 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSELAUR: Self Evolving LLM Agent via Uncertainty-aware Rewards
Feb 25, 2026Large language models (LLMs) are increasingly deployed as multi-step decision-making agents, where effective reward design is essential for guiding learning. Although recent work explores various forms of reward shaping and step-level credit assignment, a key signal remains largely overlooked: the intrinsic uncertainty of LLMs. Uncertainty reflects model confidence, reveals where exploration is needed, and offers valuable learning cues even in failed trajectories. We introduce SELAUR: Self Evolving LLM Agent via Uncertainty-aware Rewards, a reinforcement learning framework that incorporates uncertainty directly into the reward design. SELAUR integrates entropy-, least-confidence-, and margin-based metrics into a combined token-level uncertainty estimate, providing dense confidence-aligned supervision, and employs a failure-aware reward reshaping mechanism that injects these uncertainty signals into step- and trajectory-level rewards to improve exploration efficiency and learning stability. Experiments on two benchmarks, ALFWorld and WebShop, show that our method consistently improves success rates over strong baselines. Ablation studies further demonstrate how uncertainty signals enhance exploration and robustness.
CommonLID: Re-evaluating State-of-the-Art Language Identification Performance on Web Data
Jan 25, 2026Language identification (LID) is a fundamental step in curating multilingual corpora. However, LID models still perform poorly for many languages, especially on the noisy and heterogeneous web data often used to train multilingual language models. In this paper, we introduce CommonLID, a community-driven, human-annotated LID benchmark for the web domain, covering 109 languages. Many of the included languages have been previously under-served, making CommonLID a key resource for developing more representative high-quality text corpora. We show CommonLID's value by using it, alongside five other common evaluation sets, to test eight popular LID models. We analyse our results to situate our contribution and to provide an overview of the state of the art. In particular, we highlight that existing evaluations overestimate LID accuracy for many languages in the web domain. We make CommonLID and the code used to create it available under an open, permissive license.
FACTUM: Mechanistic Detection of Citation Hallucination in Long-Form RAG
Jan 09, 2026Retrieval-Augmented Generation (RAG) models are critically undermined by citation hallucinations, a deceptive failure where a model confidently cites a source that fails to support its claim. Existing work often attributes hallucination to a simple over-reliance on the model's parametric knowledge. We challenge this view and introduce FACTUM (Framework for Attesting Citation Trustworthiness via Underlying Mechanisms), a framework of four mechanistic scores measuring the distinct contributions of a model's attention and FFN pathways, and the alignment between them. Our analysis reveals two consistent signatures of correct citation: a significantly stronger contribution from the model's parametric knowledge and greater use of the attention sink for information synthesis. Crucially, we find the signature of a correct citation is not static but evolves with model scale. For example, the signature of a correct citation for the Llama-3.2-3B model is marked by higher pathway alignment, whereas for the Llama-3.1-8B model, it is characterized by lower alignment, where pathways contribute more distinct, orthogonal information. By capturing this complex, evolving signature, FACTUM outperforms state-of-the-art baselines by up to 37.5% in AUC. Our findings reframe citation hallucination as a complex, scale-dependent interplay between internal mechanisms, paving the way for more nuanced and reliable RAG systems.
HLTCOE Evaluation Team at TREC 2025: VQA Track
Dec 08, 2025The HLTCOE Evaluation team participated in TREC VQA's Answer Generation (AG) task, for which we developed a listwise learning framework that aims to improve semantic precision and ranking consistency in answer generation. Given a video-question pair, a base multimodal model first generates multiple candidate answers, which are then reranked using a model trained with a novel Masked Pointer Cross-Entropy Loss with Rank Weights. This objective integrates pointer-based candidate selection, rank-dependent weighting, and masked cross-entropy under vocabulary restriction, enabling stable and interpretable listwise optimization. By bridging generative modeling with discriminative ranking, our method produces coherent, fine-grained answer lists. Experiments reveal consistent gains in accuracy and ranking stability, especially for questions requiring temporal reasoning and semantic disambiguation.
MMMORRF: Multimodal Multilingual Modularized Reciprocal Rank Fusion
Mar 26, 2025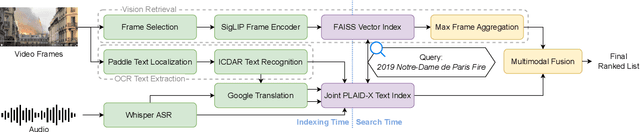


Videos inherently contain multiple modalities, including visual events, text overlays, sounds, and speech, all of which are important for retrieval. However, state-of-the-art multimodal language models like VAST and LanguageBind are built on vision-language models (VLMs), and thus overly prioritize visual signals. Retrieval benchmarks further reinforce this bias by focusing on visual queries and neglecting other modalities. We create a search system MMMORRF that extracts text and features from both visual and audio modalities and integrates them with a novel modality-aware weighted reciprocal rank fusion. MMMORRF is both effective and efficient, demonstrating practicality in searching videos based on users' information needs instead of visual descriptive queries. We evaluate MMMORRF on MultiVENT 2.0 and TVR, two multimodal benchmarks designed for more targeted information needs, and find that it improves nDCG@20 by 81% over leading multimodal encoders and 37% over single-modality retrieval, demonstrating the value of integrating diverse modalities.
Video-ColBERT: Contextualized Late Interaction for Text-to-Video Retrieval
Mar 24, 2025In this work, we tackle the problem of text-to-video retrieval (T2VR). Inspired by the success of late interaction techniques in text-document, text-image, and text-video retrieval, our approach, Video-ColBERT, introduces a simple and efficient mechanism for fine-grained similarity assessment between queries and videos. Video-ColBERT is built upon 3 main components: a fine-grained spatial and temporal token-wise interaction, query and visual expansions, and a dual sigmoid loss during training. We find that this interaction and training paradigm leads to strong individual, yet compatible, representations for encoding video content. These representations lead to increases in performance on common text-to-video retrieval benchmarks compared to other bi-encoder methods.
DialUp! Modeling the Language Continuum by Adapting Models to Dialects and Dialects to Models
Jan 27, 2025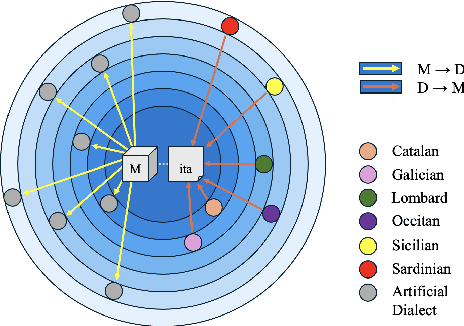



Most of the world's languages and dialects are low-resource, and lack support in mainstream machine translation (MT) models. However, many of them have a closely-related high-resource language (HRL) neighbor, and differ in linguistically regular ways from it. This underscores the importance of model robustness to dialectical variation and cross-lingual generalization to the HRL dialect continuum. We present DialUp, consisting of a training-time technique for adapting a pretrained model to dialectical data (M->D), and an inference-time intervention adapting dialectical data to the model expertise (D->M). M->D induces model robustness to potentially unseen and unknown dialects by exposure to synthetic data exemplifying linguistic mechanisms of dialectical variation, whereas D->M treats dialectical divergence for known target dialects. These methods show considerable performance gains for several dialects from four language families, and modest gains for two other language families. We also conduct feature and error analyses, which show that language varieties with low baseline MT performance are more likely to benefit from these approaches.
Merging Feed-Forward Sublayers for Compressed Transformers
Jan 10, 2025With the rise and ubiquity of larger deep learning models, the need for high-quality compression techniques is growing in order to deploy these models widely. The sheer parameter count of these models makes it difficult to fit them into the memory constraints of different hardware. In this work, we present a novel approach to model compression by merging similar parameter groups within a model, rather than pruning away less important parameters. Specifically, we select, align, and merge separate feed-forward sublayers in Transformer models, and test our method on language modeling, image classification, and machine translation. With our method, we demonstrate performance comparable to the original models while combining more than a third of model feed-forward sublayers, and demonstrate improved performance over a strong layer-pruning baseline. For instance, we can remove over 21% of total parameters from a Vision Transformer, while maintaining 99% of its original performance. Additionally, we observe that some groups of feed-forward sublayers exhibit high activation similarity, which may help explain their surprising mergeability.
Findings of the IWSLT 2024 Evaluation Campaign
Nov 07, 2024This paper reports on the shared tasks organized by the 21st IWSLT Conference. The shared tasks address 7 scientific challenges in spoken language translation: simultaneous and offline translation, automatic subtitling and dubbing, speech-to-speech translation, dialect and low-resource speech translation, and Indic languages. The shared tasks attracted 18 teams whose submissions are documented in 26 system papers. The growing interest towards spoken language translation is also witnessed by the constantly increasing number of shared task organizers and contributors to the overview paper, almost evenly distributed across industry and academia.
MultiVENT 2.0: A Massive Multilingual Benchmark for Event-Centric Video Retrieval
Oct 15, 2024Efficiently retrieving and synthesizing information from large-scale multimodal collections has become a critical challenge. However, existing video retrieval datasets suffer from scope limitations, primarily focusing on matching descriptive but vague queries with small collections of professionally edited, English-centric videos. To address this gap, we introduce $\textbf{MultiVENT 2.0}$, a large-scale, multilingual event-centric video retrieval benchmark featuring a collection of more than 218,000 news videos and 3,906 queries targeting specific world events. These queries specifically target information found in the visual content, audio, embedded text, and text metadata of the videos, requiring systems leverage all these sources to succeed at the task. Preliminary results show that state-of-the-art vision-language models struggle significantly with this task, and while alternative approaches show promise, they are still insufficient to adequately address this problem. These findings underscore the need for more robust multimodal retrieval systems, as effective video retrieval is a crucial step towards multimodal content understanding and generation tasks.