 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCognition Envelopes for Bounded AI Reasoning in Autonomous UAS Operations
Oct 30, 2025Cyber-physical systems increasingly rely on Foundational Models such as Large Language Models (LLMs) and Vision-Language Models (VLMs) to increase autonomy through enhanced perception, inference, and planning. However, these models also introduce new types of errors, such as hallucinations, overgeneralizations, and context misalignments, resulting in incorrect and flawed decisions. To address this, we introduce the concept of Cognition Envelopes, designed to establish reasoning boundaries that constrain AI-generated decisions while complementing the use of meta-cognition and traditional safety envelopes. As with safety envelopes, Cognition Envelopes require practical guidelines and systematic processes for their definition, validation, and assurance.
A Comprehensive Evaluation Framework for the Study of the Effects of Facial Filters on Face Recognition Accuracy
Jul 23, 2025Facial filters are now commonplace for social media users around the world. Previous work has demonstrated that facial filters can negatively impact automated face recognition performance. However, these studies focus on small numbers of hand-picked filters in particular styles. In order to more effectively incorporate the wide ranges of filters present on various social media applications, we introduce a framework that allows for larger-scale study of the impact of facial filters on automated recognition. This framework includes a controlled dataset of face images, a principled filter selection process that selects a representative range of filters for experimentation, and a set of experiments to evaluate the filters' impact on recognition. We demonstrate our framework with a case study of filters from the American applications Instagram and Snapchat and the Chinese applications Meitu and Pitu to uncover cross-cultural differences. Finally, we show how the filtering effect in a face embedding space can easily be detected and restored to improve face recognition performance.
Towards Fair and Robust Face Parsing for Generative AI: A Multi-Objective Approach
Feb 06, 2025



Face parsing is a fundamental task in computer vision, enabling applications such as identity verification, facial editing, and controllable image synthesis. However, existing face parsing models often lack fairness and robustness, leading to biased segmentation across demographic groups and errors under occlusions, noise, and domain shifts. These limitations affect downstream face synthesis, where segmentation biases can degrade generative model outputs. We propose a multi-objective learning framework that optimizes accuracy, fairness, and robustness in face parsing. Our approach introduces a homotopy-based loss function that dynamically adjusts the importance of these objectives during training. To evaluate its impact, we compare multi-objective and single-objective U-Net models in a GAN-based face synthesis pipeline (Pix2PixHD). Our results show that fairness-aware and robust segmentation improves photorealism and consistency in face generation. Additionally, we conduct preliminary experiments using ControlNet, a structured conditioning model for diffusion-based synthesis, to explore how segmentation quality influences guided image generation. Our findings demonstrate that multi-objective face parsing improves demographic consistency and robustness, leading to higher-quality GAN-based synthesis.
Identifying Information from Observations with Uncertainty and Novelty
Jan 16, 2025

A machine learning tasks from observations must encounter and process uncertainty and novelty, especially when it is expected to maintain performance when observing new information and to choose the best fitting hypothesis to the currently observed information. In this context, some key questions arise: what is information, how much information did the observations provide, how much information is required to identify the data-generating process, how many observations remain to get that information, and how does a predictor determine that it has observed novel information? This paper strengthens existing answers to these questions by formalizing the notion of "identifiable information" that arises from the language used to express the relationship between distinct states. Model identifiability and sample complexity are defined via computation of an indicator function over a set of hypotheses. Their properties and asymptotic statistics are described for data-generating processes ranging from deterministic processes to ergodic stationary stochastic processes. This connects the notion of identifying information in finite steps with asymptotic statistics and PAC-learning. The indicator function's computation naturally formalizes novel information and its identification from observations with respect to a hypothesis set. We also proved that computable PAC-Bayes learners' sample complexity distribution is determined by its moments in terms of the the prior probability distribution over a fixed finite hypothesis set.
This Probably Looks Exactly Like That: An Invertible Prototypical Network
Jul 16, 2024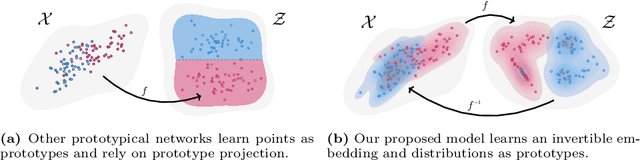
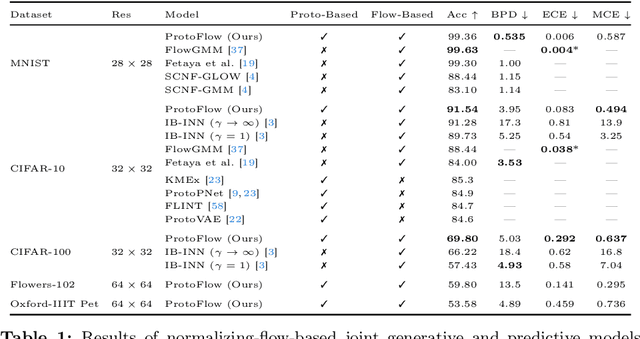
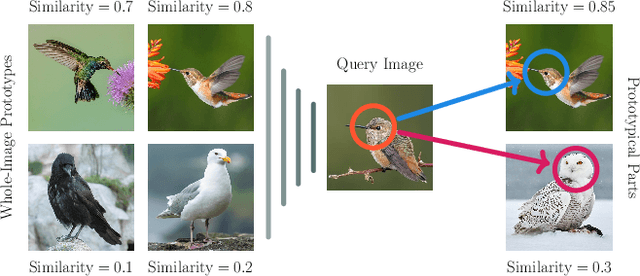
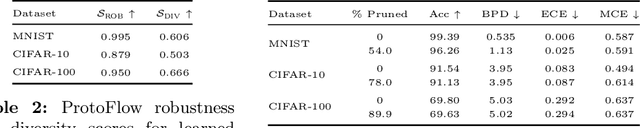
We combine concept-based neural networks with generative, flow-based classifiers into a novel, intrinsically explainable, exactly invertible approach to supervised learning. Prototypical neural networks, a type of concept-based neural network, represent an exciting way forward in realizing human-comprehensible machine learning without concept annotations, but a human-machine semantic gap continues to haunt current approaches. We find that reliance on indirect interpretation functions for prototypical explanations imposes a severe limit on prototypes' informative power. From this, we posit that invertibly learning prototypes as distributions over the latent space provides more robust, expressive, and interpretable modeling. We propose one such model, called ProtoFlow, by composing a normalizing flow with Gaussian mixture models. ProtoFlow (1) sets a new state-of-the-art in joint generative and predictive modeling and (2) achieves predictive performance comparable to existing prototypical neural networks while enabling richer interpretation.
How Well Do Feature-Additive Explainers Explain Feature-Additive Predictors?
Oct 27, 2023



Surging interest in deep learning from high-stakes domains has precipitated concern over the inscrutable nature of black box neural networks. Explainable AI (XAI) research has led to an abundance of explanation algorithms for these black boxes. Such post hoc explainers produce human-comprehensible explanations, however, their fidelity with respect to the model is not well understood - explanation evaluation remains one of the most challenging issues in XAI. In this paper, we ask a targeted but important question: can popular feature-additive explainers (e.g., LIME, SHAP, SHAPR, MAPLE, and PDP) explain feature-additive predictors? Herein, we evaluate such explainers on ground truth that is analytically derived from the additive structure of a model. We demonstrate the efficacy of our approach in understanding these explainers applied to symbolic expressions, neural networks, and generalized additive models on thousands of synthetic and several real-world tasks. Our results suggest that all explainers eventually fail to correctly attribute the importance of features, especially when a decision-making process involves feature interactions.
HomOpt: A Homotopy-Based Hyperparameter Optimization Method
Aug 07, 2023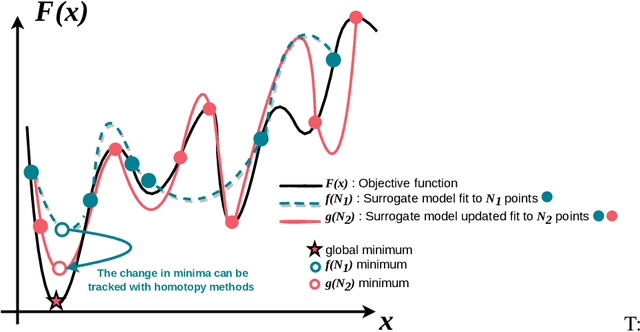



Machine learning has achieved remarkable success over the past couple of decades, often attributed to a combination of algorithmic innovations and the availability of high-quality data available at scale. However, a third critical component is the fine-tuning of hyperparameters, which plays a pivotal role in achieving optimal model performance. Despite its significance, hyperparameter optimization (HPO) remains a challenging task for several reasons. Many HPO techniques rely on naive search methods or assume that the loss function is smooth and continuous, which may not always be the case. Traditional methods, like grid search and Bayesian optimization, often struggle to quickly adapt and efficiently search the loss landscape. Grid search is computationally expensive, while Bayesian optimization can be slow to prime. Since the search space for HPO is frequently high-dimensional and non-convex, it is often challenging to efficiently find a global minimum. Moreover, optimal hyperparameters can be sensitive to the specific dataset or task, further complicating the search process. To address these issues, we propose a new hyperparameter optimization method, HomOpt, using a data-driven approach based on a generalized additive model (GAM) surrogate combined with homotopy optimization. This strategy augments established optimization methodologies to boost the performance and effectiveness of any given method with faster convergence to the optimum on continuous, discrete, and categorical domain spaces. We compare the effectiveness of HomOpt applied to multiple optimization techniques (e.g., Random Search, TPE, Bayes, and SMAC) showing improved objective performance on many standardized machine learning benchmarks and challenging open-set recognition tasks.
On the Effectiveness of Image Manipulation Detection in the Age of Social Media
Apr 19, 2023Image manipulation detection algorithms designed to identify local anomalies often rely on the manipulated regions being ``sufficiently'' different from the rest of the non-tampered regions in the image. However, such anomalies might not be easily identifiable in high-quality manipulations, and their use is often based on the assumption that certain image phenomena are associated with the use of specific editing tools. This makes the task of manipulation detection hard in and of itself, with state-of-the-art detectors only being able to detect a limited number of manipulation types. More importantly, in cases where the anomaly assumption does not hold, the detection of false positives in otherwise non-manipulated images becomes a serious problem. To understand the current state of manipulation detection, we present an in-depth analysis of deep learning-based and learning-free methods, assessing their performance on different benchmark datasets containing tampered and non-tampered samples. We provide a comprehensive study of their suitability for detecting different manipulations as well as their robustness when presented with non-tampered data. Furthermore, we propose a novel deep learning-based pre-processing technique that accentuates the anomalies present in manipulated regions to make them more identifiable by a variety of manipulation detection methods. To this end, we introduce an anomaly enhancement loss that, when used with a residual architecture, improves the performance of different detection algorithms with a minimal introduction of false positives on the non-manipulated data. Lastly, we introduce an open-source manipulation detection toolkit comprising a number of standard detection algorithms.
Human Activity Recognition in an Open World
Dec 23, 2022
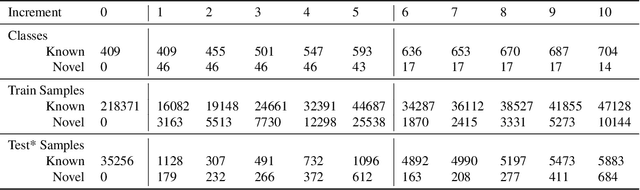

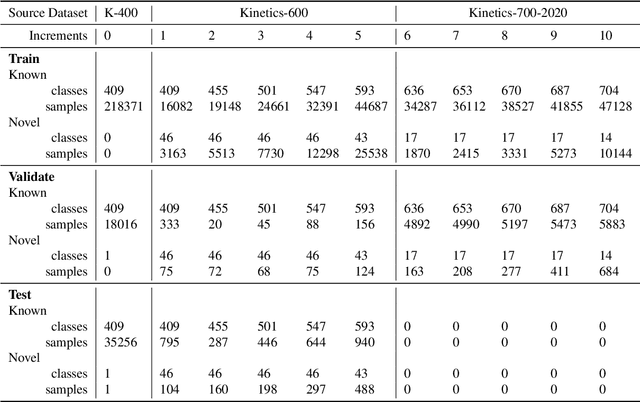
Managing novelty in perception-based human activity recognition (HAR) is critical in realistic settings to improve task performance over time and ensure solution generalization outside of prior seen samples. Novelty manifests in HAR as unseen samples, activities, objects, environments, and sensor changes, among other ways. Novelty may be task-relevant, such as a new class or new features, or task-irrelevant resulting in nuisance novelty, such as never before seen noise, blur, or distorted video recordings. To perform HAR optimally, algorithmic solutions must be tolerant to nuisance novelty, and learn over time in the face of novelty. This paper 1) formalizes the definition of novelty in HAR building upon the prior definition of novelty in classification tasks, 2) proposes an incremental open world learning (OWL) protocol and applies it to the Kinetics datasets to generate a new benchmark KOWL-718, 3) analyzes the performance of current state-of-the-art HAR models when novelty is introduced over time, 4) provides a containerized and packaged pipeline for reproducing the OWL protocol and for modifying for any future updates to Kinetics. The experimental analysis includes an ablation study of how the different models perform under various conditions as annotated by Kinetics-AVA. The protocol as an algorithm for reproducing experiments using the KOWL-718 benchmark will be publicly released with code and containers at https://github.com/prijatelj/human-activity-recognition-in-an-open-world. The code may be used to analyze different annotations and subsets of the Kinetics datasets in an incremental open world fashion, as well as be extended as further updates to Kinetics are released.
Using Human Perception to Regularize Transfer Learning
Nov 15, 2022

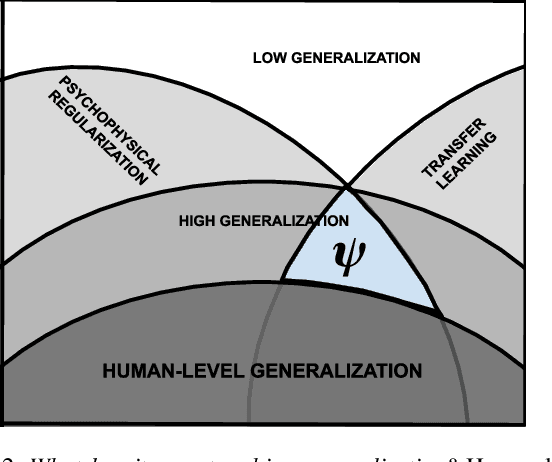

Recent trends in the machine learning community show that models with fidelity toward human perceptual measurements perform strongly on vision tasks. Likewise, human behavioral measurements have been used to regularize model performance. But can we transfer latent knowledge gained from this across different learning objectives? In this work, we introduce PERCEP-TL (Perceptual Transfer Learning), a methodology for improving transfer learning with the regularization power of psychophysical labels in models. We demonstrate which models are affected the most by perceptual transfer learning and find that models with high behavioral fidelity -- including vision transformers -- improve the most from this regularization by as much as 1.9\% Top@1 accuracy points. These findings suggest that biologically inspired learning agents can benefit from human behavioral measurements as regularizers and psychophysical learned representations can be transferred to independent evaluation tasks.