 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedical code prediction with multi-view convolution and description-regularized label-dependent attention
Paper and Code
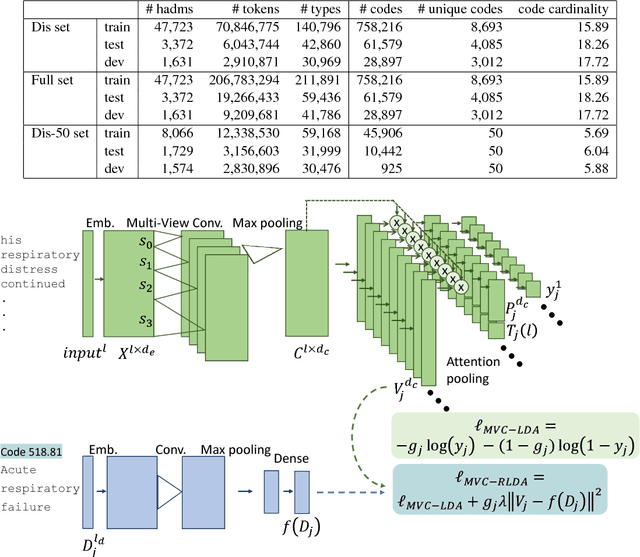

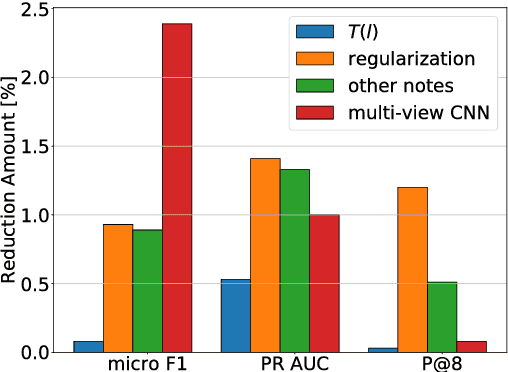
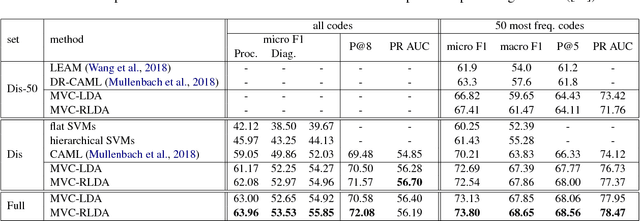
A ubiquitous task in processing electronic medical data is the assignment of standardized codes representing diagnoses and/or procedures to free-text documents such as medical reports. This is a difficult natural language processing task that requires parsing long, heterogeneous documents and selecting a set of appropriate codes from tens of thousands of possibilities---many of which have very few positive training samples. We present a deep learning system that advances the state of the art for the MIMIC-III dataset, achieving a new best micro F1-measure of 55.85\%, significantly outperforming the previous best result (Mullenbach et al. 2018). We achieve this through a number of enhancements, including two major novel contributions: multi-view convolutional channels, which effectively learn to adjust kernel sizes throughout the input; and attention regularization, mediated by natural-language code descriptions, which helps overcome sparsity for thousands of uncommon codes. These and other modifications are selected to address difficulties inherent to both automated coding specifically and deep learning generally. Finally, we investigate our accuracy results in detail to individually measure the impact of these contributions and point the way towards future algorithmic improvements.