 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRA Land: 310 Fine-tuned LLMs that Rival GPT-4, A Technical Report
Apr 29, 2024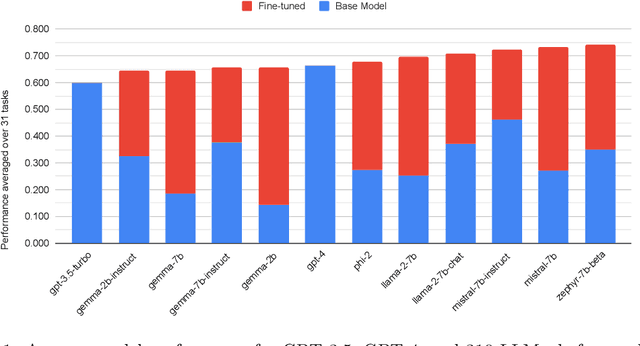


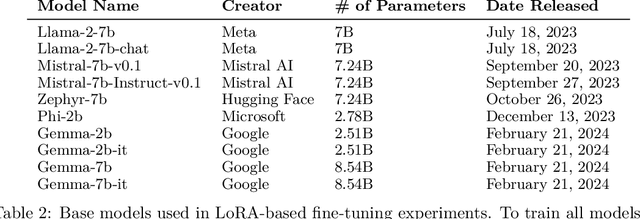
Low Rank Adaptation (LoRA) has emerged as one of the most widely adopted methods for Parameter Efficient Fine-Tuning (PEFT) of Large Language Models (LLMs). LoRA reduces the number of trainable parameters and memory usage while achieving comparable performance to full fine-tuning. We aim to assess the viability of training and serving LLMs fine-tuned with LoRA in real-world applications. First, we measure the quality of LLMs fine-tuned with quantized low rank adapters across 10 base models and 31 tasks for a total of 310 models. We find that 4-bit LoRA fine-tuned models outperform base models by 34 points and GPT-4 by 10 points on average. Second, we investigate the most effective base models for fine-tuning and assess the correlative and predictive capacities of task complexity heuristics in forecasting the outcomes of fine-tuning. Finally, we evaluate the latency and concurrency capabilities of LoRAX, an open-source Multi-LoRA inference server that facilitates the deployment of multiple LoRA fine-tuned models on a single GPU using shared base model weights and dynamic adapter loading. LoRAX powers LoRA Land, a web application that hosts 25 LoRA fine-tuned Mistral-7B LLMs on a single NVIDIA A100 GPU with 80GB memory. LoRA Land highlights the quality and cost-effectiveness of employing multiple specialized LLMs over a single, general-purpose LLM.
HomOpt: A Homotopy-Based Hyperparameter Optimization Method
Aug 07, 2023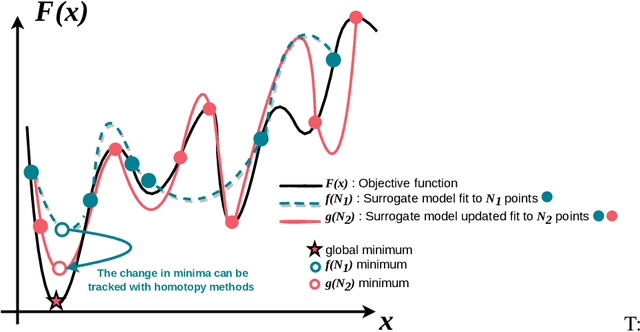



Machine learning has achieved remarkable success over the past couple of decades, often attributed to a combination of algorithmic innovations and the availability of high-quality data available at scale. However, a third critical component is the fine-tuning of hyperparameters, which plays a pivotal role in achieving optimal model performance. Despite its significance, hyperparameter optimization (HPO) remains a challenging task for several reasons. Many HPO techniques rely on naive search methods or assume that the loss function is smooth and continuous, which may not always be the case. Traditional methods, like grid search and Bayesian optimization, often struggle to quickly adapt and efficiently search the loss landscape. Grid search is computationally expensive, while Bayesian optimization can be slow to prime. Since the search space for HPO is frequently high-dimensional and non-convex, it is often challenging to efficiently find a global minimum. Moreover, optimal hyperparameters can be sensitive to the specific dataset or task, further complicating the search process. To address these issues, we propose a new hyperparameter optimization method, HomOpt, using a data-driven approach based on a generalized additive model (GAM) surrogate combined with homotopy optimization. This strategy augments established optimization methodologies to boost the performance and effectiveness of any given method with faster convergence to the optimum on continuous, discrete, and categorical domain spaces. We compare the effectiveness of HomOpt applied to multiple optimization techniques (e.g., Random Search, TPE, Bayes, and SMAC) showing improved objective performance on many standardized machine learning benchmarks and challenging open-set recognition tasks.
Auto-Sizing the Transformer Network: Improving Speed, Efficiency, and Performance for Low-Resource Machine Translation
Oct 01, 2019
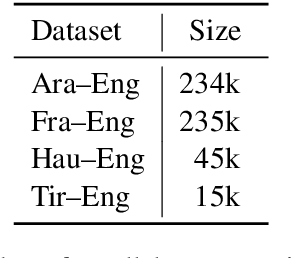
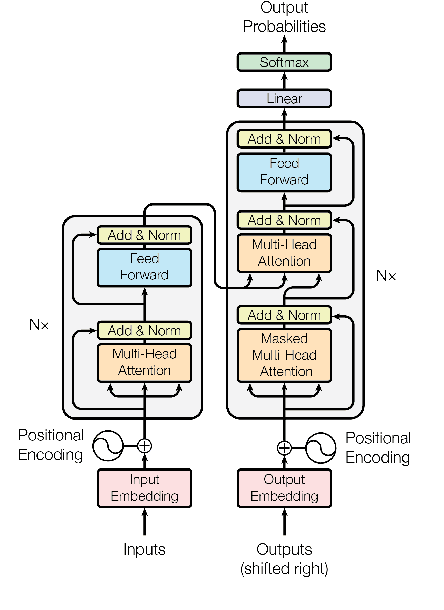
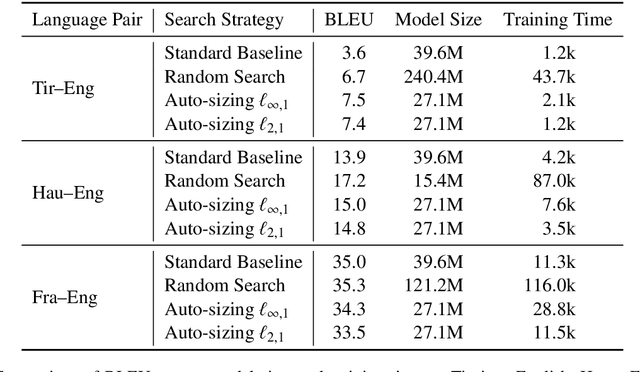
Neural sequence-to-sequence models, particularly the Transformer, are the state of the art in machine translation. Yet these neural networks are very sensitive to architecture and hyperparameter settings. Optimizing these settings by grid or random search is computationally expensive because it requires many training runs. In this paper, we incorporate architecture search into a single training run through auto-sizing, which uses regularization to delete neurons in a network over the course of training. On very low-resource language pairs, we show that auto-sizing can improve BLEU scores by up to 3.9 points while removing one-third of the parameters from the model.
Learning-Free Iris Segmentation Revisited: A First Step Toward Fast Volumetric Operation Over Video Samples
Jan 06, 2019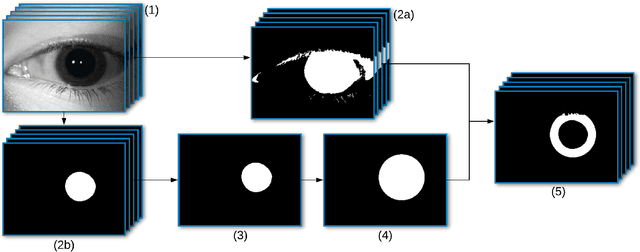
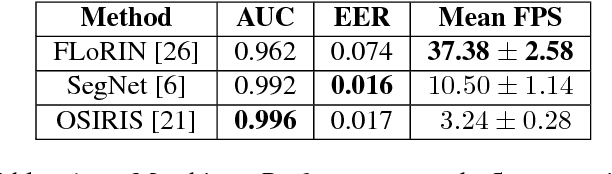
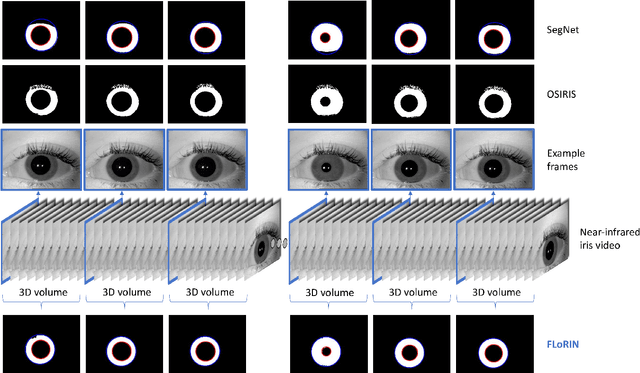
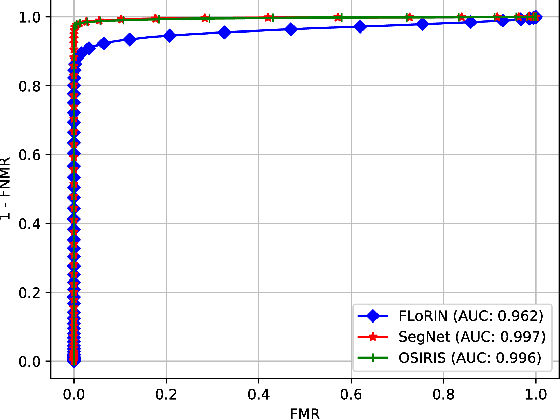
Subject matching performance in iris biometrics is contingent upon fast, high-quality iris segmentation. In many cases, iris biometrics acquisition equipment takes a number of images in sequence and combines the segmentation and matching results for each image to strengthen the result. To date, segmentation has occurred in 2D, operating on each image individually. But such methodologies, while powerful, do not take advantage of potential gains in performance afforded by treating sequential images as volumetric data. As a first step in this direction, we apply the Flexible Learning-Free Reconstructoin of Neural Volumes (FLoRIN) framework, an open source segmentation and reconstruction framework originally designed for neural microscopy volumes, to volumetric segmentation of iris videos. Further, we introduce a novel dataset of near-infrared iris videos, in which each subject's pupil rapidly changes size due to visible-light stimuli, as a test bed for FLoRIN. We compare the matching performance for iris masks generated by FLoRIN, deep-learning-based (SegNet), and Daugman's (OSIRIS) iris segmentation approaches. We show that by incorporating volumetric information, FLoRIN achieves a factor of 3.6 to an order of magnitude increase in throughput with only a minor drop in subject matching performance. We also demonstrate that FLoRIN-based iris segmentation maintains this speedup on low-resource hardware, making it suitable for embedded biometrics systems.
A Neurobiological Cross-domain Evaluation Metric for Predictive Coding Networks
Jul 09, 2018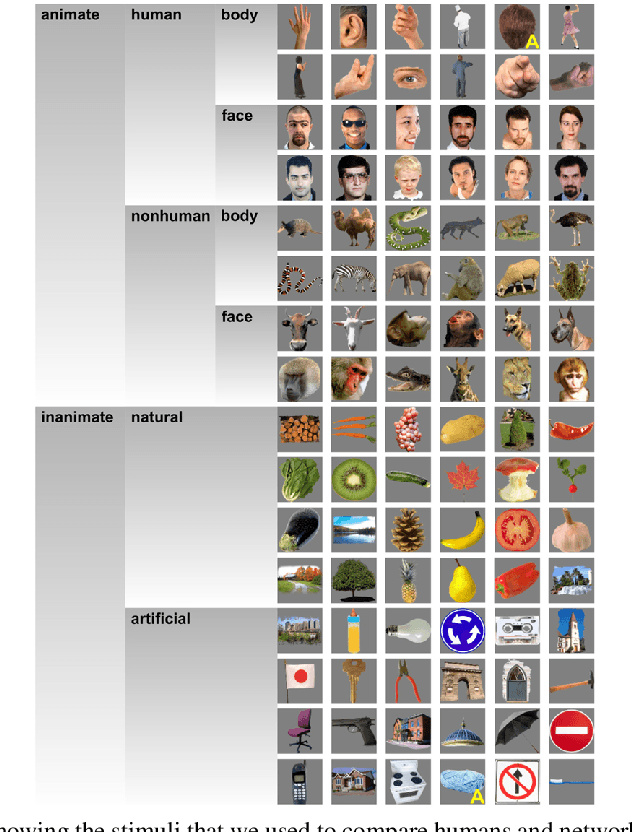


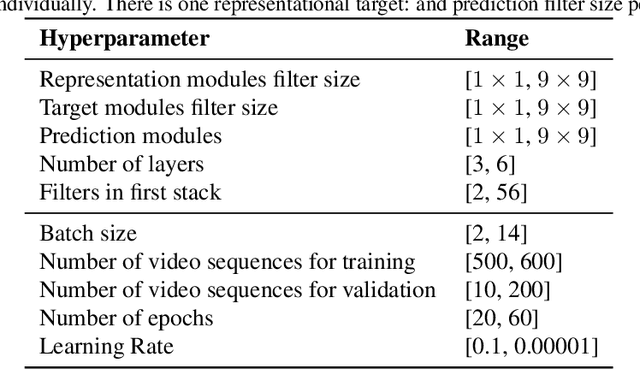
Achieving a good measure of model generalization remains a challenge within machine learning. One of the highest-performing learning models is the biological brain, which has unparalleled generalization capabilities. In this work, we propose and evaluate a human-model similarity metric for determining model correspondence to the human brain, as inspired by representational similarity analysis. We evaluate this metric on unsupervised predictive coding networks. These models are designed to mimic the phenomenon of residual error propagation in the visual cortex, implying their potential for biological fidelity. The human-model similarity metric is calculated by measuring the similarity between human brain fMRI activations and predictive coding network activations over a shared set of stimuli. In order to study our metric in relation to standard performance evaluations on cross-domain tasks, we train a multitude of predictive coding models across various conditions. Each unsupervised model is trained on next frame prediction in video and evaluated using three metrics: 1) mean squared error of next frame prediction, 2) object matching accuracy, and 3) our human-model similarity metric. Through this evaluation, we show that models with higher human-model similarity are more likely to generalize to cross-domain tasks. We also show that our metric facilitates a substantial decrease in model search time because the similarity metric stabilizes quickly --- in as few as 10 epochs. We propose that this metric could be deployed in model search to quickly identify and eliminate weaker models.