 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Utility of Multimodal Conversational Technology and Audiovisual Analytic Measures for the Assessment and Monitoring of Amyotrophic Lateral Sclerosis at Scale
Apr 15, 2021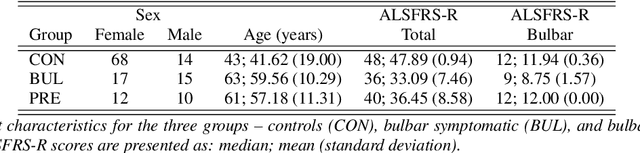
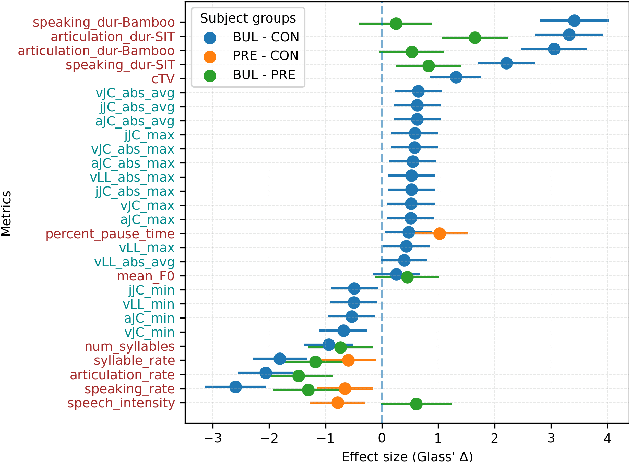

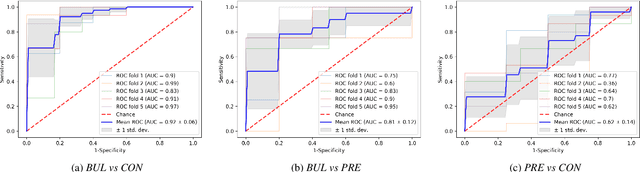
We propose a cloud-based multimodal dialog platform for the remote assessment and monitoring of Amyotrophic Lateral Sclerosis (ALS) at scale. This paper presents our vision, technology setup, and an initial investigation of the efficacy of the various acoustic and visual speech metrics automatically extracted by the platform. 82 healthy controls and 54 people with ALS (pALS) were instructed to interact with the platform and completed a battery of speaking tasks designed to probe the acoustic, articulatory, phonatory, and respiratory aspects of their speech. We find that multiple acoustic (rate, duration, voicing) and visual (higher order statistics of the jaw and lip) speech metrics show statistically significant differences between controls, bulbar symptomatic and bulbar pre-symptomatic patients. We report on the sensitivity and specificity of these metrics using five-fold cross-validation. We further conducted a LASSO-LARS regression analysis to uncover the relative contributions of various acoustic and visual features in predicting the severity of patients' ALS (as measured by their self-reported ALSFRS-R scores). Our results provide encouraging evidence of the utility of automatically extracted audiovisual analytics for scalable remote patient assessment and monitoring in ALS.
Medical code prediction with multi-view convolution and description-regularized label-dependent attention
Nov 05, 2018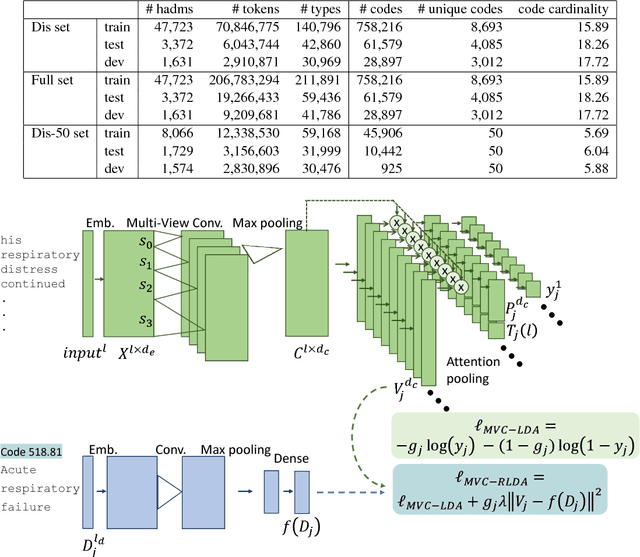

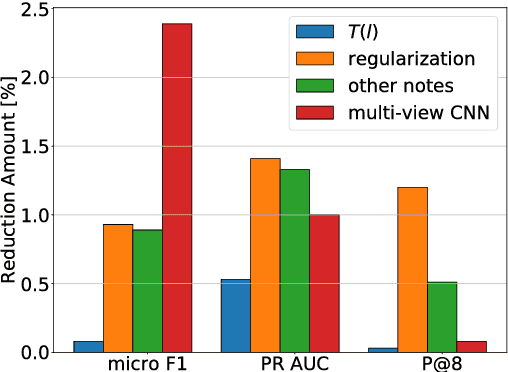
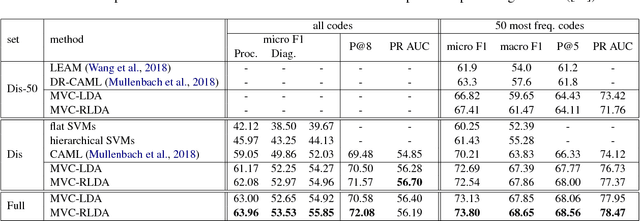
A ubiquitous task in processing electronic medical data is the assignment of standardized codes representing diagnoses and/or procedures to free-text documents such as medical reports. This is a difficult natural language processing task that requires parsing long, heterogeneous documents and selecting a set of appropriate codes from tens of thousands of possibilities---many of which have very few positive training samples. We present a deep learning system that advances the state of the art for the MIMIC-III dataset, achieving a new best micro F1-measure of 55.85\%, significantly outperforming the previous best result (Mullenbach et al. 2018). We achieve this through a number of enhancements, including two major novel contributions: multi-view convolutional channels, which effectively learn to adjust kernel sizes throughout the input; and attention regularization, mediated by natural-language code descriptions, which helps overcome sparsity for thousands of uncommon codes. These and other modifications are selected to address difficulties inherent to both automated coding specifically and deep learning generally. Finally, we investigate our accuracy results in detail to individually measure the impact of these contributions and point the way towards future algorithmic improvements.