 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcedural Knowledge at Scale Improves Reasoning
Apr 01, 2026Test-time scaling has emerged as an effective way to improve language models on challenging reasoning tasks. However, most existing methods treat each problem in isolation and do not systematically reuse knowledge from prior reasoning trajectories. In particular, they underutilize procedural knowledge: how to reframe a problem, choose an approach, and verify or backtrack when needed. We introduce Reasoning Memory, a retrieval-augmented generation (RAG) framework for reasoning models that explicitly retrieves and reuses procedural knowledge at scale. Starting from existing corpora of step-by-step reasoning trajectories, we decompose each trajectory into self-contained subquestion-subroutine pairs, yielding a datastore of 32 million compact procedural knowledge entries. At inference time, a lightweight in-thought prompt lets the model verbalize the core subquestion, retrieve relevant subroutines within its reasoning trace, and reason under diverse retrieved subroutines as implicit procedural priors. Across six math, science, and coding benchmarks, Reasoning Memory consistently outperforms RAG with document, trajectory, and template knowledge, as well as a compute-matched test-time scaling baseline. With a higher inference budget, it improves over no retrieval by up to 19.2% and over the strongest compute-matched baseline by 7.9% across task types. Ablation studies show that these gains come from two key factors: the broad procedural coverage of the source trajectories and our decomposition and retrieval design, which together enable effective extraction and reuse of procedural knowledge.
FACTORY: A Challenging Human-Verified Prompt Set for Long-Form Factuality
Jul 31, 2025Long-form factuality evaluation assesses the ability of models to generate accurate, comprehensive responses to short prompts. Existing benchmarks often lack human verification, leading to potential quality issues. To address this limitation, we introduce FACTORY, a large-scale, human-verified prompt set. Developed using a model-in-the-loop approach and refined by humans, FACTORY includes challenging prompts that are fact-seeking, answerable, and unambiguous. We conduct human evaluations on 6 state-of-the-art language models using FACTORY and existing datasets. Our results show that FACTORY is a challenging benchmark: approximately 40% of the claims made in the responses of SOTA models are not factual, compared to only 10% for other datasets. Our analysis identifies the strengths of FACTORY over prior benchmarks, emphasizing its reliability and the necessity for models to reason across long-tailed facts.
Improving Factuality with Explicit Working Memory
Dec 24, 2024



Large language models can generate factually inaccurate content, a problem known as hallucination. Recent works have built upon retrieved-augmented generation to improve factuality through iterative prompting but these methods are limited by the traditional RAG design. To address these challenges, we introduce EWE (Explicit Working Memory), a novel approach that enhances factuality in long-form text generation by integrating a working memory that receives real-time feedback from external resources. The memory is refreshed based on online fact-checking and retrieval feedback, allowing EWE to rectify false claims during the generation process and ensure more accurate and reliable outputs. Our experiments demonstrate that Ewe outperforms strong baselines on four fact-seeking long-form generation datasets, increasing the factuality metric, VeriScore, by 2 to 10 points absolute without sacrificing the helpfulness of the responses. Further analysis reveals that the design of rules for memory updates, configurations of memory units, and the quality of the retrieval datastore are crucial factors for influencing model performance.
RA-DIT: Retrieval-Augmented Dual Instruction Tuning
Oct 08, 2023
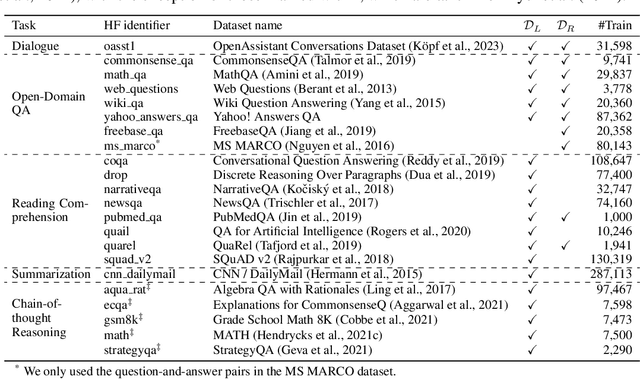
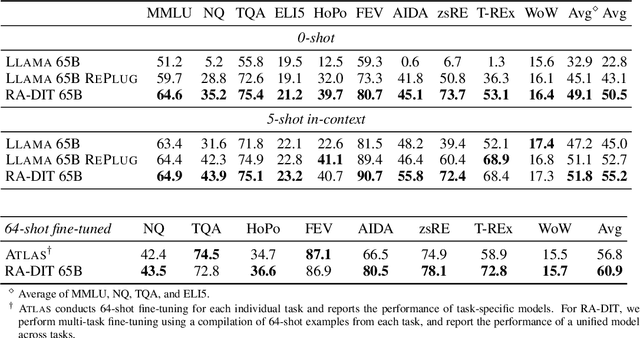
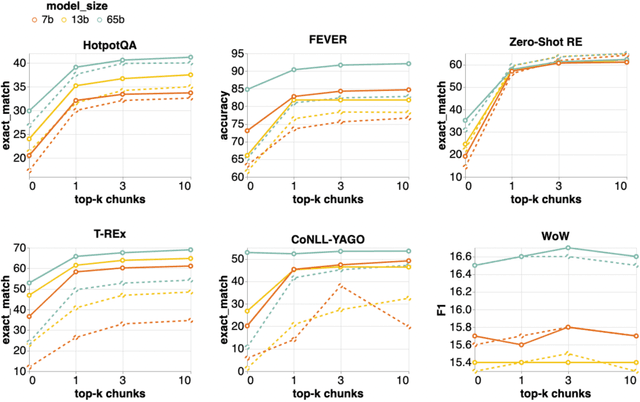
Retrieval-augmented language models (RALMs) improve performance by accessing long-tail and up-to-date knowledge from external data stores, but are challenging to build. Existing approaches require either expensive retrieval-specific modifications to LM pre-training or use post-hoc integration of the data store that leads to suboptimal performance. We introduce Retrieval-Augmented Dual Instruction Tuning (RA-DIT), a lightweight fine-tuning methodology that provides a third option by retrofitting any LLM with retrieval capabilities. Our approach operates in two distinct fine-tuning steps: (1) one updates a pre-trained LM to better use retrieved information, while (2) the other updates the retriever to return more relevant results, as preferred by the LM. By fine-tuning over tasks that require both knowledge utilization and contextual awareness, we demonstrate that each stage yields significant performance improvements, and using both leads to additional gains. Our best model, RA-DIT 65B, achieves state-of-the-art performance across a range of knowledge-intensive zero- and few-shot learning benchmarks, significantly outperforming existing in-context RALM approaches by up to +8.9% in 0-shot setting and +1.4% in 5-shot setting on average.
xSIM++: An Improved Proxy to Bitext Mining Performance for Low-Resource Languages
Jun 22, 2023
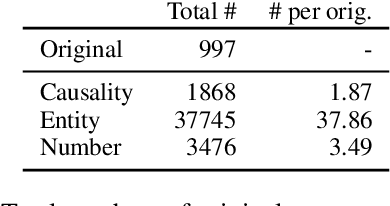

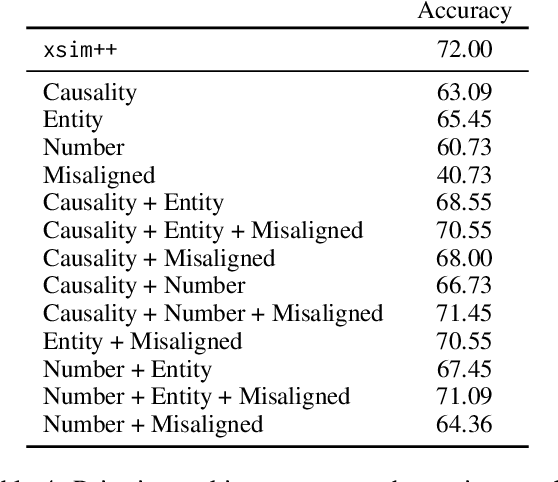
We introduce a new proxy score for evaluating bitext mining based on similarity in a multilingual embedding space: xSIM++. In comparison to xSIM, this improved proxy leverages rule-based approaches to extend English sentences in any evaluation set with synthetic, hard-to-distinguish examples which more closely mirror the scenarios we encounter during large-scale mining. We validate this proxy by running a significant number of bitext mining experiments for a set of low-resource languages, and subsequently train NMT systems on the mined data. In comparison to xSIM, we show that xSIM++ is better correlated with the downstream BLEU scores of translation systems trained on mined bitexts, providing a reliable proxy of bitext mining performance without needing to run expensive bitext mining pipelines. xSIM++ also reports performance for different error types, offering more fine-grained feedback for model development.
Efficient Open Domain Multi-Hop Question Answering with Few-Shot Data Synthesis
May 23, 2023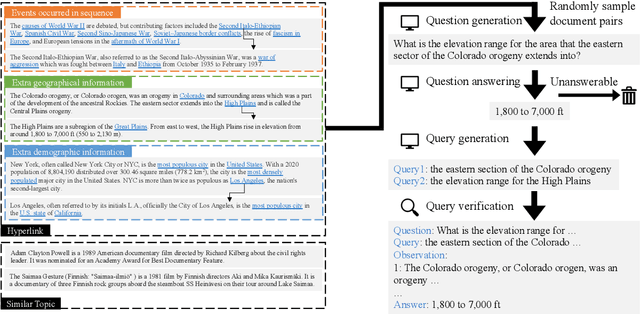
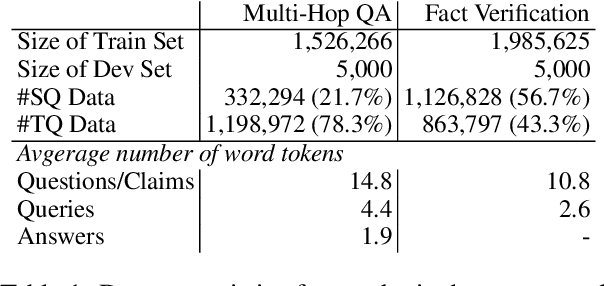

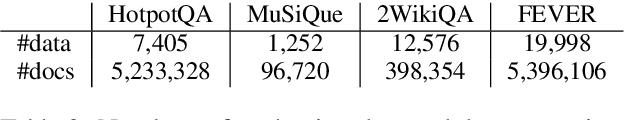
Few-shot learning for open domain multi-hop question answering typically relies on large language models (LLMs). While powerful, LLMs are inefficient at the inference time. We propose a data synthesis framework for multi-hop question answering that allows for improving smaller language models with less than 10 human-annotated question answer pairs. The framework is built upon the data generation functions parameterized by LLMs and prompts, which requires minimal hand-crafted features. Empirically, we synthesize millions of multi-hop questions and claims. After finetuning language models on the synthetic data, we evaluate the models on popular benchmarks on multi-hop question answering and fact verification. Our experimental results show that finetuning on the synthetic data improves model performance significantly, allowing our finetuned models to be competitive with prior models while being almost one-third the size in terms of parameter counts.
BLASER: A Text-Free Speech-to-Speech Translation Evaluation Metric
Dec 16, 2022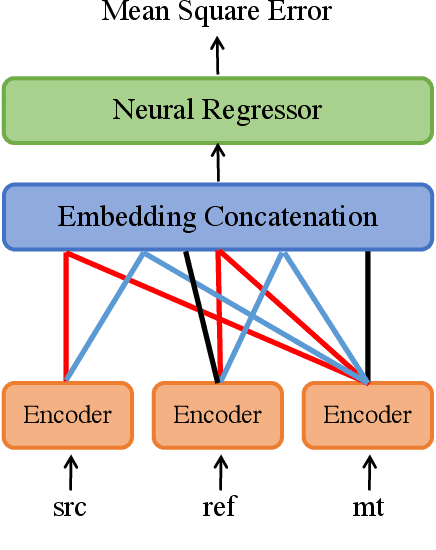
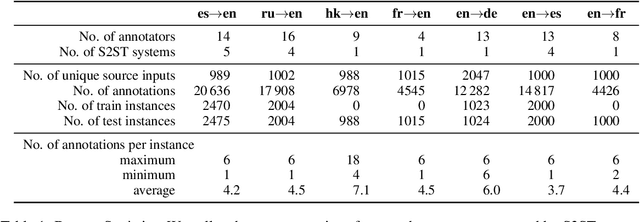
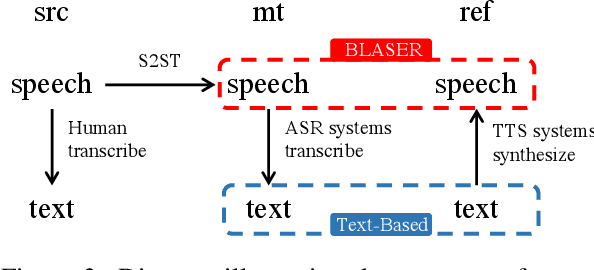

End-to-End speech-to-speech translation (S2ST) is generally evaluated with text-based metrics. This means that generated speech has to be automatically transcribed, making the evaluation dependent on the availability and quality of automatic speech recognition (ASR) systems. In this paper, we propose a text-free evaluation metric for end-to-end S2ST, named BLASER, to avoid the dependency on ASR systems. BLASER leverages a multilingual multimodal encoder to directly encode the speech segments for source input, translation output and reference into a shared embedding space and computes a score of the translation quality that can be used as a proxy to human evaluation. To evaluate our approach, we construct training and evaluation sets from more than 40k human annotations covering seven language directions. The best results of BLASER are achieved by training with supervision from human rating scores. We show that when evaluated at the sentence level, BLASER correlates significantly better with human judgment compared to ASR-dependent metrics including ASR-SENTBLEU in all translation directions and ASR-COMET in five of them. Our analysis shows combining speech and text as inputs to BLASER does not increase the correlation with human scores, but best correlations are achieved when using speech, which motivates the goal of our research. Moreover, we show that using ASR for references is detrimental for text-based metrics.
Leveraging Natural Supervision for Language Representation Learning and Generation
Jul 21, 2022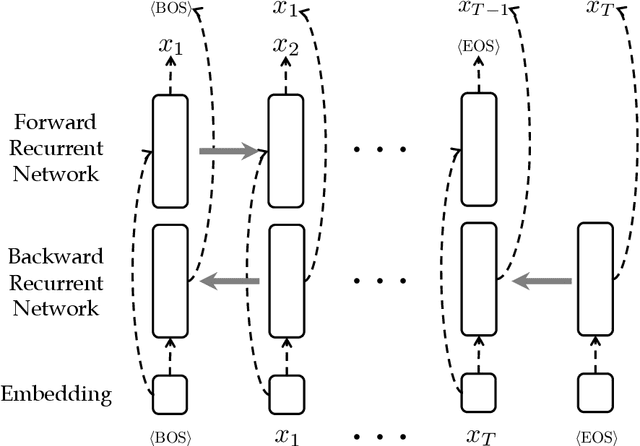
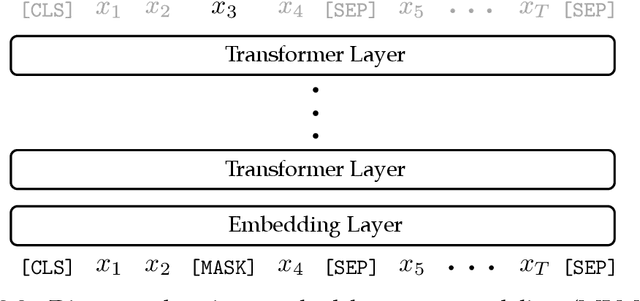
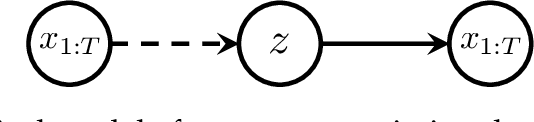
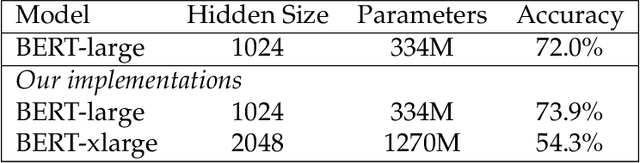
Recent breakthroughs in Natural Language Processing (NLP) have been driven by language models trained on a massive amount of plain text. While powerful, deriving supervision from textual resources is still an open question. For example, language model pretraining often neglects the rich, freely-available structures in textual data. In this thesis, we describe three lines of work that seek to improve the training and evaluation of neural models using naturally-occurring supervision. We first investigate self-supervised training losses to help enhance the performance of pretrained language models for various NLP tasks. Specifically, we alter the sentence prediction loss to make it better suited to other pretraining losses and more challenging to solve. We design an intermediate finetuning step that uses self-supervised training to promote models' ability in cross-task generalization. Then we describe methods to leverage the structures in Wikipedia and paraphrases. In particular, we propose training losses to exploit hyperlinks, article structures, and article category graphs for entity-, discourse-, entailment-related knowledge. We propose a framework that uses paraphrase pairs to disentangle semantics and syntax in sentence representations. We extend the framework for a novel generation task that controls the syntax of output text with a sentential exemplar. Lastly, we discuss our work on tailoring textual resources for establishing challenging evaluation tasks. We introduce three datasets by defining novel tasks using various fan-contributed websites, including a long-form data-to-text generation dataset, a screenplay summarization dataset, and a long-form story generation dataset. These datasets have unique characteristics offering challenges to future work in their respective task settings.
Improving In-Context Few-Shot Learning via Self-Supervised Training
May 03, 2022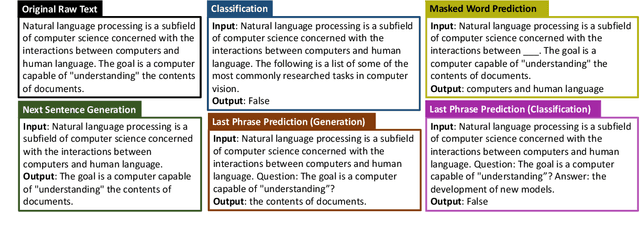

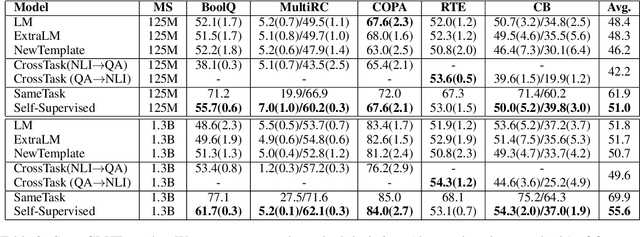

Self-supervised pretraining has made few-shot learning possible for many NLP tasks. But the pretraining objectives are not typically adapted specifically for in-context few-shot learning. In this paper, we propose to use self-supervision in an intermediate training stage between pretraining and downstream few-shot usage with the goal to teach the model to perform in-context few shot learning. We propose and evaluate four self-supervised objectives on two benchmarks. We find that the intermediate self-supervision stage produces models that outperform strong baselines. Ablation study shows that several factors affect the downstream performance, such as the amount of training data and the diversity of the self-supervised objectives. Human-annotated cross-task supervision and self-supervision are complementary. Qualitative analysis suggests that the self-supervised-trained models are better at following task requirements.
TVRecap: A Dataset for Generating Stories with Character Descriptions
Sep 18, 2021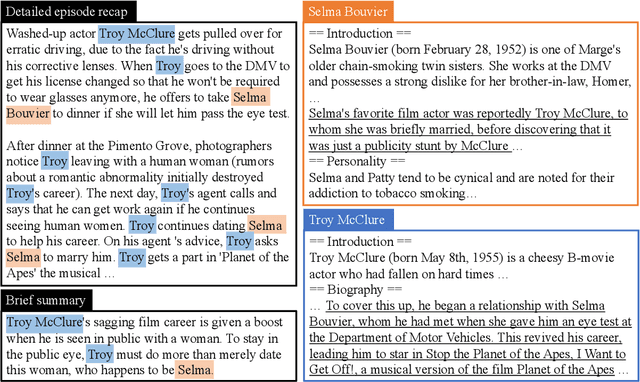
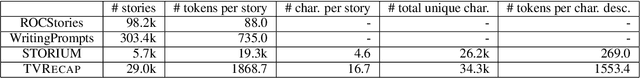

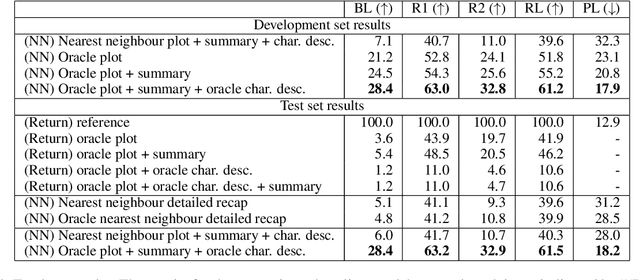
We introduce TVRecap, a story generation dataset that requires generating detailed TV show episode recaps from a brief summary and a set of documents describing the characters involved. Unlike other story generation datasets, TVRecap contains stories that are authored by professional screenwriters and that feature complex interactions among multiple characters. Generating stories in TVRecap requires drawing relevant information from the lengthy provided documents about characters based on the brief summary. In addition, by swapping the input and output, TVRecap can serve as a challenging testbed for abstractive summarization. We create TVRecap from fan-contributed websites, which allows us to collect 26k episode recaps with 1868.7 tokens on average. Empirically, we take a hierarchical story generation approach and find that the neural model that uses oracle content selectors for character descriptions demonstrates the best performance on automatic metrics, showing the potential of our dataset to inspire future research on story generation with constraints. Qualitative analysis shows that the best-performing model sometimes generates content that is unfaithful to the short summaries, suggesting promising directions for future work.