 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgebgGLUE: A Bulgarian General Language Understanding Evaluation Benchmark
Jun 07, 2023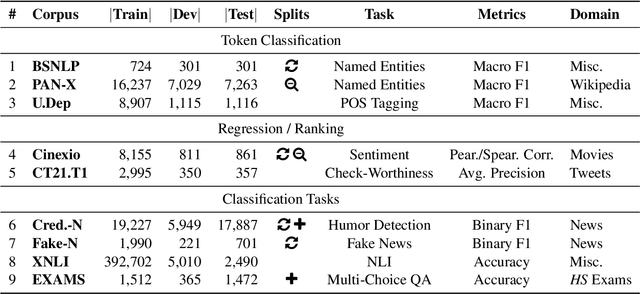
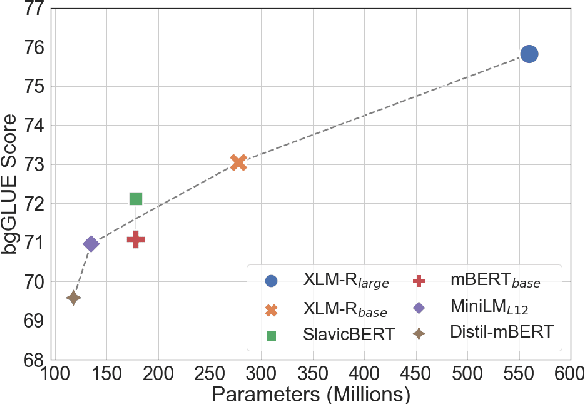

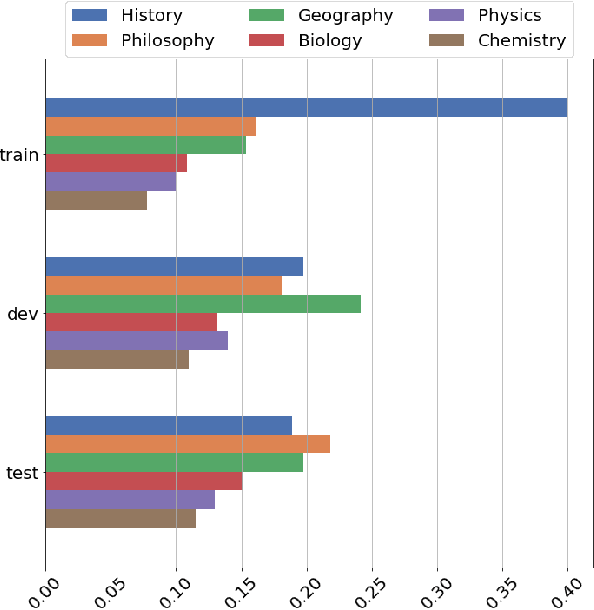
We present bgGLUE(Bulgarian General Language Understanding Evaluation), a benchmark for evaluating language models on Natural Language Understanding (NLU) tasks in Bulgarian. Our benchmark includes NLU tasks targeting a variety of NLP problems (e.g., natural language inference, fact-checking, named entity recognition, sentiment analysis, question answering, etc.) and machine learning tasks (sequence labeling, document-level classification, and regression). We run the first systematic evaluation of pre-trained language models for Bulgarian, comparing and contrasting results across the nine tasks in the benchmark. The evaluation results show strong performance on sequence labeling tasks, but there is a lot of room for improvement for tasks that require more complex reasoning. We make bgGLUE publicly available together with the fine-tuning and the evaluation code, as well as a public leaderboard at https://bgglue.github.io/, and we hope that it will enable further advancements in developing NLU models for Bulgarian.
* Accepted to ACL 2023 (Main Conference)
SUper Team at SemEval-2016 Task 3: Building a feature-rich system for community question answering
Sep 26, 2021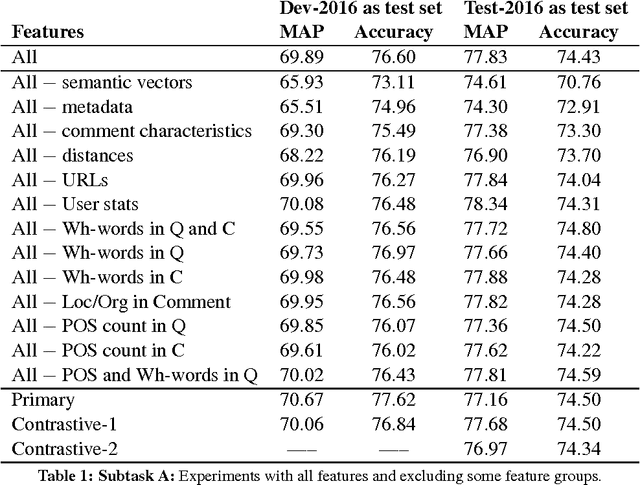
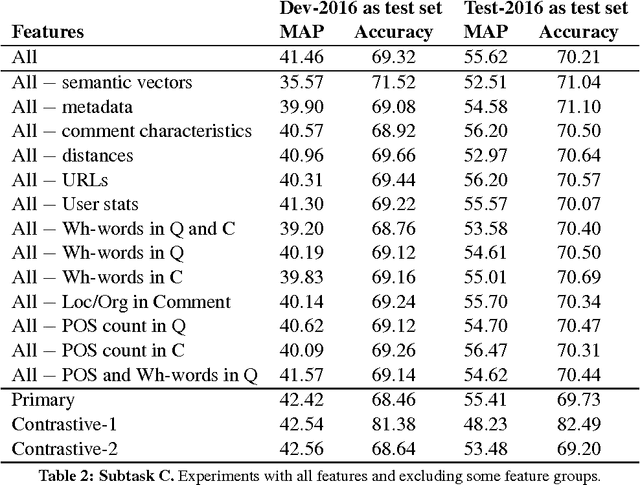
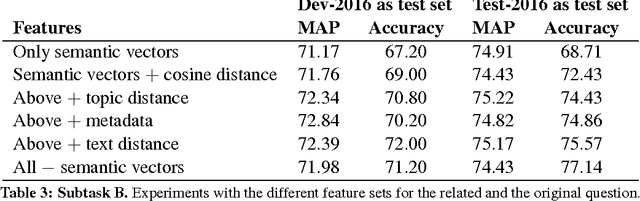
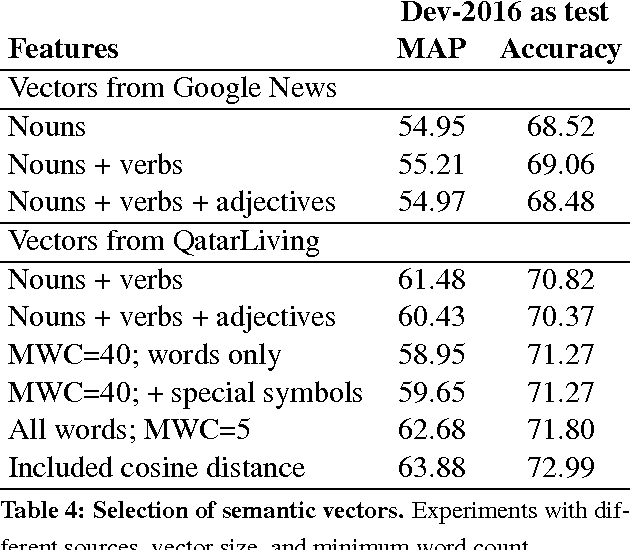
We present the system we built for participating in SemEval-2016 Task 3 on Community Question Answering. We achieved the best results on subtask C, and strong results on subtasks A and B, by combining a rich set of various types of features: semantic, lexical, metadata, and user-related. The most important group turned out to be the metadata for the question and for the comment, semantic vectors trained on QatarLiving data and similarities between the question and the comment for subtasks A and C, and between the original and the related question for Subtask B.
* community question answering, question-question similarity, question-comment similarity, answer reranking
Towards Constructing a Corpus for Studying the Effects of Treatments and Substances Reported in PubMed Abstracts
Dec 04, 2019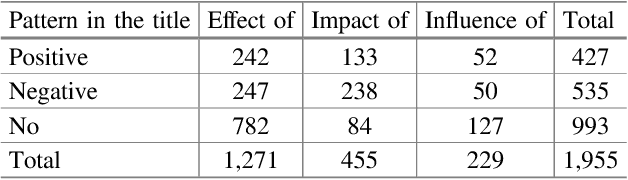

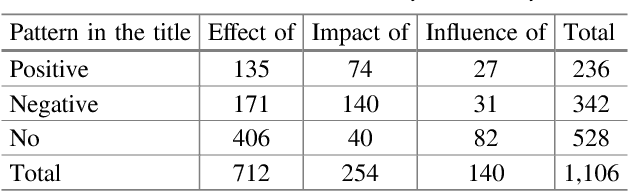

We present the construction of an annotated corpus of PubMed abstracts reporting about positive, negative or neutral effects of treatments or substances. Our ultimate goal is to annotate one sentence (rationale) for each abstract and to use this resource as a training set for text classification of effects discussed in PubMed abstracts. Currently, the corpus consists of 750 abstracts. We describe the automatic processing that supports the corpus construction, the manual annotation activities and some features of the medical language in the abstracts selected for the annotated corpus. It turns out that recognizing the terminology and the abbreviations is key for determining the rationale sentence. The corpus will be applied to improve our classifier, which currently has accuracy of 78.80% achieved with normalization of the abstract terms based on UMLS concepts from specific semantic groups and an SVM with a linear kernel. Finally, we discuss some other possible applications of this corpus.
* medical relation extraction, rationale extraction, effects and treatments, bioNLP