 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP-FOLIO: Evaluating and Improving Logical Reasoning with Abundant Human-Written Reasoning Chains
Oct 11, 2024



Existing methods on understanding the capabilities of LLMs in logical reasoning rely on binary entailment classification or synthetically derived rationales, which are not sufficient for proper investigation of model's capabilities. We present P-FOLIO, a human-annotated dataset consisting of diverse and complex reasoning chains for a set of realistic logical reasoning stories also written by humans. P-FOLIO is collected with an annotation protocol that facilitates humans to annotate well-structured natural language proofs for first-order logic reasoning problems in a step-by-step manner. The number of reasoning steps in P-FOLIO span from 0 to 20. We further use P-FOLIO to evaluate and improve large-language-model (LLM) reasoning capabilities. We evaluate LLM reasoning capabilities at a fine granularity via single-step inference rule classification, with more diverse inference rules of more diverse and higher levels of complexities than previous works. Given that a single model-generated reasoning chain could take a completely different path than the human-annotated one, we sample multiple reasoning chains from a model and use pass@k metrics for evaluating the quality of model-generated reasoning chains. We show that human-written reasoning chains significantly boost the logical reasoning capabilities of LLMs via many-shot prompting and fine-tuning. Furthermore, fine-tuning Llama3-7B on P-FOLIO improves the model performance by 10% or more on three other out-of-domain logical reasoning datasets. We also conduct detailed analysis to show where most powerful LLMs fall short in reasoning. We will release the dataset and code publicly.
modeLing: A Novel Dataset for Testing Linguistic Reasoning in Language Models
Jun 24, 2024We introduce modeLing, a novel benchmark of Linguistics Olympiad-style puzzles which tests few-shot reasoning in AI systems. Solving these puzzles necessitates inferring aspects of a language's grammatical structure from a small number of examples. Such puzzles provide a natural testbed for language models, as they require compositional generalization and few-shot inductive reasoning. Consisting solely of new puzzles written specifically for this work, modeLing has no risk of appearing in the training data of existing AI systems: this ameliorates the risk of data leakage, a potential confounder for many prior evaluations of reasoning. Evaluating several large open source language models and GPT on our benchmark, we observe non-negligible accuracy, demonstrating few-shot emergent reasoning ability which cannot merely be attributed to shallow memorization. However, imperfect model performance suggests that modeLing can be used to measure further progress in linguistic reasoning.
MedGen: A Python Natural Language Processing Toolkit for Medical Text Processing
Nov 28, 2023
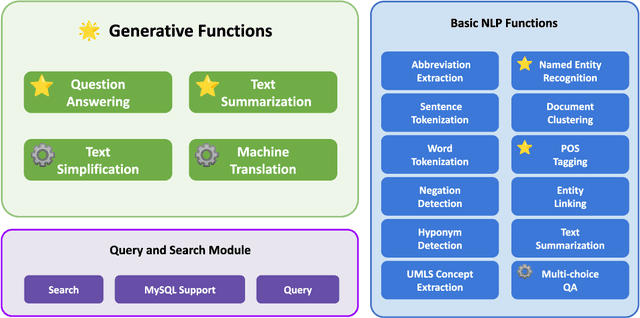
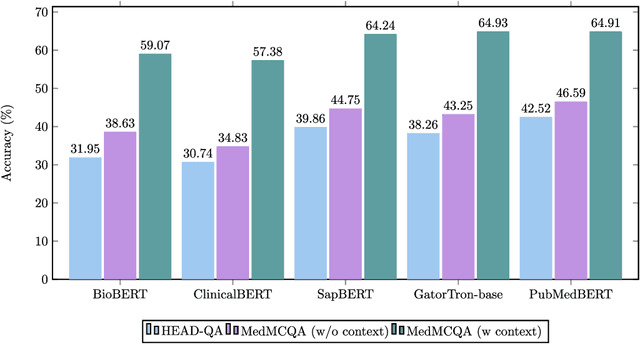
This study introduces MedGen, a comprehensive natural language processing (NLP) toolkit designed for medical text processing. MedGen is tailored for biomedical researchers and healthcare professionals with an easy-to-use, all-in-one solution that requires minimal programming expertise. It includes (1) Generative Functions: For the first time, MedGen includes four advanced generative functions: question answering, text summarization, text simplification, and machine translation; (2) Basic NLP Functions: MedGen integrates 12 essential NLP functions such as word tokenization and sentence segmentation; and (3) Query and Search Capabilities: MedGen provides user-friendly query and search functions on text corpora. We fine-tuned 32 domain-specific language models, evaluated them thoroughly on 24 established benchmarks and conducted manual reviews with clinicians. Additionally, we expanded our toolkit by introducing query and search functions, while also standardizing and integrating functions from third-party libraries. The toolkit, its models, and associated data are publicly available via https://github.com/Yale-LILY/MedGen.
Benchmarking Generation and Evaluation Capabilities of Large Language Models for Instruction Controllable Summarization
Nov 15, 2023While large language models (LLMs) already achieve strong performance on standard generic summarization benchmarks, their performance on more complex summarization task settings is less studied. Therefore, we benchmark LLMs on instruction controllable text summarization, where the model input consists of both a source article and a natural language requirement for the desired summary characteristics. To this end, we curate an evaluation-only dataset for this task setting and conduct human evaluation on 5 LLM-based summarization systems. We then benchmark LLM-based automatic evaluation for this task with 4 different evaluation protocols and 11 LLMs, resulting in 40 evaluation methods in total. Our study reveals that instruction controllable text summarization remains a challenging task for LLMs, since (1) all LLMs evaluated still make factual and other types of errors in their summaries; (2) all LLM-based evaluation methods cannot achieve a strong alignment with human annotators when judging the quality of candidate summaries; (3) different LLMs show large performance gaps in summary generation and evaluation. We make our collected benchmark, InstruSum, publicly available to facilitate future research in this direction.
Fair Abstractive Summarization of Diverse Perspectives
Nov 14, 2023



People from different social and demographic groups express diverse perspectives and conflicting opinions on a broad set of topics such as product reviews, healthcare, law, and politics. A fair summary should provide a comprehensive coverage of diverse perspectives without underrepresenting certain groups. However, current work in summarization metrics and Large Language Models (LLMs) evaluation has not explored fair abstractive summarization. In this paper, we systematically investigate fair abstractive summarization for user-generated data. We first formally define fairness in abstractive summarization as not underrepresenting perspectives of any groups of people and propose four reference-free automatic metrics measuring the differences between target and source perspectives. We evaluate five LLMs, including three GPT models, Alpaca, and Claude, on six datasets collected from social media, online reviews, and recorded transcripts. Experiments show that both the model-generated and the human-written reference summaries suffer from low fairness. We conduct a comprehensive analysis of the common factors influencing fairness and propose three simple but effective methods to alleviate unfair summarization. Our dataset and code are available at https://github.com/psunlpgroup/FairSumm.
L2CEval: Evaluating Language-to-Code Generation Capabilities of Large Language Models
Oct 02, 2023Recently, large language models (LLMs), especially those that are pretrained on code, have demonstrated strong capabilities in generating programs from natural language inputs in a few-shot or even zero-shot manner. Despite promising results, there is a notable lack of a comprehensive evaluation of these models language-to-code generation capabilities. Existing studies often focus on specific tasks, model architectures, or learning paradigms, leading to a fragmented understanding of the overall landscape. In this work, we present L2CEval, a systematic evaluation of the language-to-code generation capabilities of LLMs on 7 tasks across the domain spectrum of semantic parsing, math reasoning and Python programming, analyzing the factors that potentially affect their performance, such as model size, pretraining data, instruction tuning, and different prompting methods. In addition to assessing model performance, we measure confidence calibration for the models and conduct human evaluations of the output programs. This enables us to identify and analyze the typical failure modes across various tasks and models. L2CEval offers a comprehensive understanding of the capabilities and limitations of LLMs in language-to-code generation. We also release the evaluation framework and all model outputs, hoping to lay the groundwork for further future research in this domain.
RobuT: A Systematic Study of Table QA Robustness Against Human-Annotated Adversarial Perturbations
Jun 25, 2023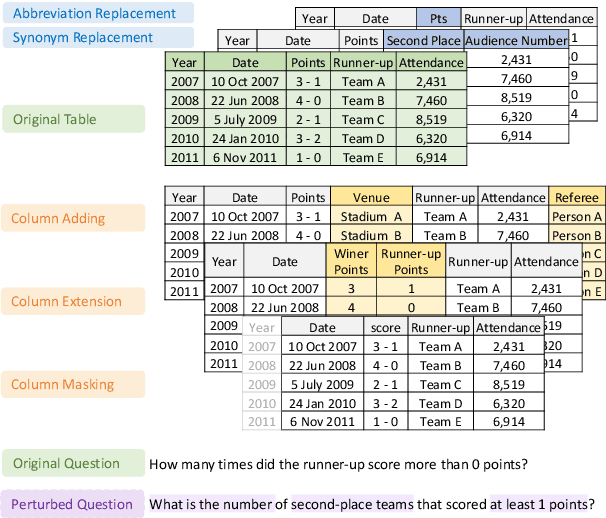

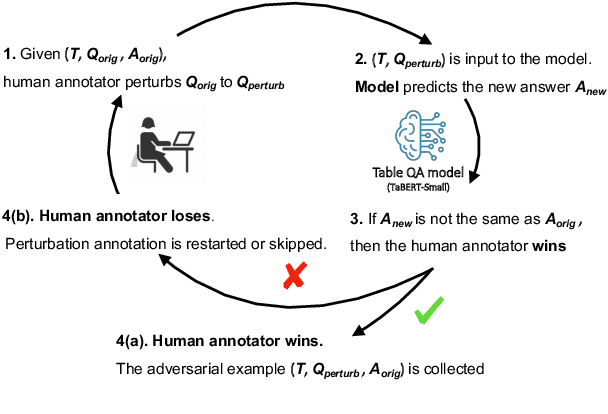
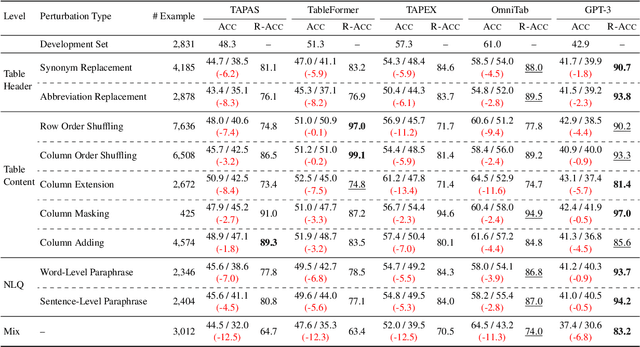
Despite significant progress having been made in question answering on tabular data (Table QA), it's unclear whether, and to what extent existing Table QA models are robust to task-specific perturbations, e.g., replacing key question entities or shuffling table columns. To systematically study the robustness of Table QA models, we propose a benchmark called RobuT, which builds upon existing Table QA datasets (WTQ, WikiSQL-Weak, and SQA) and includes human-annotated adversarial perturbations in terms of table header, table content, and question. Our results indicate that both state-of-the-art Table QA models and large language models (e.g., GPT-3) with few-shot learning falter in these adversarial sets. We propose to address this problem by using large language models to generate adversarial examples to enhance training, which significantly improves the robustness of Table QA models. Our data and code is publicly available at https://github.com/yilunzhao/RobuT.
bgGLUE: A Bulgarian General Language Understanding Evaluation Benchmark
Jun 07, 2023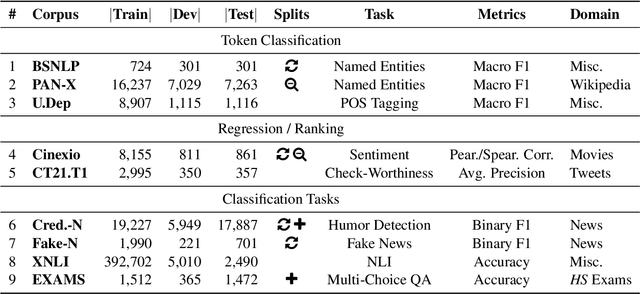
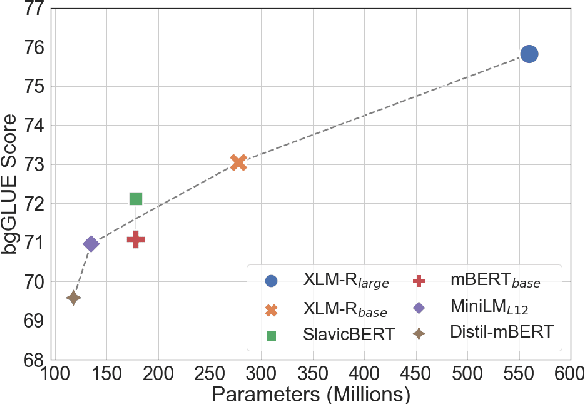

We present bgGLUE(Bulgarian General Language Understanding Evaluation), a benchmark for evaluating language models on Natural Language Understanding (NLU) tasks in Bulgarian. Our benchmark includes NLU tasks targeting a variety of NLP problems (e.g., natural language inference, fact-checking, named entity recognition, sentiment analysis, question answering, etc.) and machine learning tasks (sequence labeling, document-level classification, and regression). We run the first systematic evaluation of pre-trained language models for Bulgarian, comparing and contrasting results across the nine tasks in the benchmark. The evaluation results show strong performance on sequence labeling tasks, but there is a lot of room for improvement for tasks that require more complex reasoning. We make bgGLUE publicly available together with the fine-tuning and the evaluation code, as well as a public leaderboard at https://bgglue.github.io/, and we hope that it will enable further advancements in developing NLU models for Bulgarian.
* Accepted to ACL 2023 (Main Conference)
QTSumm: A New Benchmark for Query-Focused Table Summarization
May 23, 2023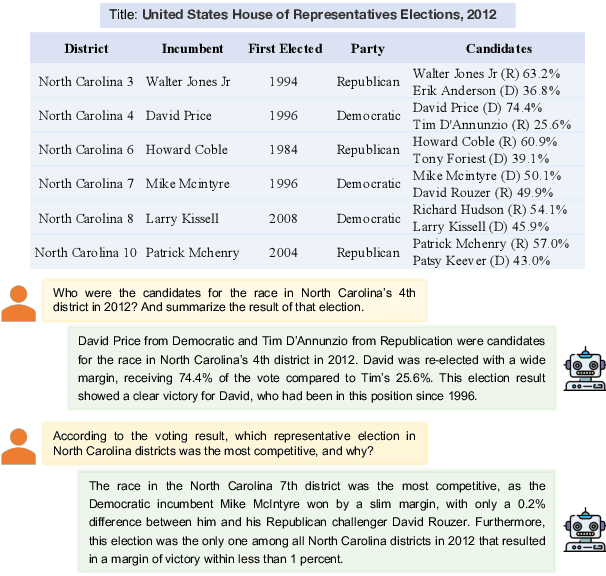
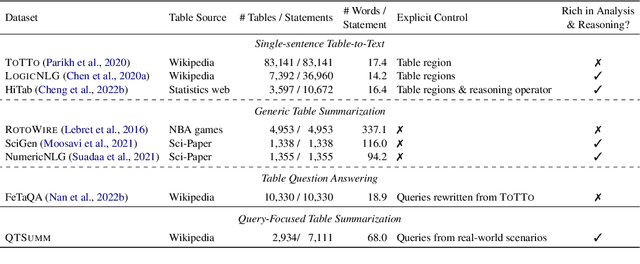

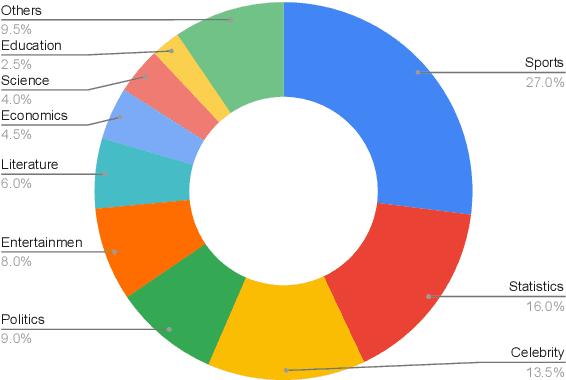
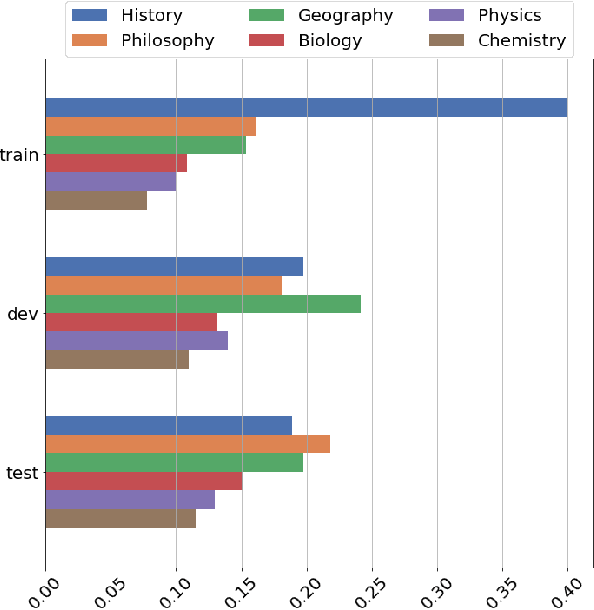
People primarily consult tables to conduct data analysis or answer specific questions. Text generation systems that can provide accurate table summaries tailored to users' information needs can facilitate more efficient access to relevant data insights. However, existing table-to-text generation studies primarily focus on converting tabular data into coherent statements, rather than addressing information-seeking purposes. In this paper, we define a new query-focused table summarization task, where text generation models have to perform human-like reasoning and analysis over the given table to generate a tailored summary, and we introduce a new benchmark named QTSumm for this task. QTSumm consists of 5,625 human-annotated query-summary pairs over 2,437 tables on diverse topics. Moreover, we investigate state-of-the-art models (i.e., text generation, table-to-text generation, and large language models) on the QTSumm dataset. Experimental results and manual analysis reveal that our benchmark presents significant challenges in table-to-text generation for future research.
On Learning to Summarize with Large Language Models as References
May 23, 2023



Recent studies have found that summaries generated by large language models (LLMs) are favored by human annotators over the original reference summaries in commonly used summarization datasets. Therefore, we investigate a new learning paradigm of text summarization models that considers the LLMs as the reference or the gold-standard oracle on commonly used summarization datasets such as the CNN/DailyMail dataset. To examine the standard practices that are aligned with the new learning setting, we propose a novel training method that is based on contrastive learning with LLMs as a summarization quality evaluator. For this reward-based training method, we investigate two different methods of utilizing LLMs for summary quality evaluation, namely GPTScore and GPTRank. Our experiments on the CNN/DailyMail dataset demonstrate that smaller summarization models trained by our proposed method can achieve performance equal to or surpass that of the reference LLMs, as evaluated by the LLMs themselves. This underscores the efficacy of our proposed paradigm in enhancing model performance over the standard maximum likelihood estimation (MLE) training method, and its efficiency since it only requires a small budget to access the LLMs. We release the training scripts, model outputs, and LLM-based evaluation results to facilitate future studies.