 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMerging Feed-Forward Sublayers for Compressed Transformers
Jan 10, 2025With the rise and ubiquity of larger deep learning models, the need for high-quality compression techniques is growing in order to deploy these models widely. The sheer parameter count of these models makes it difficult to fit them into the memory constraints of different hardware. In this work, we present a novel approach to model compression by merging similar parameter groups within a model, rather than pruning away less important parameters. Specifically, we select, align, and merge separate feed-forward sublayers in Transformer models, and test our method on language modeling, image classification, and machine translation. With our method, we demonstrate performance comparable to the original models while combining more than a third of model feed-forward sublayers, and demonstrate improved performance over a strong layer-pruning baseline. For instance, we can remove over 21% of total parameters from a Vision Transformer, while maintaining 99% of its original performance. Additionally, we observe that some groups of feed-forward sublayers exhibit high activation similarity, which may help explain their surprising mergeability.
Merging Text Transformer Models from Different Initializations
Mar 07, 2024



Recent work on one-shot permutation-based model merging has shown impressive low- or zero-barrier mode connectivity between models from completely different initializations. However, this line of work has not yet extended to the Transformer architecture, despite its dominant popularity in the language domain. Therefore, in this work, we investigate the extent to which separate Transformer minima learn similar features, and propose a model merging technique to investigate the relationship between these minima in the loss landscape. The specifics of the architecture, like its residual connections, multi-headed attention, and discrete, sequential input, require specific interventions in order to compute model permutations that remain within the same functional equivalence class. In merging these models with our method, we consistently find lower loss barriers between minima compared to model averaging for several models trained on a masked-language modeling task or fine-tuned on a language understanding benchmark. Our results show that the minima of these models are less sharp and isolated than previously understood, and provide a basis for future work on merging separately trained Transformer models.
Pixel Representations for Multilingual Translation and Data-efficient Cross-lingual Transfer
May 23, 2023We introduce and demonstrate how to effectively train multilingual machine translation models with pixel representations. We experiment with two different data settings with a variety of language and script coverage, and show performance competitive with subword embeddings. We analyze various properties of pixel representations to better understand where they provide potential benefits and the impact of different scripts and data representations. We observe that these properties not only enable seamless cross-lingual transfer to unseen scripts, but make pixel representations more data-efficient than alternatives such as vocabulary expansion. We hope this work contributes to more extensible multilingual models for all languages and scripts.
Exploring Representational Disparities Between Multilingual and Bilingual Translation Models
May 23, 2023Multilingual machine translation has proven immensely useful for low-resource and zero-shot language pairs. However, language pairs in multilingual models sometimes see worse performance than in bilingual models, especially when translating in a one-to-many setting. To understand why, we examine the geometric differences in the representations from bilingual models versus those from one-to-many multilingual models. Specifically, we evaluate the isotropy of the representations, to measure how well they utilize the dimensions in their underlying vector space. Using the same evaluation data in both models, we find that multilingual model decoder representations tend to be less isotropic than bilingual model decoder representations. Additionally, we show that much of the anisotropy in multilingual decoder representations can be attributed to modeling language-specific information, therefore limiting remaining representational capacity.
IsoVec: Controlling the Relative Isomorphism of Word Embedding Spaces
Oct 11, 2022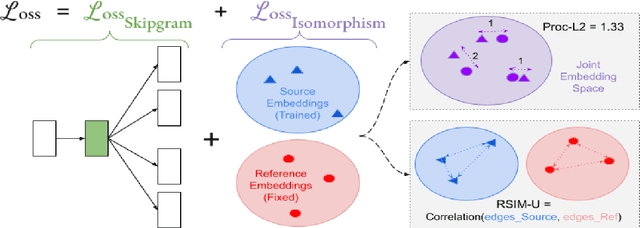
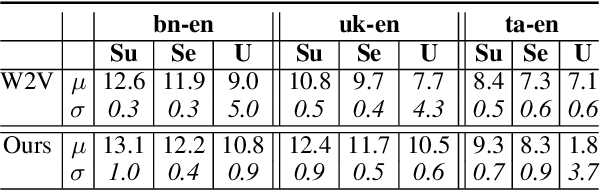
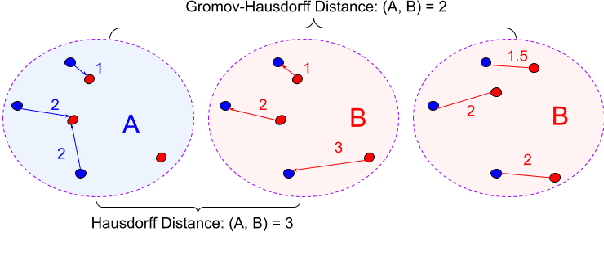

The ability to extract high-quality translation dictionaries from monolingual word embedding spaces depends critically on the geometric similarity of the spaces -- their degree of "isomorphism." We address the root-cause of faulty cross-lingual mapping: that word embedding training resulted in the underlying spaces being non-isomorphic. We incorporate global measures of isomorphism directly into the skipgram loss function, successfully increasing the relative isomorphism of trained word embedding spaces and improving their ability to be mapped to a shared cross-lingual space. The result is improved bilingual lexicon induction in general data conditions, under domain mismatch, and with training algorithm dissimilarities. We release IsoVec at https://github.com/kellymarchisio/isovec.
Neural Natural Language Processing for Unstructured Data in Electronic Health Records: a Review
Jul 07, 2021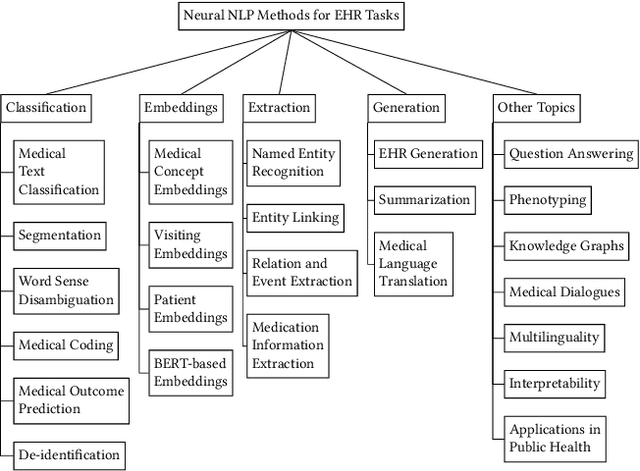
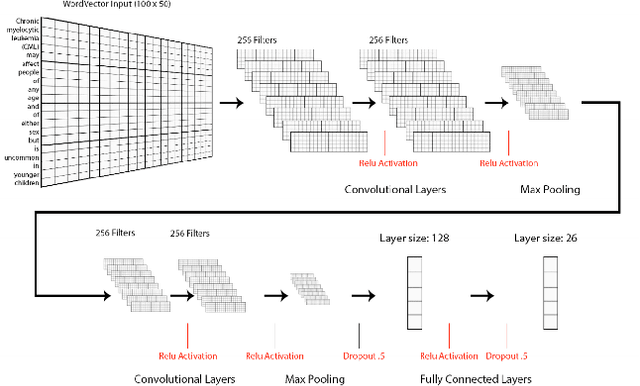
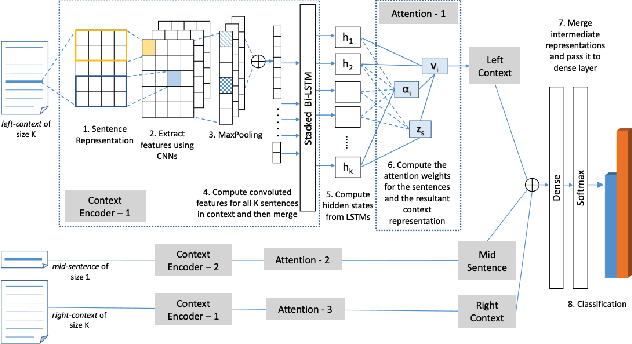

Electronic health records (EHRs), digital collections of patient healthcare events and observations, are ubiquitous in medicine and critical to healthcare delivery, operations, and research. Despite this central role, EHRs are notoriously difficult to process automatically. Well over half of the information stored within EHRs is in the form of unstructured text (e.g. provider notes, operation reports) and remains largely untapped for secondary use. Recently, however, newer neural network and deep learning approaches to Natural Language Processing (NLP) have made considerable advances, outperforming traditional statistical and rule-based systems on a variety of tasks. In this survey paper, we summarize current neural NLP methods for EHR applications. We focus on a broad scope of tasks, namely, classification and prediction, word embeddings, extraction, generation, and other topics such as question answering, phenotyping, knowledge graphs, medical dialogue, multilinguality, interpretability, etc.
FeTaQA: Free-form Table Question Answering
Apr 01, 2021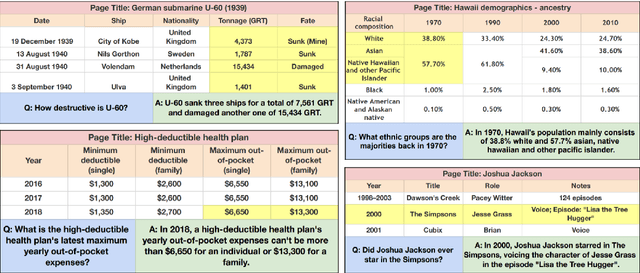

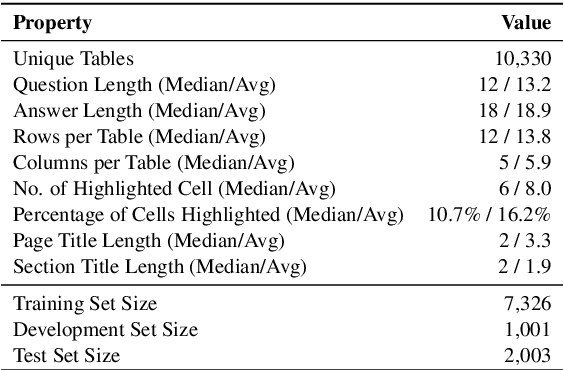
Existing table question answering datasets contain abundant factual questions that primarily evaluate the query and schema comprehension capability of a system, but they fail to include questions that require complex reasoning and integration of information due to the constraint of the associated short-form answers. To address these issues and to demonstrate the full challenge of table question answering, we introduce FeTaQA, a new dataset with 10K Wikipedia-based {table, question, free-form answer, supporting table cells} pairs. FeTaQA yields a more challenging table question answering setting because it requires generating free-form text answers after retrieval, inference, and integration of multiple discontinuous facts from a structured knowledge source. Unlike datasets of generative QA over text in which answers are prevalent with copies of short text spans from the source, answers in our dataset are human-generated explanations involving entities and their high-level relations. We provide two benchmark methods for the proposed task: a pipeline method based on semantic-parsing-based QA systems and an end-to-end method based on large pretrained text generation models, and show that FeTaQA poses a challenge for both methods.
DART: Open-Domain Structured Data Record to Text Generation
Jul 06, 2020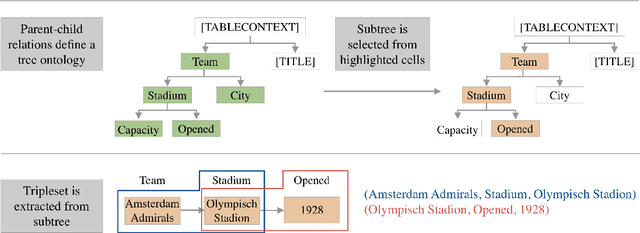
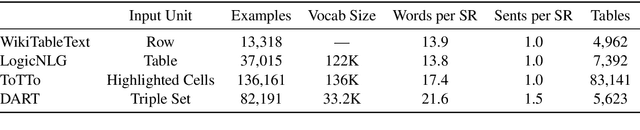
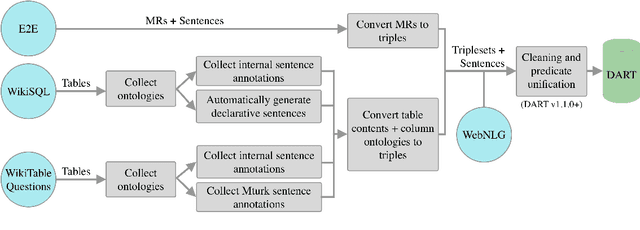
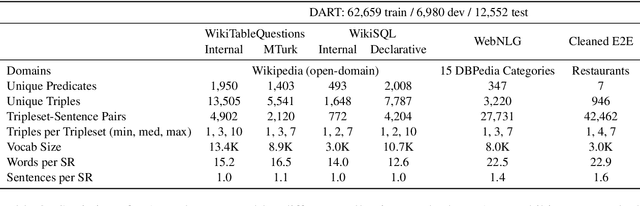
We introduce DART, a large dataset for open-domain structured data record to text generation. We consider the structured data record input as a set of RDF entity-relation triples, a format widely used for knowledge representation and semantics description. DART consists of 82,191 examples across different domains with each input being a semantic RDF triple set derived from data records in tables and the tree ontology of the schema, annotated with sentence descriptions that cover all facts in the triple set. This hierarchical, structured format with its open-domain nature differentiates DART from other existing table-to-text corpora. We conduct an analysis of DART on several state-of-the-art text generation models, showing that it introduces new and interesting challenges compared to existing datasets. Furthermore, we demonstrate that finetuning pretrained language models on DART facilitates out-of-domain generalization on the WebNLG 2017 dataset. DART is available at https://github.com/Yale-LILY/dart.
Improving Low-Resource Cross-lingual Document Retrieval by Reranking with Deep Bilingual Representations
Jun 08, 2019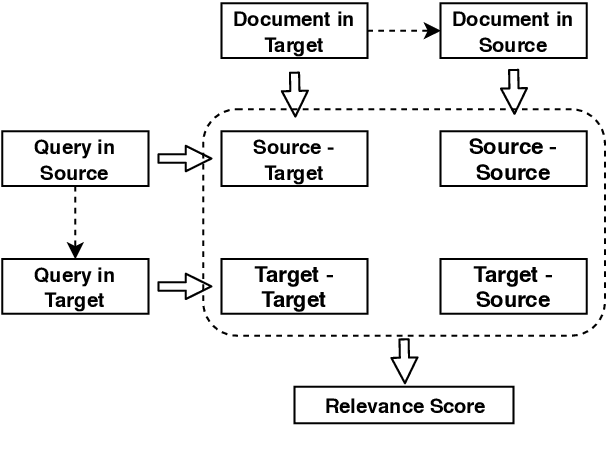
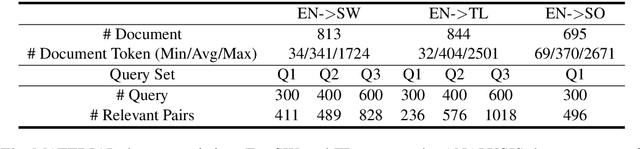

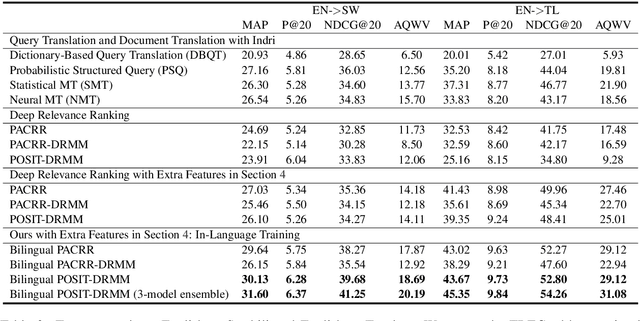
In this paper, we propose to boost low-resource cross-lingual document retrieval performance with deep bilingual query-document representations. We match queries and documents in both source and target languages with four components, each of which is implemented as a term interaction-based deep neural network with cross-lingual word embeddings as input. By including query likelihood scores as extra features, our model effectively learns to rerank the retrieved documents by using a small number of relevance labels for low-resource language pairs. Due to the shared cross-lingual word embedding space, the model can also be directly applied to another language pair without any training label. Experimental results on the MATERIAL dataset show that our model outperforms the competitive translation-based baselines on English-Swahili, English-Tagalog, and English-Somali cross-lingual information retrieval tasks.