 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing LLMs for Multilingual Clinical Entity Linking to ICD-10
Sep 05, 2025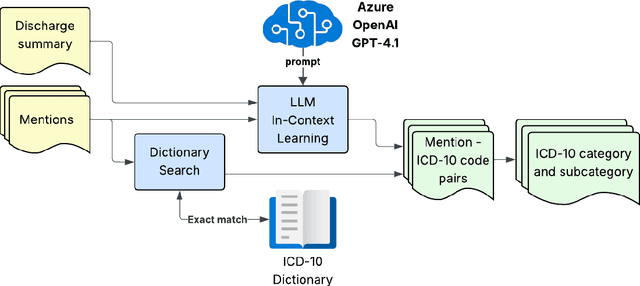


The linking of clinical entities is a crucial part of extracting structured information from clinical texts. It is the process of assigning a code from a medical ontology or classification to a phrase in the text. The International Classification of Diseases - 10th revision (ICD-10) is an international standard for classifying diseases for statistical and insurance purposes. Automatically assigning the correct ICD-10 code to terms in discharge summaries will simplify the work of healthcare professionals and ensure consistent coding in hospitals. Our paper proposes an approach for linking clinical terms to ICD-10 codes in different languages using Large Language Models (LLMs). The approach consists of a multistage pipeline that uses clinical dictionaries to match unambiguous terms in the text and then applies in-context learning with GPT-4.1 to predict the ICD-10 code for the terms that do not match the dictionary. Our system shows promising results in predicting ICD-10 codes on different benchmark datasets in Spanish - 0.89 F1 for categories and 0.78 F1 on subcategories on CodiEsp, and Greek - 0.85 F1 on ElCardioCC.
Post-OCR Text Correction for Bulgarian Historical Documents
Aug 31, 2024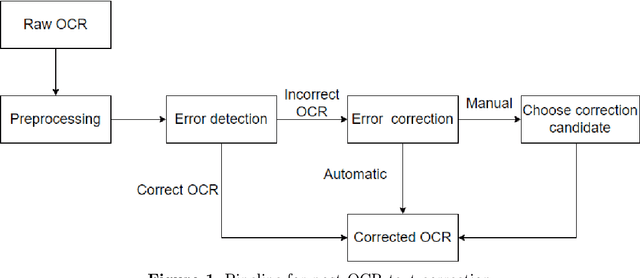



The digitization of historical documents is crucial for preserving the cultural heritage of the society. An important step in this process is converting scanned images to text using Optical Character Recognition (OCR), which can enable further search, information extraction, etc. Unfortunately, this is a hard problem as standard OCR tools are not tailored to deal with historical orthography as well as with challenging layouts. Thus, it is standard to apply an additional text correction step on the OCR output when dealing with such documents. In this work, we focus on Bulgarian, and we create the first benchmark dataset for evaluating the OCR text correction for historical Bulgarian documents written in the first standardized Bulgarian orthography: the Drinov orthography from the 19th century. We further develop a method for automatically generating synthetic data in this orthography, as well as in the subsequent Ivanchev orthography, by leveraging vast amounts of contemporary literature Bulgarian texts. We then use state-of-the-art LLMs and encoder-decoder framework which we augment with diagonal attention loss and copy and coverage mechanisms to improve the post-OCR text correction. The proposed method reduces the errors introduced during recognition and improves the quality of the documents by 25\%, which is an increase of 16\% compared to the state-of-the-art on the ICDAR 2019 Bulgarian dataset. We release our data and code at \url{https://github.com/angelbeshirov/post-ocr-text-correction}.}
EXAMS-V: A Multi-Discipline Multilingual Multimodal Exam Benchmark for Evaluating Vision Language Models
Mar 15, 2024



We introduce EXAMS-V, a new challenging multi-discipline multimodal multilingual exam benchmark for evaluating vision language models. It consists of 20,932 multiple-choice questions across 20 school disciplines covering natural science, social science, and other miscellaneous studies, e.g., religion, fine arts, business, etc. EXAMS-V includes a variety of multimodal features such as text, images, tables, figures, diagrams, maps, scientific symbols, and equations. The questions come in 11 languages from 7 language families. Unlike existing benchmarks, EXAMS-V is uniquely curated by gathering school exam questions from various countries, with a variety of education systems. This distinctive approach calls for intricate reasoning across diverse languages and relies on region-specific knowledge. Solving the problems in the dataset requires advanced perception and joint reasoning over the text and the visual content of the image. Our evaluation results demonstrate that this is a challenging dataset, which is difficult even for advanced vision-text models such as GPT-4V and Gemini; this underscores the inherent complexity of the dataset and its significance as a future benchmark.
FedSym: Unleashing the Power of Entropy for Benchmarking the Algorithms for Federated Learning
Oct 11, 2023Federated learning (FL) is a decentralized machine learning approach where independent learners process data privately. Its goal is to create a robust and accurate model by aggregating and retraining local models over multiple rounds. However, FL faces challenges regarding data heterogeneity and model aggregation effectiveness. In order to simulate real-world data, researchers use methods for data partitioning that transform a dataset designated for centralized learning into a group of sub-datasets suitable for distributed machine learning with different data heterogeneity. In this paper, we study the currently popular data partitioning techniques and visualize their main disadvantages: the lack of precision in the data diversity, which leads to unreliable heterogeneity indexes, and the inability to incrementally challenge the FL algorithms. To resolve this problem, we propose a method that leverages entropy and symmetry to construct 'the most challenging' and controllable data distributions with gradual difficulty. We introduce a metric to measure data heterogeneity among the learning agents and a transformation technique that divides any dataset into splits with precise data diversity. Through a comparative study, we demonstrate the superiority of our method over existing FL data partitioning approaches, showcasing its potential to challenge model aggregation algorithms. Experimental results indicate that our approach gradually challenges the FL strategies, and the models trained on FedSym distributions are more distinct.
Gpachov at CheckThat! 2023: A Diverse Multi-Approach Ensemble for Subjectivity Detection in News Articles
Sep 13, 2023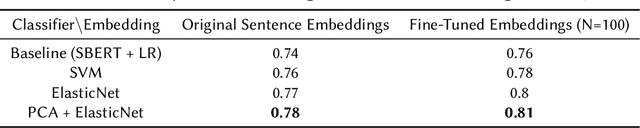
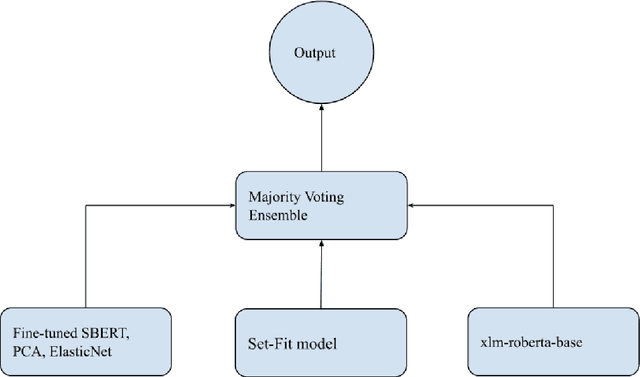
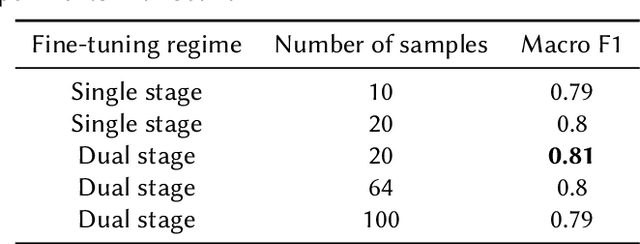
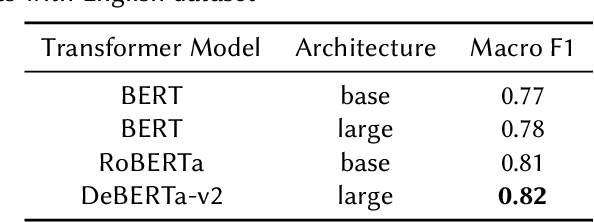
The wide-spread use of social networks has given rise to subjective, misleading, and even false information on the Internet. Thus, subjectivity detection can play an important role in ensuring the objectiveness and the quality of a piece of information. This paper presents the solution built by the Gpachov team for the CLEF-2023 CheckThat! lab Task~2 on subjectivity detection. Three different research directions are explored. The first one is based on fine-tuning a sentence embeddings encoder model and dimensionality reduction. The second one explores a sample-efficient few-shot learning model. The third one evaluates fine-tuning a multilingual transformer on an altered dataset, using data from multiple languages. Finally, the three approaches are combined in a simple majority voting ensemble, resulting in 0.77 macro F1 on the test set and achieving 2nd place on the English subtask.
bgGLUE: A Bulgarian General Language Understanding Evaluation Benchmark
Jun 07, 2023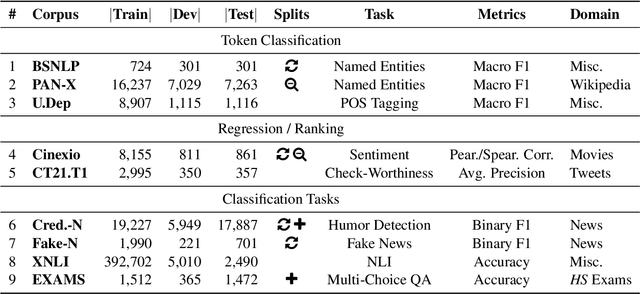
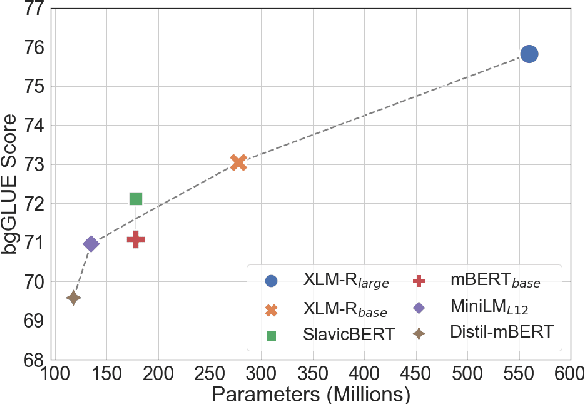

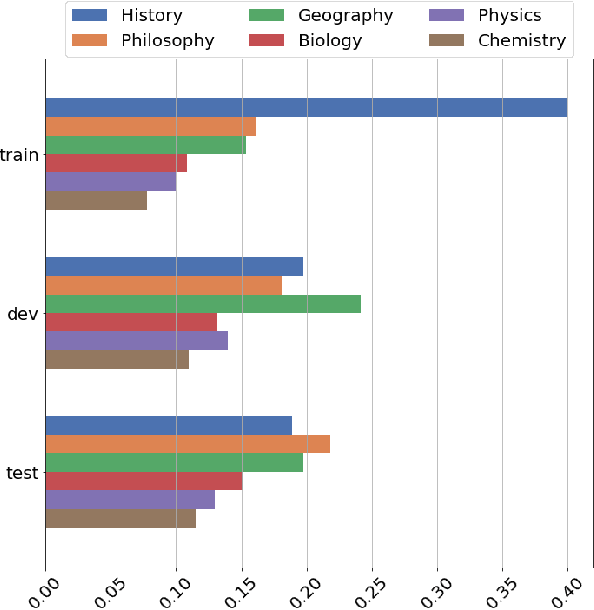
We present bgGLUE(Bulgarian General Language Understanding Evaluation), a benchmark for evaluating language models on Natural Language Understanding (NLU) tasks in Bulgarian. Our benchmark includes NLU tasks targeting a variety of NLP problems (e.g., natural language inference, fact-checking, named entity recognition, sentiment analysis, question answering, etc.) and machine learning tasks (sequence labeling, document-level classification, and regression). We run the first systematic evaluation of pre-trained language models for Bulgarian, comparing and contrasting results across the nine tasks in the benchmark. The evaluation results show strong performance on sequence labeling tasks, but there is a lot of room for improvement for tasks that require more complex reasoning. We make bgGLUE publicly available together with the fine-tuning and the evaluation code, as well as a public leaderboard at https://bgglue.github.io/, and we hope that it will enable further advancements in developing NLU models for Bulgarian.
* Accepted to ACL 2023 (Main Conference)
DuoSearch: A Novel Search Engine for Bulgarian Historical Documents
May 30, 2023Search in collections of digitised historical documents is hindered by a two-prong problem, orthographic variety and optical character recognition (OCR) mistakes. We present a new search engine for historical documents, DuoSearch, which uses ElasticSearch and machine learning methods based on deep neural networks to offer a solution to this problem. It was tested on a collection of historical newspapers in Bulgarian from the mid-19th to the mid-20th century. The system provides an interactive and intuitive interface for the end-users allowing them to enter search terms in modern Bulgarian and search across historical spellings. This is the first solution facilitating the use of digitised historical documents in Bulgarian.
CrowdChecked: Detecting Previously Fact-Checked Claims in Social Media
Oct 10, 2022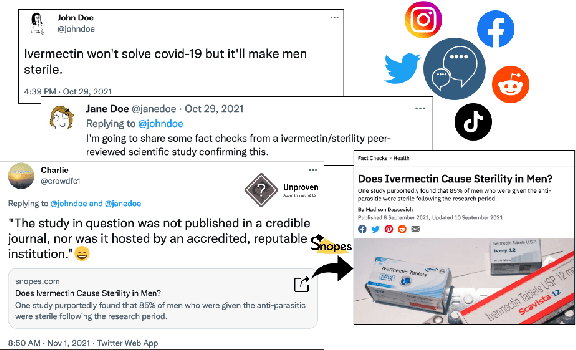
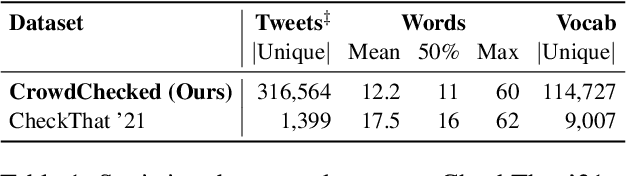
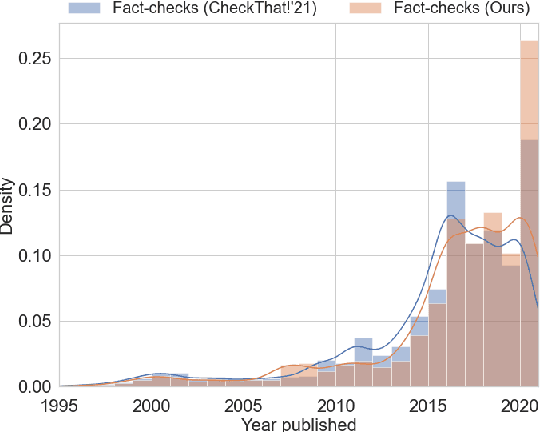
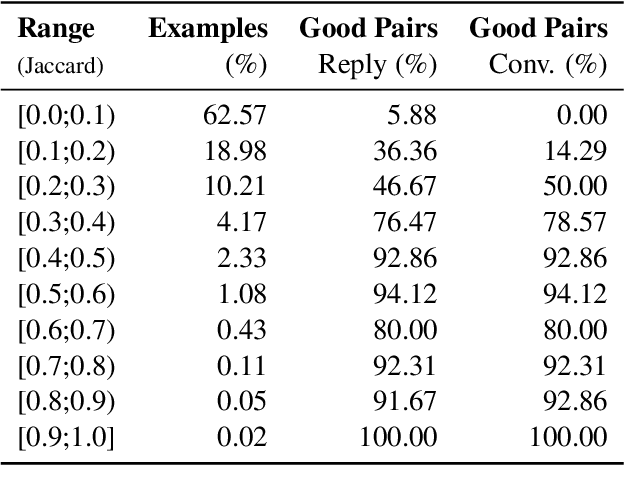
While there has been substantial progress in developing systems to automate fact-checking, they still lack credibility in the eyes of the users. Thus, an interesting approach has emerged: to perform automatic fact-checking by verifying whether an input claim has been previously fact-checked by professional fact-checkers and to return back an article that explains their decision. This is a sensible approach as people trust manual fact-checking, and as many claims are repeated multiple times. Yet, a major issue when building such systems is the small number of known tweet--verifying article pairs available for training. Here, we aim to bridge this gap by making use of crowd fact-checking, i.e., mining claims in social media for which users have responded with a link to a fact-checking article. In particular, we mine a large-scale collection of 330,000 tweets paired with a corresponding fact-checking article. We further propose an end-to-end framework to learn from this noisy data based on modified self-adaptive training, in a distant supervision scenario. Our experiments on the CLEF'21 CheckThat! test set show improvements over the state of the art by two points absolute. Our code and datasets are available at https://github.com/mhardalov/crowdchecked-claims
* Accepted to AACL-IJCNLP 2022 (Main Conference)
Leaf: Multiple-Choice Question Generation
Jan 22, 2022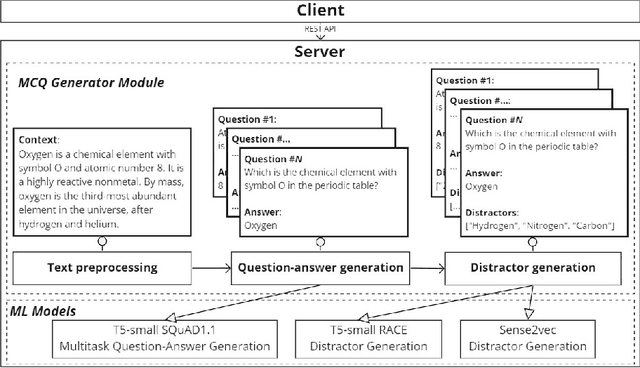
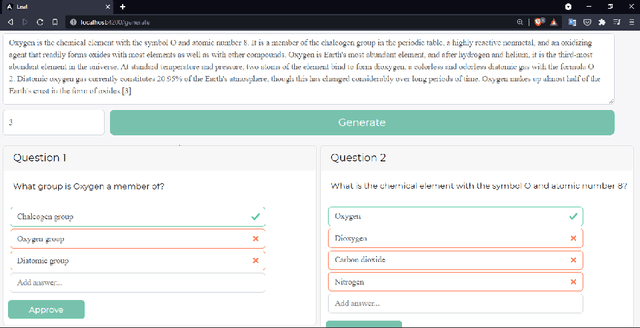
Testing with quiz questions has proven to be an effective way to assess and improve the educational process. However, manually creating quizzes is tedious and time-consuming. To address this challenge, we present Leaf, a system for generating multiple-choice questions from factual text. In addition to being very well suited for the classroom, Leaf could also be used in an industrial setting, e.g., to facilitate onboarding and knowledge sharing, or as a component of chatbots, question answering systems, or Massive Open Online Courses (MOOCs). The code and the demo are available on https://github.com/KristiyanVachev/Leaf-Question-Generation.
SUper Team at SemEval-2016 Task 3: Building a feature-rich system for community question answering
Sep 26, 2021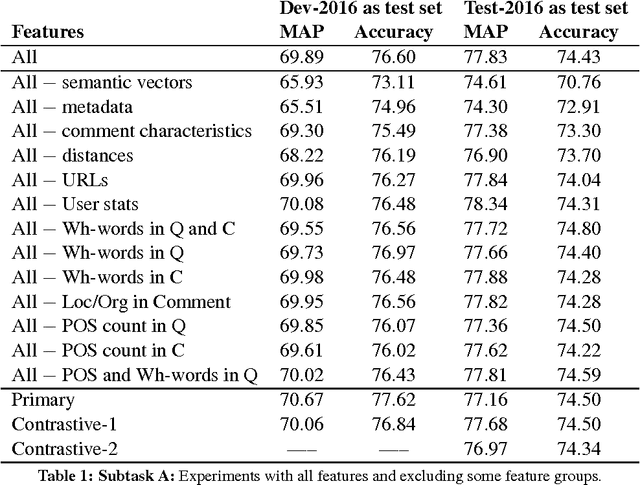
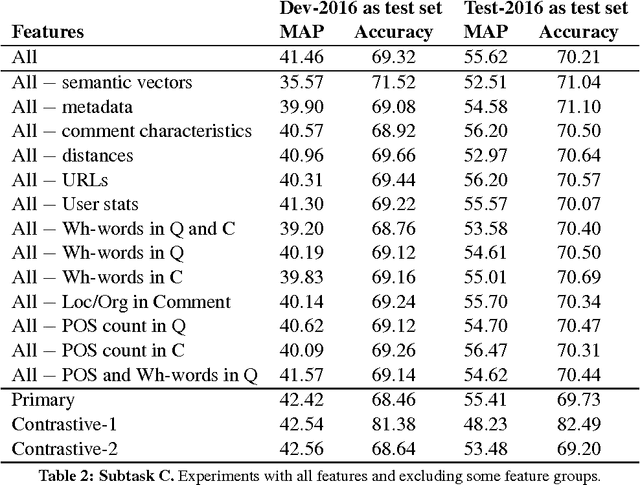
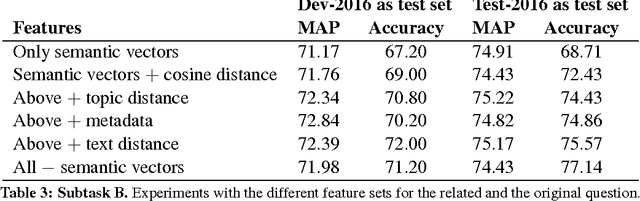
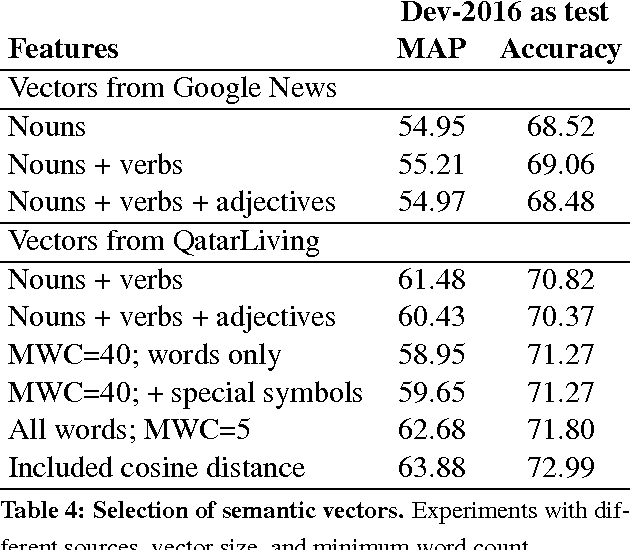
We present the system we built for participating in SemEval-2016 Task 3 on Community Question Answering. We achieved the best results on subtask C, and strong results on subtasks A and B, by combining a rich set of various types of features: semantic, lexical, metadata, and user-related. The most important group turned out to be the metadata for the question and for the comment, semantic vectors trained on QatarLiving data and similarities between the question and the comment for subtasks A and C, and between the original and the related question for Subtask B.
* community question answering, question-question similarity, question-comment similarity, answer reranking