 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFindings of the MAGMaR 2026 Shared Task
Jun 10, 2026This overview paper presents the results of the shared task for the second workshop on Multimodal Augmented Generation via Multimodal Retrieval (MAGMaR). In this shared task participants submitted systems focused on either (i) video retrieval or (ii) grounded generation of articles given retrieved videos. Teams could submit to either task. For the retrieval task, we had 2 participating teams that submitted a total of 17 systems -- all of which beat a baseline derived from the winner of last year's shared task. On the generation side, we had 4 teams submit 16 systems. All teams had at least one generated report that was labeled the best by a human annotator.
Expanding on the BRIAR Dataset: A Comprehensive Whole Body Biometric Recognition Resource at Extreme Distances and Real-World Scenarios (Collections 1-4)
Jan 23, 2025
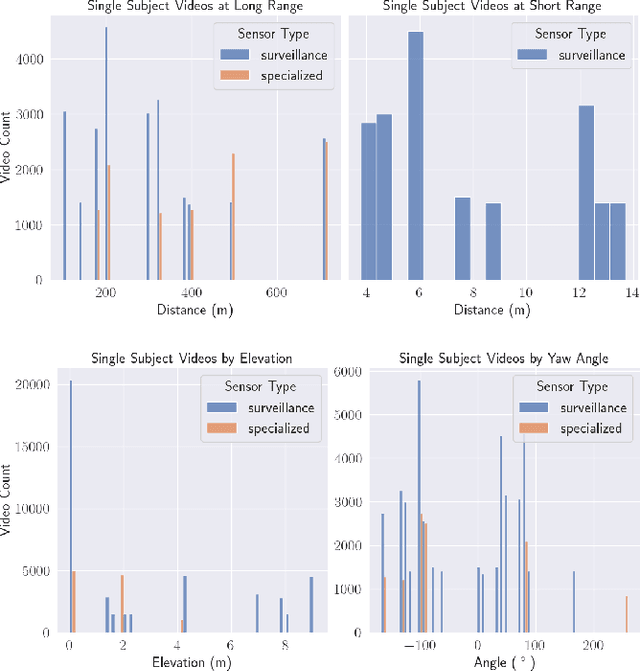

The state-of-the-art in biometric recognition algorithms and operational systems has advanced quickly in recent years providing high accuracy and robustness in more challenging collection environments and consumer applications. However, the technology still suffers greatly when applied to non-conventional settings such as those seen when performing identification at extreme distances or from elevated cameras on buildings or mounted to UAVs. This paper summarizes an extension to the largest dataset currently focused on addressing these operational challenges, and describes its composition as well as methodologies of collection, curation, and annotation.
Long-Range Biometric Identification in Real World Scenarios: A Comprehensive Evaluation Framework Based on Missions
Sep 03, 2024
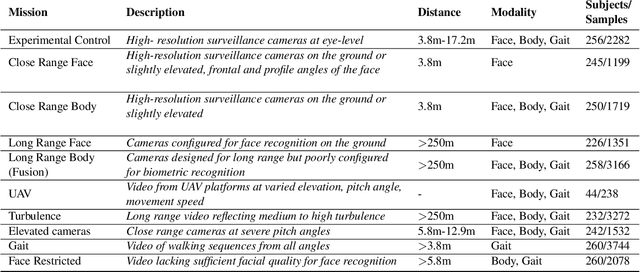
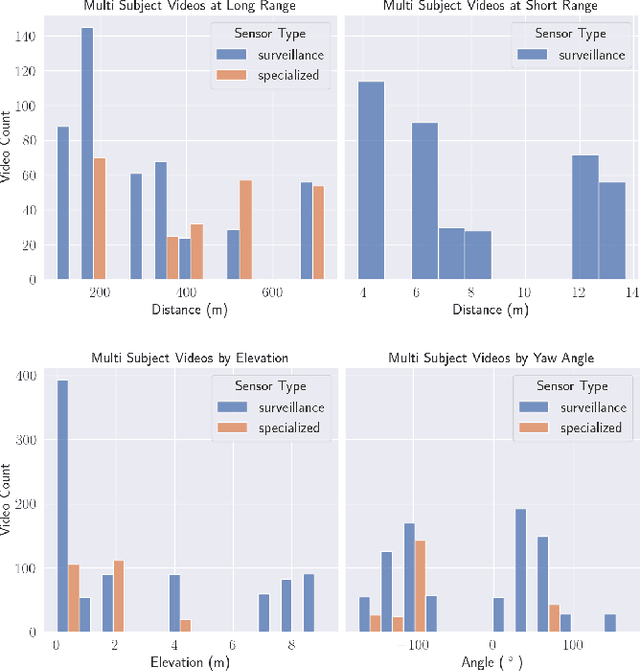
The considerable body of data available for evaluating biometric recognition systems in Research and Development (R\&D) environments has contributed to the increasingly common problem of target performance mismatch. Biometric algorithms are frequently tested against data that may not reflect the real world applications they target. From a Testing and Evaluation (T\&E) standpoint, this domain mismatch causes difficulty assessing when improvements in State-of-the-Art (SOTA) research actually translate to improved applied outcomes. This problem can be addressed with thoughtful preparation of data and experimental methods to reflect specific use-cases and scenarios. To that end, this paper evaluates research solutions for identifying individuals at ranges and altitudes, which could support various application areas such as counterterrorism, protection of critical infrastructure facilities, military force protection, and border security. We address challenges including image quality issues and reliance on face recognition as the sole biometric modality. By fusing face and body features, we propose developing robust biometric systems for effective long-range identification from both the ground and steep pitch angles. Preliminary results show promising progress in whole-body recognition. This paper presents these early findings and discusses potential future directions for advancing long-range biometric identification systems based on mission-driven metrics.
From Data to Insights: A Covariate Analysis of the IARPA BRIAR Dataset for Multimodal Biometric Recognition Algorithms at Altitude and Range
Sep 03, 2024


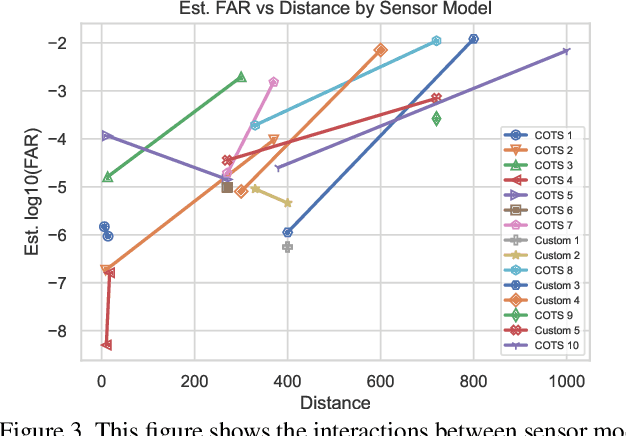
This paper examines covariate effects on fused whole body biometrics performance in the IARPA BRIAR dataset, specifically focusing on UAV platforms, elevated positions, and distances up to 1000 meters. The dataset includes outdoor videos compared with indoor images and controlled gait recordings. Normalized raw fusion scores relate directly to predicted false accept rates (FAR), offering an intuitive means for interpreting model results. A linear model is developed to predict biometric algorithm scores, analyzing their performance to identify the most influential covariates on accuracy at altitude and range. Weather factors like temperature, wind speed, solar loading, and turbulence are also investigated in this analysis. The study found that resolution and camera distance best predicted accuracy and findings can guide future research and development efforts in long-range/elevated/UAV biometrics and support the creation of more reliable and robust systems for national security and other critical domains.
Improving Robustness of Spectrogram Classifiers with Neural Stochastic Differential Equations
Sep 03, 2024Signal analysis and classification is fraught with high levels of noise and perturbation. Computer-vision-based deep learning models applied to spectrograms have proven useful in the field of signal classification and detection; however, these methods aren't designed to handle the low signal-to-noise ratios inherent within non-vision signal processing tasks. While they are powerful, they are currently not the method of choice in the inherently noisy and dynamic critical infrastructure domain, such as smart-grid sensing, anomaly detection, and non-intrusive load monitoring.
Expanding Accurate Person Recognition to New Altitudes and Ranges: The BRIAR Dataset
Nov 03, 2022



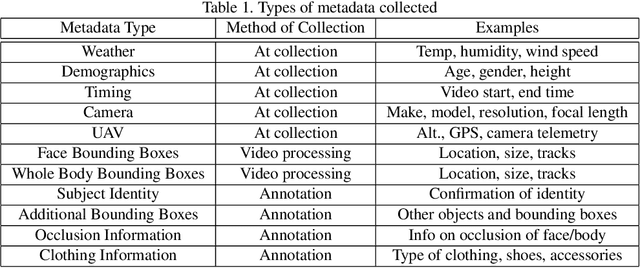
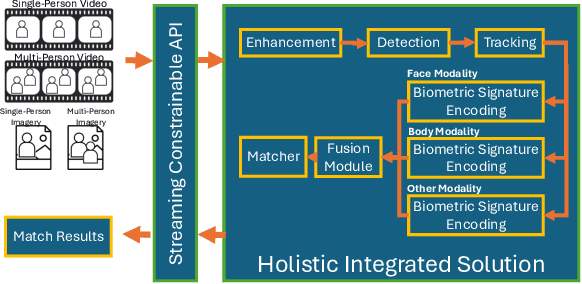
Face recognition technology has advanced significantly in recent years due largely to the availability of large and increasingly complex training datasets for use in deep learning models. These datasets, however, typically comprise images scraped from news sites or social media platforms and, therefore, have limited utility in more advanced security, forensics, and military applications. These applications require lower resolution, longer ranges, and elevated viewpoints. To meet these critical needs, we collected and curated the first and second subsets of a large multi-modal biometric dataset designed for use in the research and development (R&D) of biometric recognition technologies under extremely challenging conditions. Thus far, the dataset includes more than 350,000 still images and over 1,300 hours of video footage of approximately 1,000 subjects. To collect this data, we used Nikon DSLR cameras, a variety of commercial surveillance cameras, specialized long-rage R&D cameras, and Group 1 and Group 2 UAV platforms. The goal is to support the development of algorithms capable of accurately recognizing people at ranges up to 1,000 m and from high angles of elevation. These advances will include improvements to the state of the art in face recognition and will support new research in the area of whole-body recognition using methods based on gait and anthropometry. This paper describes methods used to collect and curate the dataset, and the dataset's characteristics at the current stage.
FaRO 2: an Open Source, Configurable Smart City Framework for Real-Time Distributed Vision and Biometric Systems
Sep 26, 2022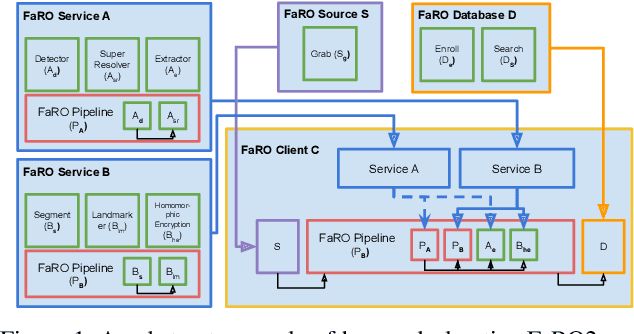
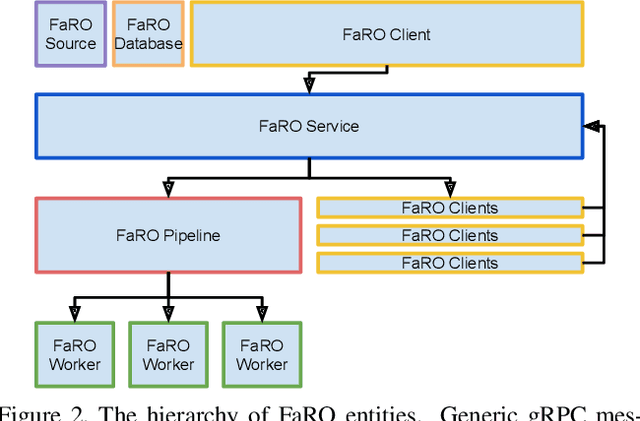
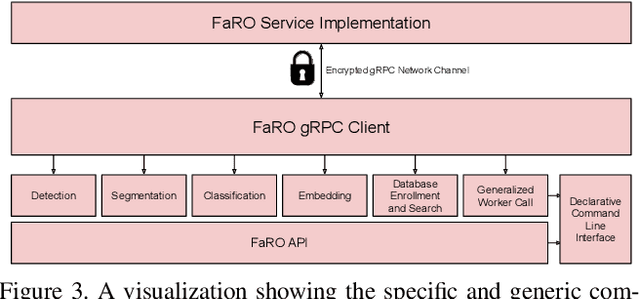
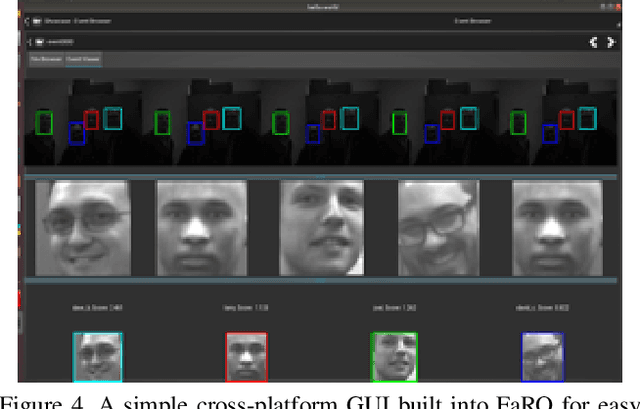
Recent global growth in the interest of smart cities has led to trillions of dollars of investment toward research and development. These connected cities have the potential to create a symbiosis of technology and society and revolutionize the cost of living, safety, ecological sustainability, and quality of life of societies on a world-wide scale. Some key components of the smart city construct are connected smart grids, self-driving cars, federated learning systems, smart utilities, large-scale public transit, and proactive surveillance systems. While exciting in prospect, these technologies and their subsequent integration cannot be attempted without addressing the potential societal impacts of such a high degree of automation and data sharing. Additionally, the feasibility of coordinating so many disparate tasks will require a fast, extensible, unifying framework. To that end, we propose FaRO2, a completely reimagined successor to FaRO1, built from the ground up. FaRO2 affords all of the same functionality as its predecessor, serving as a unified biometric API harness that allows for seamless evaluation, deployment, and simple pipeline creation for heterogeneous biometric software. FaRO2 additionally provides a fully declarative capability for defining and coordinating custom machine learning and sensor pipelines, allowing the distribution of processes across otherwise incompatible hardware and networks. FaRO2 ultimately provides a way to quickly configure, hot-swap, and expand large coordinated or federated systems online without interruptions for maintenance. Because much of the data collected in a smart city contains Personally Identifying Information (PII), FaRO2 also provides built-in tools and layers to ensure secure and encrypted streaming, storage, and access of PII data across distributed systems.
The Mertens Unrolled Network : A High Dynamic Range Fusion Neural Network for Through the Windshield Driver Recognition
Feb 27, 2020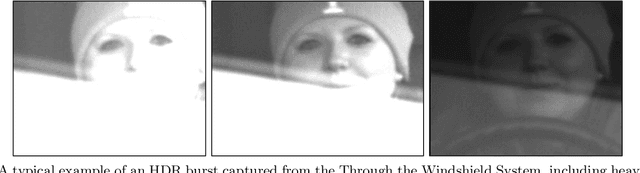



Face recognition of vehicle occupants through windshields in unconstrained environments poses a number of unique challenges ranging from glare, poor illumination, driver pose and motion blur. In this paper, we further develop the hardware and software components of a custom vehicle imaging system to better overcome these challenges. After the build out of a physical prototype system that performs High Dynamic Range (HDR) imaging, we collect a small dataset of through-windshield image captures of known drivers. We then re-formulate the classical Mertens-Kautz-Van Reeth HDR fusion algorithm as a pre-initialized neural network, which we name the Mertens Unrolled Network (MU-Net), for the purpose of fine-tuning the HDR output of through-windshield images. Reconstructed faces from this novel HDR method are then evaluated and compared against other traditional and experimental HDR methods in a pre-trained state-of-the-art (SOTA) facial recognition pipeline, verifying the efficacy of our approach.
Automatic Discovery of Political Meme Genres with Diverse Appearances
Jan 17, 2020
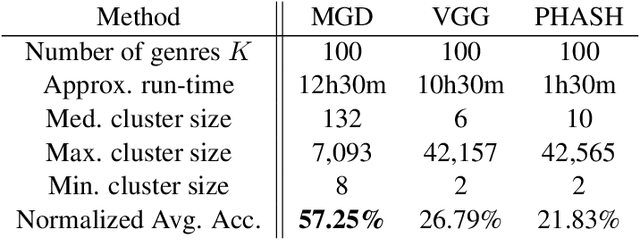

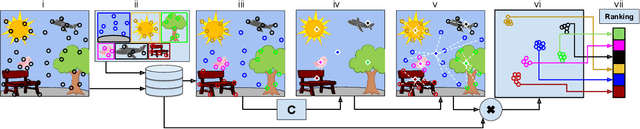
Forms of human communication are not static --- we expect some evolution in the way information is conveyed over time because of advances in technology. One example of this phenomenon is the image-based meme, which has emerged as a dominant form of political messaging in the past decade. While originally used to spread jokes on social media, memes are now having an outsized impact on public perception of world events. A significant challenge in automatic meme analysis has been the development of a strategy to match memes from within a single genre when the appearances of the images vary. Such variation is especially common in memes exhibiting mimicry. For example, when voters perform a common hand gesture to signal their support for a candidate. In this paper we introduce a scalable automated visual recognition pipeline for discovering political meme genres of diverse appearance. This pipeline can ingest meme images from a social network, apply computer vision-based techniques to extract local features and index new images into a database, and then organize the memes into related genres. To validate this approach, we perform a large case study on the 2019 Indonesian Presidential Election using a new dataset of over two million images collected from Twitter and Instagram. Results show that this approach can discover new meme genres with visually diverse images that share common stylistic elements, paving the way forward for further work in semantic analysis and content attribution.
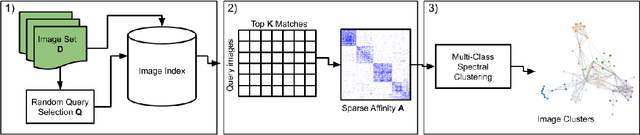
Needle in a Haystack: A Framework for Seeking Small Objects in Big Datasets
Apr 10, 2019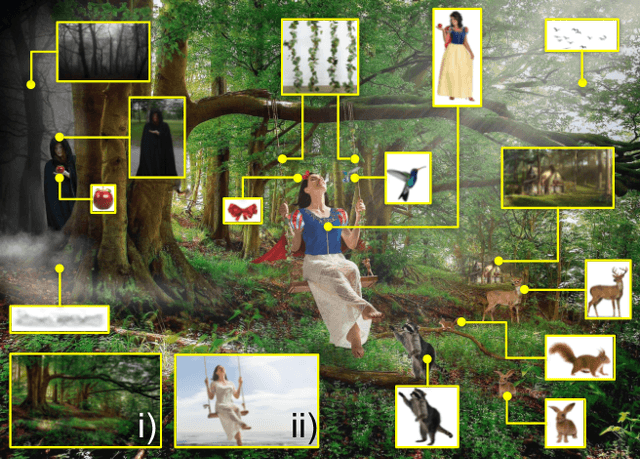
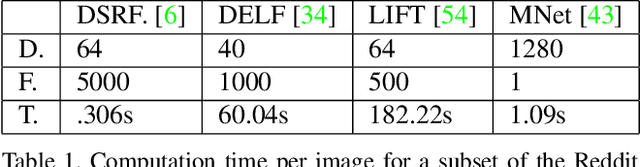
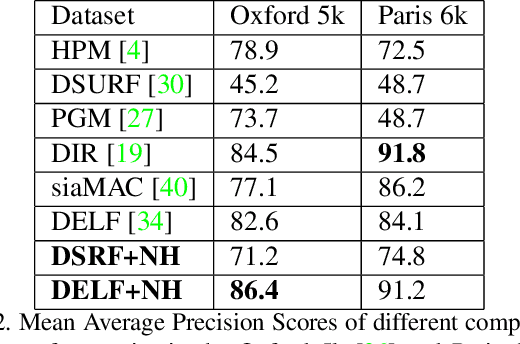
Images from social media can reflect diverse viewpoints, heated arguments, and expressions of creativity --- adding new complexity to search tasks. Researchers working on Content-Based Image Retrieval (CBIR) have traditionally tuned their search algorithms to match filtered results with user search intent. However, we are now bombarded with composite images of unknown origin, authenticity, and even meaning. With such uncertainty, users may not have an initial idea of what the results of a search query should look like. For instance, hidden people, spliced objects, and subtly altered scenes can be difficult for a user to detect initially in a meme image, but may contribute significantly to its composition. We propose a new framework for image retrieval that models object-level regions using image keypoints retrieved from an image index, which are then used to accurately weight small contributing objects within the results, without the need for costly object detection steps. We call this method Needle-Haystack (NH) scoring, and it is optimized for fast matrix operations on CPUs. We show that this method not only performs comparably to state-of-the-art methods in classic CBIR problems, but also outperforms them in fine-grained object- and instance-level retrieval on the Oxford 5K, Paris 6K, Google-Landmarks, and NIST MFC2018 datasets, as well as meme-style imagery from Reddit.