaker Independent (A-SI), and Adapted Speaker Dependent (A-SD or personalized). The performance of all three models degraded significantly over time as speech became more impaired, but the performance of the A-SD model improved markedly when it was updated with recordings from the severe stages of speech progression. Recording additional utterances early in the disease before speech degraded significantly did not improve the performance of A-SD models. Overall, our findings emphasize the importance of continuous recording (and model retraining) when providing personalized models for individuals with progressive speech impairments.
Longitudinal Acoustic Speech Tracking Following Pediatric Traumatic Brain Injury
Sep 09, 2022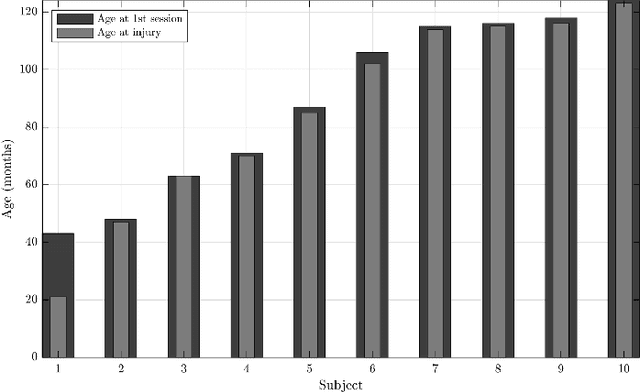
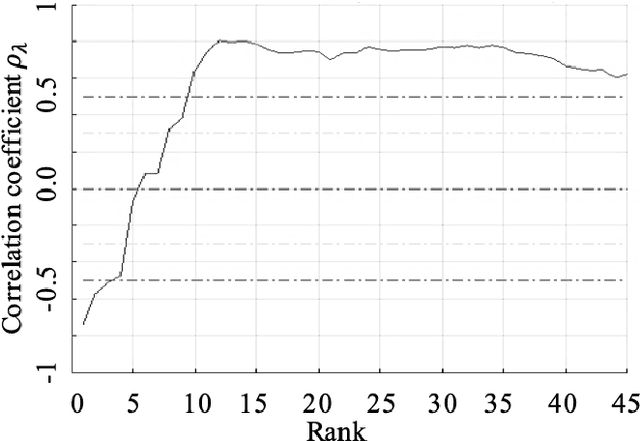
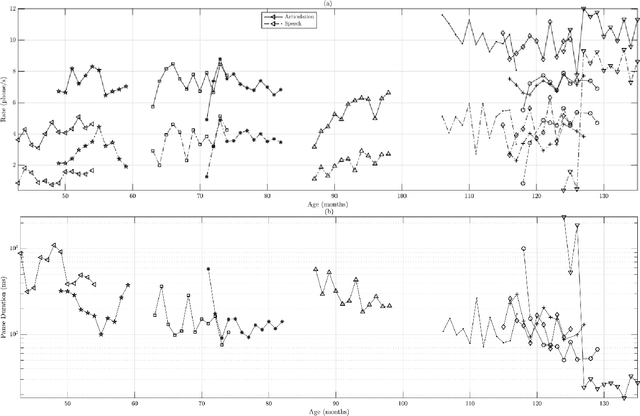
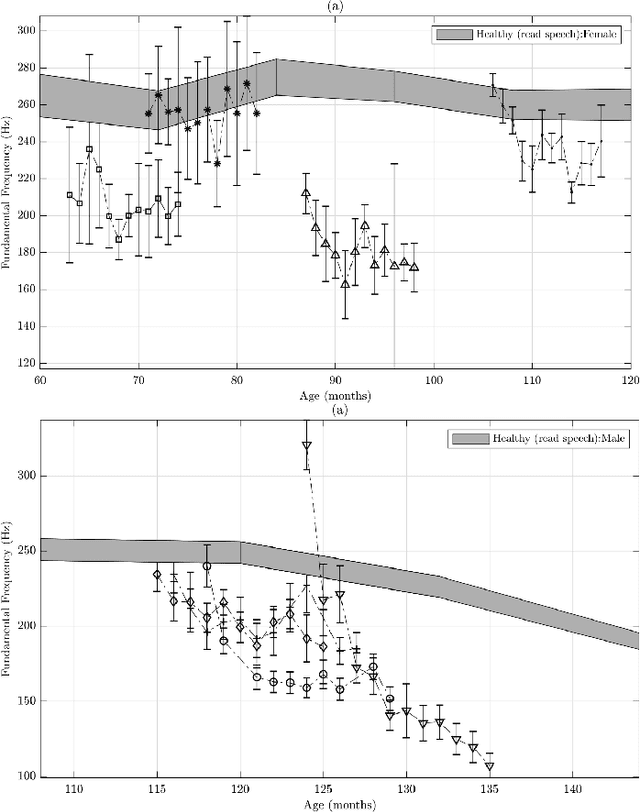
Recommendations for common outcome measures following pediatric traumatic brain injury (TBI) support the integration of instrumental measurements alongside perceptual assessment in recovery and treatment plans. A comprehensive set of sensitive, robust and non-invasive measurements is therefore essential in assessing variations in speech characteristics over time following pediatric TBI. In this article, we study the changes in the acoustic speech patterns of a pediatric cohort of ten subjects diagnosed with severe TBI. We extract a diverse set of both well-known and novel acoustic features from child speech recorded throughout the year after the child produced intelligible words. These features are analyzed individually and by speech subsystem, within-subject and across the cohort. As a group, older children exhibit highly significant (p<0.01) increases in pitch variation and phoneme diversity, shortened pause length, and steadying articulation rate variability. Younger children exhibit similar steadied rate variability alongside an increase in formant-based articulation complexity. Correlation analysis of the feature set with age and comparisons to normative developmental data confirm that age at injury plays a significant role in framing the recovery trajectory. Nearly all speech features significantly change (p<0.05) for the cohort as a whole, confirming that acoustic measures supplementing perceptual assessment are needed to identify efficacious treatment targets for speech therapy following TBI.
Comparing Supervised Models And Learned Speech Representations For Classifying Intelligibility Of Disordered Speech On Selected Phrases
Jul 08, 2021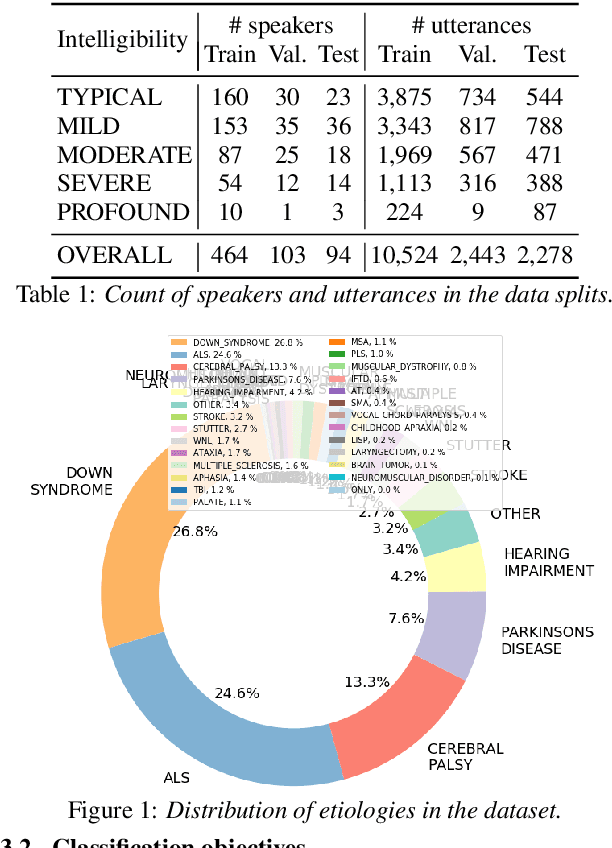
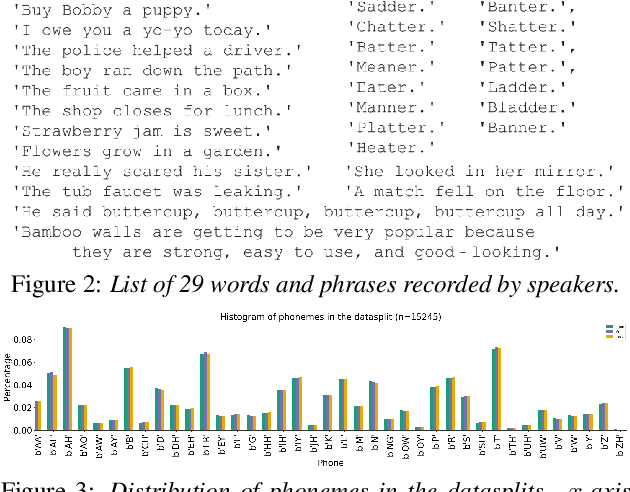
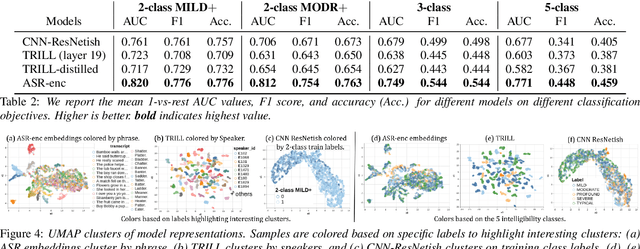
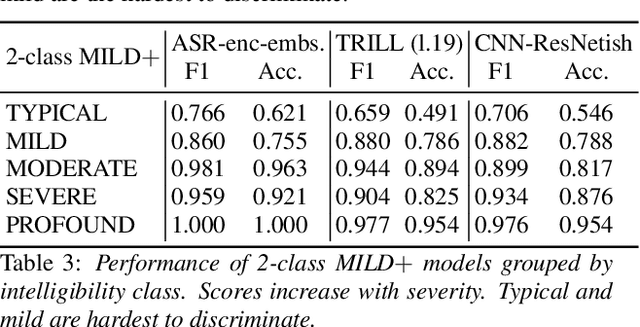
Automatic classification of disordered speech can provide an objective tool for identifying the presence and severity of speech impairment. Classification approaches can also help identify hard-to-recognize speech samples to teach ASR systems about the variable manifestations of impaired speech. Here, we develop and compare different deep learning techniques to classify the intelligibility of disordered speech on selected phrases. We collected samples from a diverse set of 661 speakers with a variety of self-reported disorders speaking 29 words or phrases, which were rated by speech-language pathologists for their overall intelligibility using a five-point Likert scale. We then evaluated classifiers developed using 3 approaches: (1) a convolutional neural network (CNN) trained for the task, (2) classifiers trained on non-semantic speech representations from CNNs that used an unsupervised objective [1], and (3) classifiers trained on the acoustic (encoder) embeddings from an ASR system trained on typical speech [2]. We found that the ASR encoder's embeddings considerably outperform the other two on detecting and classifying disordered speech. Further analysis shows that the ASR embeddings cluster speech by the spoken phrase, while the non-semantic embeddings cluster speech by speaker. Also, longer phrases are more indicative of intelligibility deficits than single words.
Investigating the Utility of Multimodal Conversational Technology and Audiovisual Analytic Measures for the Assessment and Monitoring of Amyotrophic Lateral Sclerosis at Scale
Apr 15, 2021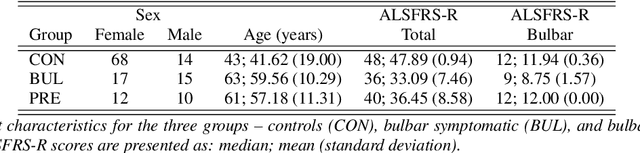
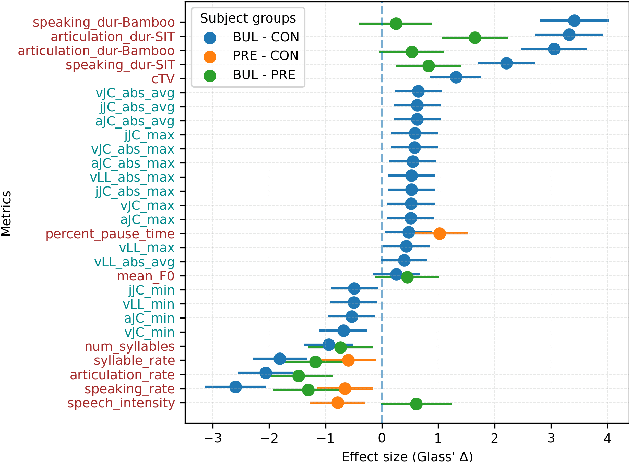

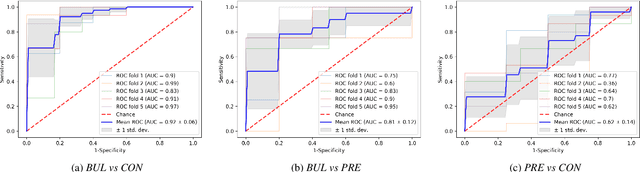
We propose a cloud-based multimodal dialog platform for the remote assessment and monitoring of Amyotrophic Lateral Sclerosis (ALS) at scale. This paper presents our vision, technology setup, and an initial investigation of the efficacy of the various acoustic and visual speech metrics automatically extracted by the platform. 82 healthy controls and 54 people with ALS (pALS) were instructed to interact with the platform and completed a battery of speaking tasks designed to probe the acoustic, articulatory, phonatory, and respiratory aspects of their speech. We find that multiple acoustic (rate, duration, voicing) and visual (higher order statistics of the jaw and lip) speech metrics show statistically significant differences between controls, bulbar symptomatic and bulbar pre-symptomatic patients. We report on the sensitivity and specificity of these metrics using five-fold cross-validation. We further conducted a LASSO-LARS regression analysis to uncover the relative contributions of various acoustic and visual features in predicting the severity of patients' ALS (as measured by their self-reported ALSFRS-R scores). Our results provide encouraging evidence of the utility of automatically extracted audiovisual analytics for scalable remote patient assessment and monitoring in ALS.
A Sparse Non-negative Matrix Factorization Framework for Identifying Functional Units of Tongue Behavior from MRI
Sep 29, 2018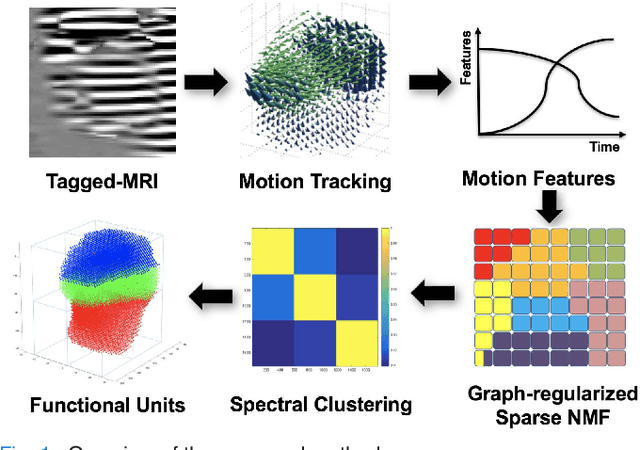
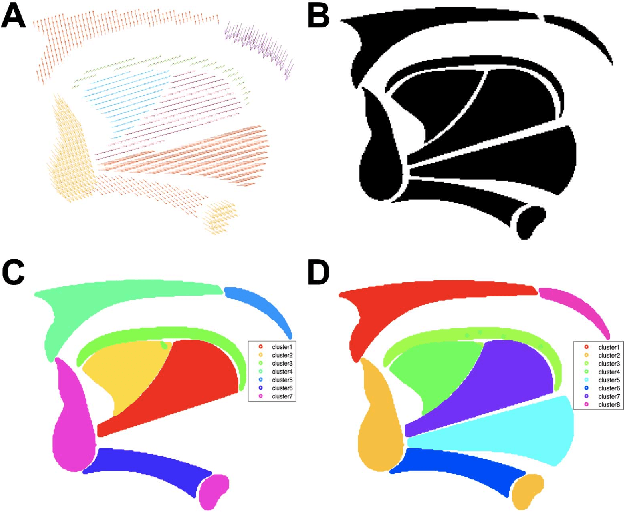
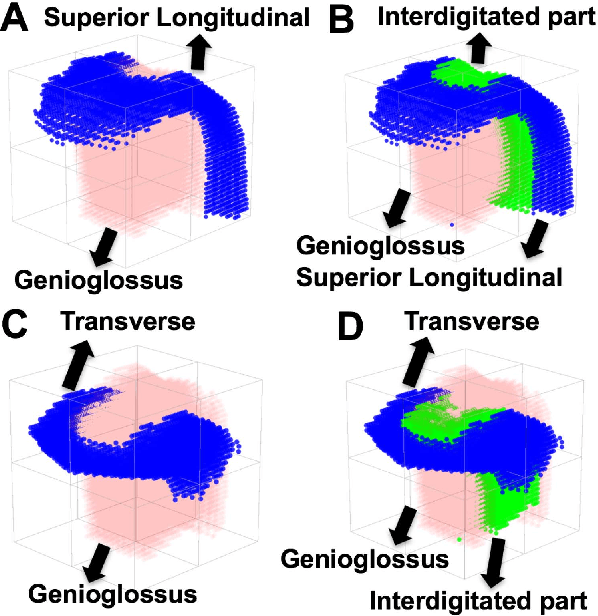
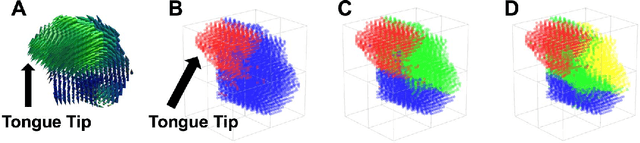
Muscle coordination patterns of lingual behaviors are synergies generated by deforming local muscle groups in a variety of ways. Functional units are functional muscle groups of local structural elements within the tongue that compress, expand, and move in a cohesive and consistent manner. Identifying the functional units using tagged-Magnetic Resonance Imaging (MRI) sheds light on the mechanisms of normal and pathological muscle coordination patterns, yielding improvement in surgical planning, treatment, or rehabilitation procedures. Here, to mine this information, we propose a matrix factorization and probabilistic graphical model framework to produce building blocks and their associated weighting map using motion quantities extracted from tagged-MRI. Our tagged-MRI imaging and accurate voxel-level tracking provide previously unavailable internal tongue motion patterns, thus revealing the inner workings of the tongue during speech or other lingual behaviors. We then employ spectral clustering on the weighting map to identify the cohesive regions defined by the tongue motion that may involve multiple or undocumented regions. To evaluate our method, we perform a series of experiments. We first use two-dimensional images and synthetic data to demonstrate the accuracy of our method. We then use three-dimensional synthetic and \textit{in vivo} tongue motion data using protrusion and simple speech tasks to identify subject-specific and data-driven functional units of the tongue in localized regions.