 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEGA: Multimodal Alignment Aggregation and Distillation For Cinematic Video Segmentation
Aug 22, 2023



Previous research has studied the task of segmenting cinematic videos into scenes and into narrative acts. However, these studies have overlooked the essential task of multimodal alignment and fusion for effectively and efficiently processing long-form videos (>60min). In this paper, we introduce Multimodal alignmEnt aGgregation and distillAtion (MEGA) for cinematic long-video segmentation. MEGA tackles the challenge by leveraging multiple media modalities. The method coarsely aligns inputs of variable lengths and different modalities with alignment positional encoding. To maintain temporal synchronization while reducing computation, we further introduce an enhanced bottleneck fusion layer which uses temporal alignment. Additionally, MEGA employs a novel contrastive loss to synchronize and transfer labels across modalities, enabling act segmentation from labeled synopsis sentences on video shots. Our experimental results show that MEGA outperforms state-of-the-art methods on MovieNet dataset for scene segmentation (with an Average Precision improvement of +1.19%) and on TRIPOD dataset for act segmentation (with a Total Agreement improvement of +5.51%)
Generalized Zero-shot ICD Coding
Sep 28, 2019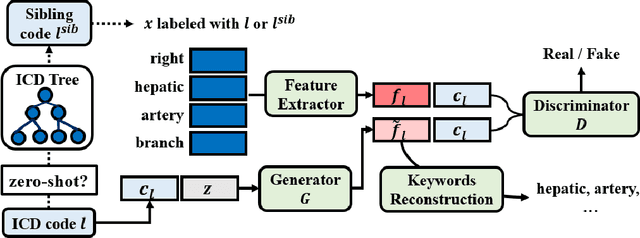

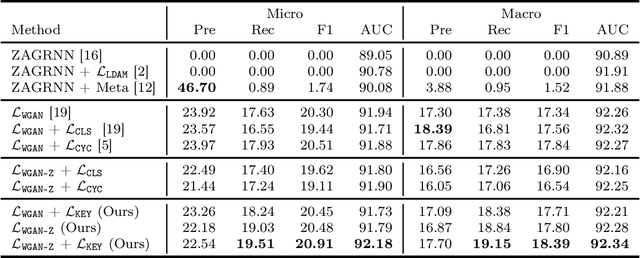
The International Classification of Diseases (ICD) is a list of classification codes for the diagnoses. Automatic ICD coding is in high demand as the manual coding can be labor-intensive and error-prone. It is a multi-label text classification task with extremely long-tailed label distribution, making it difficult to perform fine-grained classification on both frequent and zero-shot codes at the same time. In this paper, we propose a latent feature generation framework for generalized zero-shot ICD coding, where we aim to improve the prediction on codes that have no labeled data without compromising the performance on seen codes. Our framework generates pseudo features conditioned on the ICD code descriptions and exploits the ICD code hierarchical structure. To guarantee the semantic consistency between the generated features and real features, we reconstruct the keywords in the input documents that are related to the conditioned ICD codes. To the best of our knowledge, this works represents the first one that proposes an adversarial generative model for the generalized zero-shot learning on multi-label text classification. Extensive experiments demonstrate the effectiveness of our approach. On the public MIMIC-III dataset, our methods improve the F1 score from nearly 0 to 20.91% for the zero-shot codes, and increase the AUC score by 3% (absolute improvement) from previous state of the art. We also show that the framework improves the performance on few-shot codes.
Medical code prediction with multi-view convolution and description-regularized label-dependent attention
Nov 05, 2018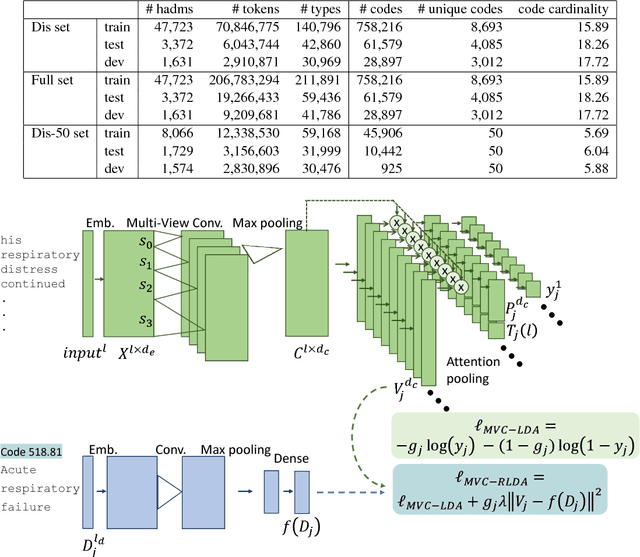

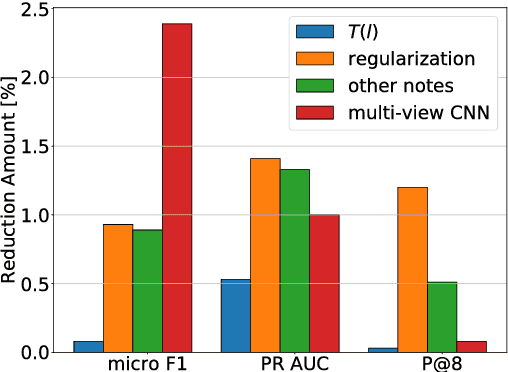
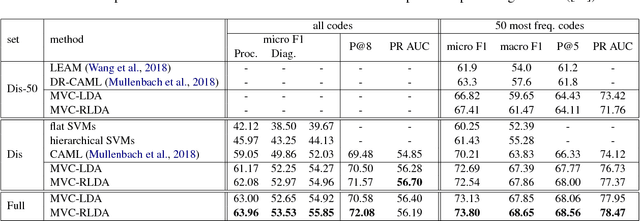
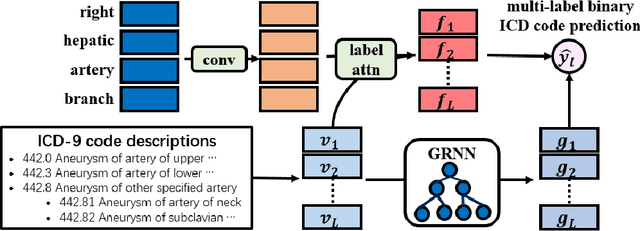
A ubiquitous task in processing electronic medical data is the assignment of standardized codes representing diagnoses and/or procedures to free-text documents such as medical reports. This is a difficult natural language processing task that requires parsing long, heterogeneous documents and selecting a set of appropriate codes from tens of thousands of possibilities---many of which have very few positive training samples. We present a deep learning system that advances the state of the art for the MIMIC-III dataset, achieving a new best micro F1-measure of 55.85\%, significantly outperforming the previous best result (Mullenbach et al. 2018). We achieve this through a number of enhancements, including two major novel contributions: multi-view convolutional channels, which effectively learn to adjust kernel sizes throughout the input; and attention regularization, mediated by natural-language code descriptions, which helps overcome sparsity for thousands of uncommon codes. These and other modifications are selected to address difficulties inherent to both automated coding specifically and deep learning generally. Finally, we investigate our accuracy results in detail to individually measure the impact of these contributions and point the way towards future algorithmic improvements.