 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Correlating and Predicting Human Evaluations of Language Models from Natural Language Processing Benchmarks
Feb 24, 2025



The explosion of high-performing conversational language models (LMs) has spurred a shift from classic natural language processing (NLP) benchmarks to expensive, time-consuming and noisy human evaluations - yet the relationship between these two evaluation strategies remains hazy. In this paper, we conduct a large-scale study of four Chat Llama 2 models, comparing their performance on 160 standard NLP benchmarks (e.g., MMLU, ARC, BIG-Bench Hard) against extensive human preferences on more than 11k single-turn and 2k multi-turn dialogues from over 2k human annotators. Our findings are striking: most NLP benchmarks strongly correlate with human evaluations, suggesting that cheaper, automated metrics can serve as surprisingly reliable predictors of human preferences. Three human evaluations, such as adversarial dishonesty and safety, are anticorrelated with NLP benchmarks, while two are uncorrelated. Moreover, through overparameterized linear regressions, we show that NLP scores can accurately predict human evaluations across different model scales, offering a path to reduce costly human annotation without sacrificing rigor. Overall, our results affirm the continued value of classic benchmarks and illuminate how to harness them to anticipate real-world user satisfaction - pointing to how NLP benchmarks can be leveraged to meet evaluation needs of our new era of conversational AI.
Optimizing Pretraining Data Mixtures with LLM-Estimated Utility
Jan 20, 2025


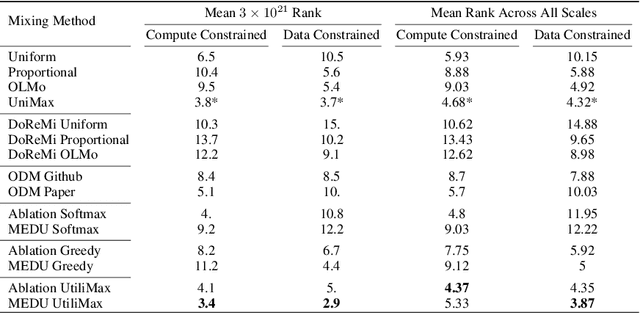
Large Language Models improve with increasing amounts of high-quality training data. However, leveraging larger datasets requires balancing quality, quantity, and diversity across sources. After evaluating nine baseline methods under both compute- and data-constrained scenarios, we find token-count heuristics outperform manual and learned mixes, indicating that simple approaches accounting for dataset size and diversity are surprisingly effective. Building on this insight, we propose two complementary approaches: UtiliMax, which extends token-based heuristics by incorporating utility estimates from reduced-scale ablations, achieving up to a 10.6x speedup over manual baselines; and Model Estimated Data Utility (MEDU), which leverages LLMs to estimate data utility from small samples, matching ablation-based performance while reducing computational requirements by $\sim$200x. Together, these approaches establish a new framework for automated, compute-efficient data mixing that is robust across training regimes.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Llama 2: Open Foundation and Fine-Tuned Chat Models
Jul 19, 2023



In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. Our models outperform open-source chat models on most benchmarks we tested, and based on our human evaluations for helpfulness and safety, may be a suitable substitute for closed-source models. We provide a detailed description of our approach to fine-tuning and safety improvements of Llama 2-Chat in order to enable the community to build on our work and contribute to the responsible development of LLMs.
Understanding In-Context Learning via Supportive Pretraining Data
Jun 26, 2023



In-context learning (ICL) improves language models' performance on a variety of NLP tasks by simply demonstrating a handful of examples at inference time. It is not well understood why ICL ability emerges, as the model has never been specifically trained on such demonstrations. Unlike prior work that explores implicit mechanisms behind ICL, we study ICL via investigating the pretraining data. Specifically, we first adapt an iterative, gradient-based approach to find a small subset of pretraining data that supports ICL. We observe that a continued pretraining on this small subset significantly improves the model's ICL ability, by up to 18%. We then compare the supportive subset constrastively with random subsets of pretraining data and discover: (1) The supportive pretraining data to ICL do not have a higher domain relevance to downstream tasks. (2) The supportive pretraining data have a higher mass of rarely occurring, long-tail tokens. (3) The supportive pretraining data are challenging examples where the information gain from long-range context is below average, indicating learning to incorporate difficult long-range context encourages ICL. Our work takes a first step towards understanding ICL via analyzing instance-level pretraining data. Our insights have a potential to enhance the ICL ability of language models by actively guiding the construction of pretraining data in the future.
bgGLUE: A Bulgarian General Language Understanding Evaluation Benchmark
Jun 07, 2023
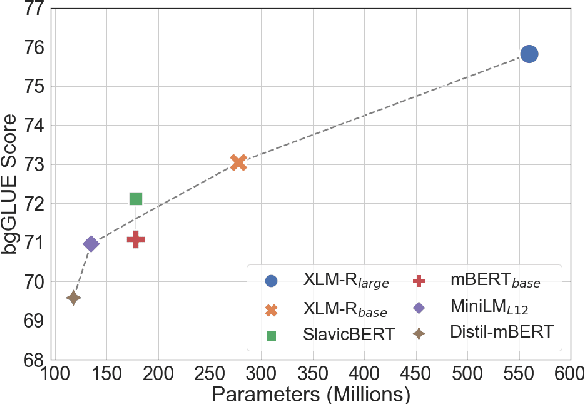

We present bgGLUE(Bulgarian General Language Understanding Evaluation), a benchmark for evaluating language models on Natural Language Understanding (NLU) tasks in Bulgarian. Our benchmark includes NLU tasks targeting a variety of NLP problems (e.g., natural language inference, fact-checking, named entity recognition, sentiment analysis, question answering, etc.) and machine learning tasks (sequence labeling, document-level classification, and regression). We run the first systematic evaluation of pre-trained language models for Bulgarian, comparing and contrasting results across the nine tasks in the benchmark. The evaluation results show strong performance on sequence labeling tasks, but there is a lot of room for improvement for tasks that require more complex reasoning. We make bgGLUE publicly available together with the fine-tuning and the evaluation code, as well as a public leaderboard at https://bgglue.github.io/, and we hope that it will enable further advancements in developing NLU models for Bulgarian.
* Accepted to ACL 2023 (Main Conference)
Filtering, Distillation, and Hard Negatives for Vision-Language Pre-Training
Jan 05, 2023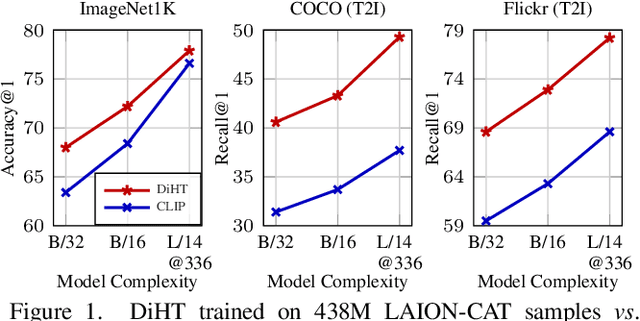
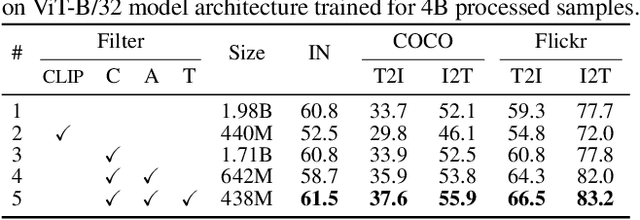
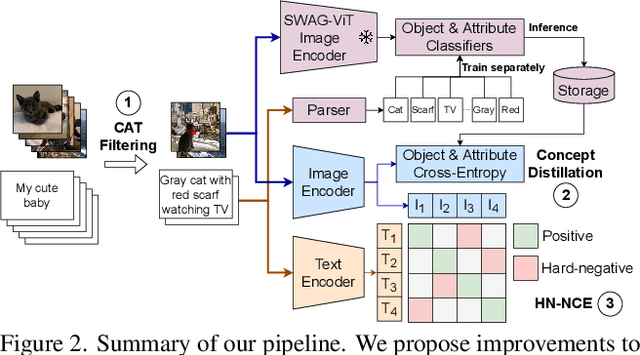
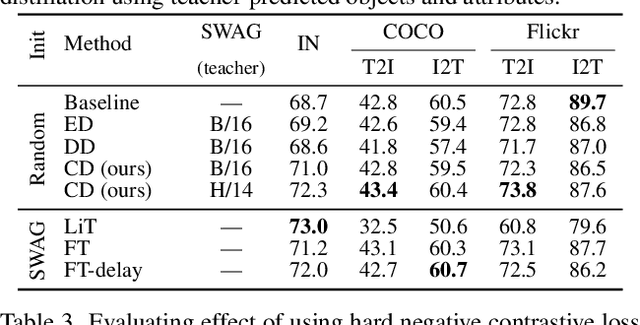
Vision-language models trained with contrastive learning on large-scale noisy data are becoming increasingly popular for zero-shot recognition problems. In this paper we improve the following three aspects of the contrastive pre-training pipeline: dataset noise, model initialization and the training objective. First, we propose a straightforward filtering strategy titled Complexity, Action, and Text-spotting (CAT) that significantly reduces dataset size, while achieving improved performance across zero-shot vision-language tasks. Next, we propose an approach titled Concept Distillation to leverage strong unimodal representations for contrastive training that does not increase training complexity while outperforming prior work. Finally, we modify the traditional contrastive alignment objective, and propose an importance-sampling approach to up-sample the importance of hard-negatives without adding additional complexity. On an extensive zero-shot benchmark of 29 tasks, our Distilled and Hard-negative Training (DiHT) approach improves on 20 tasks compared to the baseline. Furthermore, for few-shot linear probing, we propose a novel approach that bridges the gap between zero-shot and few-shot performance, substantially improving over prior work. Models are available at https://github.com/facebookresearch/diht.
OPT-IML: Scaling Language Model Instruction Meta Learning through the Lens of Generalization
Dec 28, 2022



Recent work has shown that fine-tuning large pre-trained language models on a collection of tasks described via instructions, a.k.a. instruction-tuning, improves their zero and few-shot generalization to unseen tasks. However, there is a limited understanding of the performance trade-offs of different decisions made during the instruction-tuning process. These decisions include the scale and diversity of the instruction-tuning benchmark, different task sampling strategies, fine-tuning with and without demonstrations, training using specialized datasets for reasoning and dialogue, and finally, the fine-tuning objectives themselves. In this paper, we characterize the effect of instruction-tuning decisions on downstream task performance when scaling both model and benchmark sizes. To this end, we create OPT-IML Bench: a large benchmark for Instruction Meta-Learning (IML) of 2000 NLP tasks consolidated into task categories from 8 existing benchmarks, and prepare an evaluation framework to measure three types of model generalizations: to tasks from fully held-out categories, to held-out tasks from seen categories, and to held-out instances from seen tasks. Through the lens of this framework, we first present insights about instruction-tuning decisions as applied to OPT-30B and further exploit these insights to train OPT-IML 30B and 175B, which are instruction-tuned versions of OPT. OPT-IML demonstrates all three generalization abilities at both scales on four different evaluation benchmarks with diverse tasks and input formats -- PromptSource, FLAN, Super-NaturalInstructions, and UnifiedSKG. Not only does it significantly outperform OPT on all benchmarks but is also highly competitive with existing models fine-tuned on each specific benchmark. We release OPT-IML at both scales, together with the OPT-IML Bench evaluation framework.
OPT: Open Pre-trained Transformer Language Models
May 05, 2022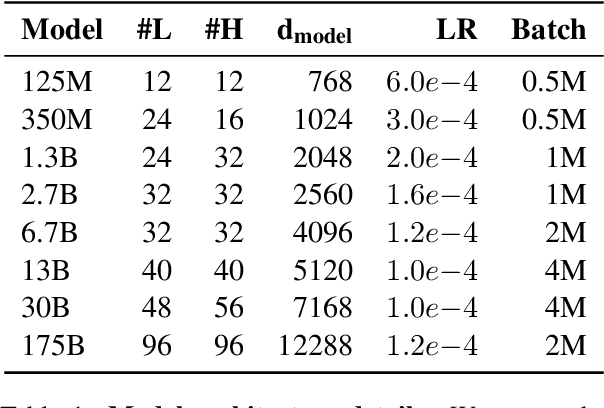
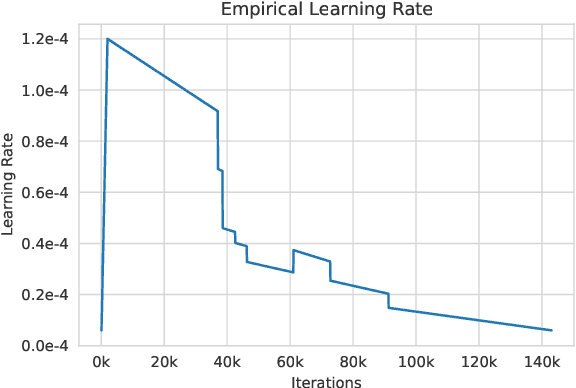
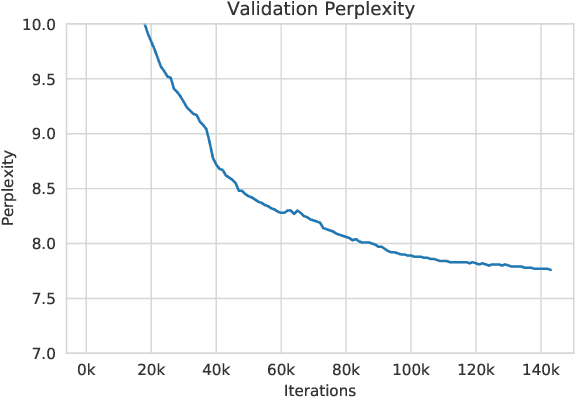
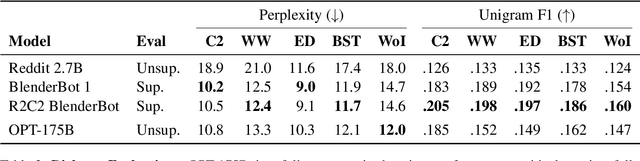
Large language models, which are often trained for hundreds of thousands of compute days, have shown remarkable capabilities for zero- and few-shot learning. Given their computational cost, these models are difficult to replicate without significant capital. For the few that are available through APIs, no access is granted to the full model weights, making them difficult to study. We present Open Pre-trained Transformers (OPT), a suite of decoder-only pre-trained transformers ranging from 125M to 175B parameters, which we aim to fully and responsibly share with interested researchers. We show that OPT-175B is comparable to GPT-3, while requiring only 1/7th the carbon footprint to develop. We are also releasing our logbook detailing the infrastructure challenges we faced, along with code for experimenting with all of the released models.