 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Selection via Cross-Model Agreement using Canonical Correlation Analysis
Apr 01, 2026Modern vision pipelines increasingly rely on pretrained image encoders whose representations are reused across tasks and models, yet these representations are often overcomplete and model-specific. We propose a simple, training-free method to improve the efficiency of image representations via a post-hoc canonical correlation analysis (CCA) operator. By leveraging the shared structure between representations produced by two pre-trained image encoders, our method finds linear projections that serve as a principled form of representation selection and dimensionality reduction, retaining shared semantic content while discarding redundant dimensions. Unlike standard dimensionality reduction techniques such as PCA, which operate on a single embedding space, our approach leverages cross-model agreement to guide representation distillation and refinement. The technique allows representations to be reduced by more than 75% in dimensionality with improved downstream performance, or enhanced at fixed dimensionality via post-hoc representation transfer from larger or fine-tuned models. Empirical results on ImageNet-1k, CIFAR-100, MNIST, and additional benchmarks show consistent improvements over both baseline and PCA-projected representations, with accuracy gains of up to 12.6%.
Motion-Guided Masking for Spatiotemporal Representation Learning
Aug 24, 2023Several recent works have directly extended the image masked autoencoder (MAE) with random masking into video domain, achieving promising results. However, unlike images, both spatial and temporal information are important for video understanding. This suggests that the random masking strategy that is inherited from the image MAE is less effective for video MAE. This motivates the design of a novel masking algorithm that can more efficiently make use of video saliency. Specifically, we propose a motion-guided masking algorithm (MGM) which leverages motion vectors to guide the position of each mask over time. Crucially, these motion-based correspondences can be directly obtained from information stored in the compressed format of the video, which makes our method efficient and scalable. On two challenging large-scale video benchmarks (Kinetics-400 and Something-Something V2), we equip video MAE with our MGM and achieve up to +$1.3\%$ improvement compared to previous state-of-the-art methods. Additionally, our MGM achieves equivalent performance to previous video MAE using up to $66\%$ fewer training epochs. Lastly, we show that MGM generalizes better to downstream transfer learning and domain adaptation tasks on the UCF101, HMDB51, and Diving48 datasets, achieving up to +$4.9\%$ improvement compared to baseline methods.
MEGA: Multimodal Alignment Aggregation and Distillation For Cinematic Video Segmentation
Aug 22, 2023



Previous research has studied the task of segmenting cinematic videos into scenes and into narrative acts. However, these studies have overlooked the essential task of multimodal alignment and fusion for effectively and efficiently processing long-form videos (>60min). In this paper, we introduce Multimodal alignmEnt aGgregation and distillAtion (MEGA) for cinematic long-video segmentation. MEGA tackles the challenge by leveraging multiple media modalities. The method coarsely aligns inputs of variable lengths and different modalities with alignment positional encoding. To maintain temporal synchronization while reducing computation, we further introduce an enhanced bottleneck fusion layer which uses temporal alignment. Additionally, MEGA employs a novel contrastive loss to synchronize and transfer labels across modalities, enabling act segmentation from labeled synopsis sentences on video shots. Our experimental results show that MEGA outperforms state-of-the-art methods on MovieNet dataset for scene segmentation (with an Average Precision improvement of +1.19%) and on TRIPOD dataset for act segmentation (with a Total Agreement improvement of +5.51%)
Model-based Reconstruction for Multi-Frequency Collimated Beam Ultrasound Systems
Nov 29, 2022Collimated beam ultrasound systems are a technology for imaging inside multi-layered structures such as geothermal wells. These systems work by using a collimated narrow-band ultrasound transmitter that can penetrate through multiple layers of heterogeneous material. A series of measurements can then be made at multiple transmit frequencies. However, commonly used reconstruction algorithms such as Synthetic Aperture Focusing Technique (SAFT) tend to produce poor quality reconstructions for these systems both because they do not model collimated beam systems and they do not jointly reconstruct the multiple frequencies. In this paper, we propose a multi-frequency ultrasound model-based iterative reconstruction (UMBIR) algorithm designed for multi-frequency collimated beam ultrasound systems. The combined system targets reflective imaging of heterogeneous, multi-layered structures. For each transmitted frequency band, we introduce a physics-based forward model to accurately account for the propagation of the collimated narrow-band ultrasonic beam through the multi-layered media. We then show how the joint multi-frequency UMBIR reconstruction can be computed by modeling the direct arrival signals, detector noise, and incorporating a spatially varying image prior. Results using both simulated and experimental data indicate that multi-frequency UMBIR reconstruction yields much higher reconstruction quality than either single frequency UMBIR or SAFT.
Model-Based Reconstruction for Collimated Beam Ultrasound Systems
Feb 20, 2022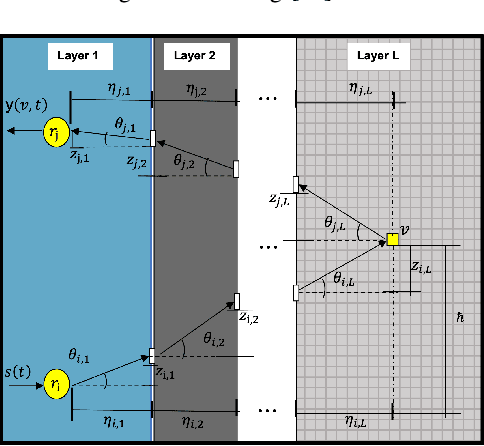
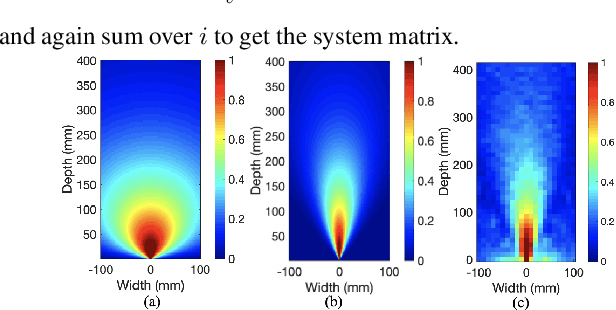
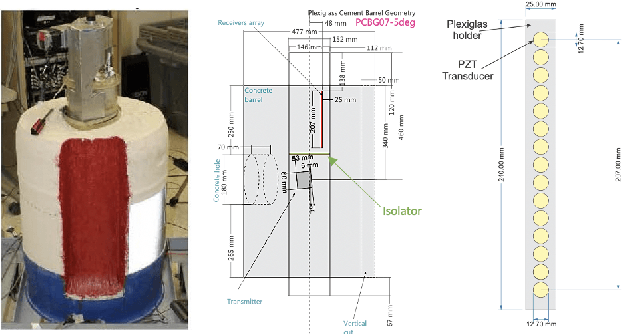
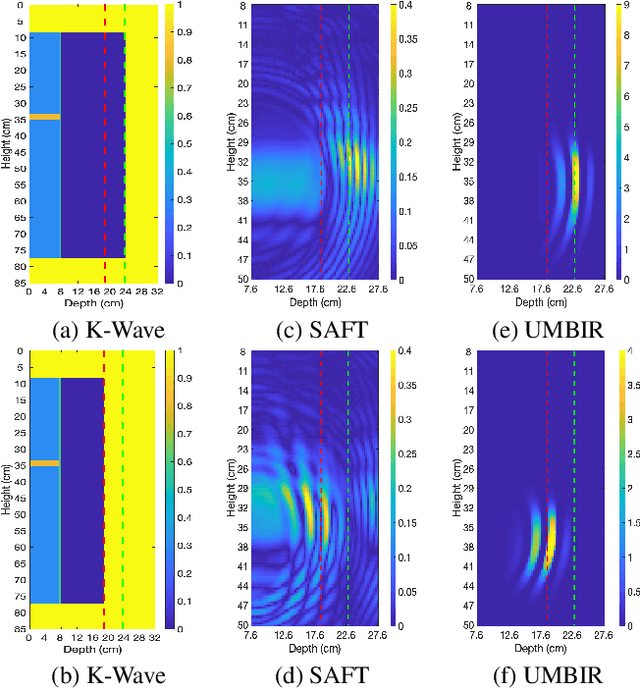
Collimated beam ultrasound systems are a novel technology for imaging inside multi-layered structures such as geothermal wells. Such systems include a transmitter and multiple receivers to capture reflected signals. Common algorithms for ultrasound reconstruction use delay-and-sum (DAS) approaches; these have low computational complexity but produce inaccurate images in the presence of complex structures and specialized geometries such as collimated beams. In this paper, we propose a multi-layer, ultrasonic, model-based iterative reconstruction algorithm designed for collimated beam systems. We introduce a physics-based forward model to accurately account for the propagation of a collimated ultrasonic beam in multi-layer media and describe an efficient implementation using binary search. We model direct arrival signals, detector noise, and a spatially varying image prior, then cast the reconstruction as a maximum a posteriori estimation problem. Using simulated and experimental data we obtain significantly fewer artifacts relative to DAS while running in near real time using commodity compute resources.
The Mertens Unrolled Network : A High Dynamic Range Fusion Neural Network for Through the Windshield Driver Recognition
Feb 27, 2020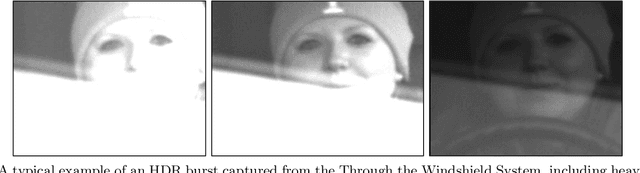



Face recognition of vehicle occupants through windshields in unconstrained environments poses a number of unique challenges ranging from glare, poor illumination, driver pose and motion blur. In this paper, we further develop the hardware and software components of a custom vehicle imaging system to better overcome these challenges. After the build out of a physical prototype system that performs High Dynamic Range (HDR) imaging, we collect a small dataset of through-windshield image captures of known drivers. We then re-formulate the classical Mertens-Kautz-Van Reeth HDR fusion algorithm as a pre-initialized neural network, which we name the Mertens Unrolled Network (MU-Net), for the purpose of fine-tuning the HDR output of through-windshield images. Reconstructed faces from this novel HDR method are then evaluated and compared against other traditional and experimental HDR methods in a pre-trained state-of-the-art (SOTA) facial recognition pipeline, verifying the efficacy of our approach.