 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgebgGLUE: A Bulgarian General Language Understanding Evaluation Benchmark
Jun 07, 2023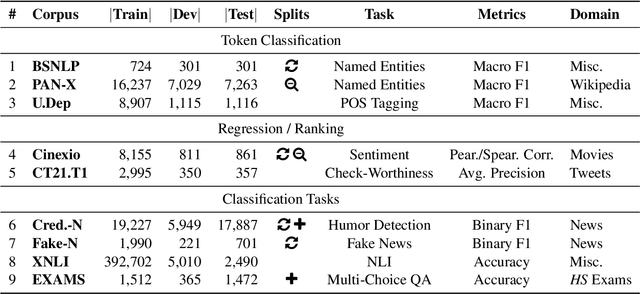
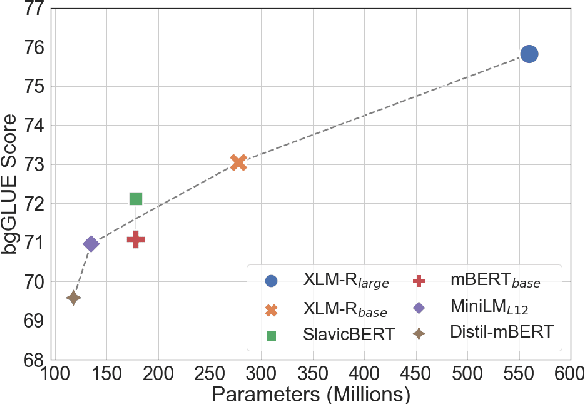

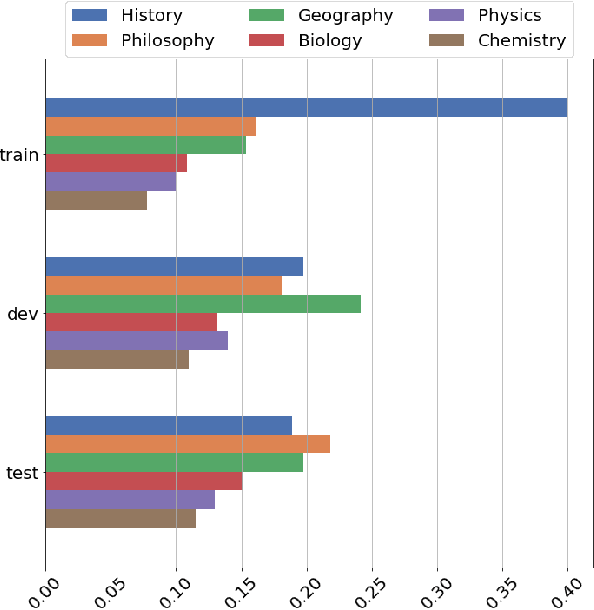
We present bgGLUE(Bulgarian General Language Understanding Evaluation), a benchmark for evaluating language models on Natural Language Understanding (NLU) tasks in Bulgarian. Our benchmark includes NLU tasks targeting a variety of NLP problems (e.g., natural language inference, fact-checking, named entity recognition, sentiment analysis, question answering, etc.) and machine learning tasks (sequence labeling, document-level classification, and regression). We run the first systematic evaluation of pre-trained language models for Bulgarian, comparing and contrasting results across the nine tasks in the benchmark. The evaluation results show strong performance on sequence labeling tasks, but there is a lot of room for improvement for tasks that require more complex reasoning. We make bgGLUE publicly available together with the fine-tuning and the evaluation code, as well as a public leaderboard at https://bgglue.github.io/, and we hope that it will enable further advancements in developing NLU models for Bulgarian.
* Accepted to ACL 2023 (Main Conference)
Feature-Rich Part-of-speech Tagging for Morphologically Complex Languages: Application to Bulgarian
Nov 26, 2019
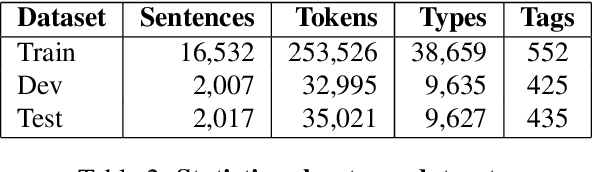

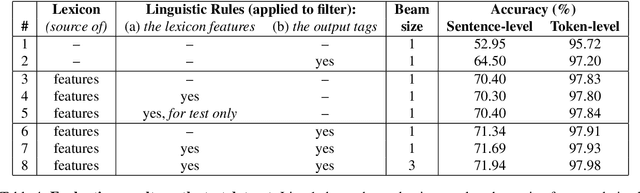
We present experiments with part-of-speech tagging for Bulgarian, a Slavic language with rich inflectional and derivational morphology. Unlike most previous work, which has used a small number of grammatical categories, we work with 680 morpho-syntactic tags. We combine a large morphological lexicon with prior linguistic knowledge and guided learning from a POS-annotated corpus, achieving accuracy of 97.98%, which is a significant improvement over the state-of-the-art for Bulgarian.
* part-of-speech tagging, POS tagging, morpho-syntactic tags, guided learning, Bulgarian, Slavic
A Morpho-Syntactically Informed LSTM-CRF Model for Named Entity Recognition
Aug 27, 2019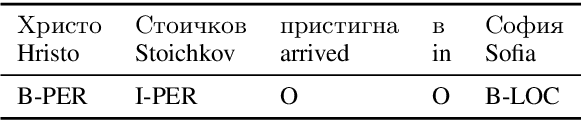
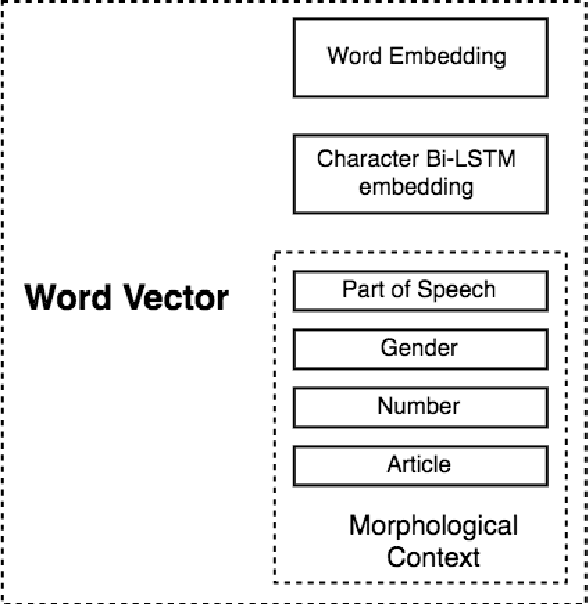


We propose a morphologically informed model for named entity recognition, which is based on LSTM-CRF architecture and combines word embeddings, Bi-LSTM character embeddings, part-of-speech (POS) tags, and morphological information. While previous work has focused on learning from raw word input, using word and character embeddings only, we show that for morphologically rich languages, such as Bulgarian, access to POS information contributes more to the performance gains than the detailed morphological information. Thus, we show that named entity recognition needs only coarse-grained POS tags, but at the same time it can benefit from simultaneously using some POS information of different granularity. Our evaluation results over a standard dataset show sizable improvements over the state-of-the-art for Bulgarian NER.
* named entity recognition; Bulgarian NER; morphology; morpho-syntax