 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCRIBES: Web-Scale Script-Based Semi-Structured Data Extraction with Reinforcement Learning
Oct 02, 2025
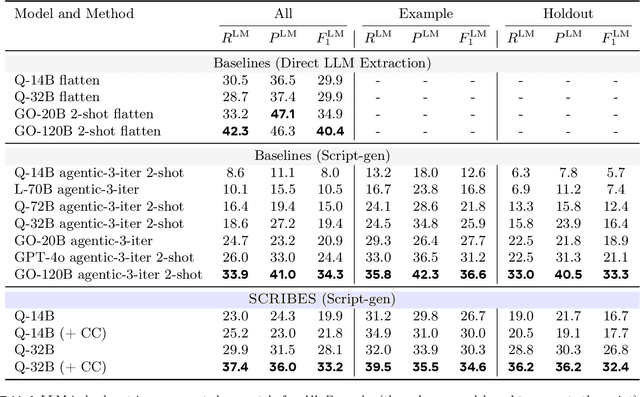


Semi-structured content in HTML tables, lists, and infoboxes accounts for a substantial share of factual data on the web, yet the formatting complicates usage, and reliably extracting structured information from them remains challenging. Existing methods either lack generalization or are resource-intensive due to per-page LLM inference. In this paper, we introduce SCRIBES (SCRIpt-Based Semi-Structured Content Extraction at Web-Scale), a novel reinforcement learning framework that leverages layout similarity across webpages within the same site as a reward signal. Instead of processing each page individually, SCRIBES generates reusable extraction scripts that can be applied to groups of structurally similar webpages. Our approach further improves by iteratively training on synthetic annotations from in-the-wild CommonCrawl data. Experiments show that our approach outperforms strong baselines by over 13% in script quality and boosts downstream question answering accuracy by more than 4% for GPT-4o, enabling scalable and resource-efficient web information extraction.
Learning to Reason for Factuality
Aug 07, 2025Reasoning Large Language Models (R-LLMs) have significantly advanced complex reasoning tasks but often struggle with factuality, generating substantially more hallucinations than their non-reasoning counterparts on long-form factuality benchmarks. However, extending online Reinforcement Learning (RL), a key component in recent R-LLM advancements, to the long-form factuality setting poses several unique challenges due to the lack of reliable verification methods. Previous work has utilized automatic factuality evaluation frameworks such as FActScore to curate preference data in the offline RL setting, yet we find that directly leveraging such methods as the reward in online RL leads to reward hacking in multiple ways, such as producing less detailed or relevant responses. We propose a novel reward function that simultaneously considers the factual precision, response detail level, and answer relevance, and applies online RL to learn high quality factual reasoning. Evaluated on six long-form factuality benchmarks, our factual reasoning model achieves an average reduction of 23.1 percentage points in hallucination rate, a 23% increase in answer detail level, and no degradation in the overall response helpfulness.
FACTORY: A Challenging Human-Verified Prompt Set for Long-Form Factuality
Jul 31, 2025Long-form factuality evaluation assesses the ability of models to generate accurate, comprehensive responses to short prompts. Existing benchmarks often lack human verification, leading to potential quality issues. To address this limitation, we introduce FACTORY, a large-scale, human-verified prompt set. Developed using a model-in-the-loop approach and refined by humans, FACTORY includes challenging prompts that are fact-seeking, answerable, and unambiguous. We conduct human evaluations on 6 state-of-the-art language models using FACTORY and existing datasets. Our results show that FACTORY is a challenging benchmark: approximately 40% of the claims made in the responses of SOTA models are not factual, compared to only 10% for other datasets. Our analysis identifies the strengths of FACTORY over prior benchmarks, emphasizing its reliability and the necessity for models to reason across long-tailed facts.
Conversational Intent-Driven GraphRAG: Enhancing Multi-Turn Dialogue Systems through Adaptive Dual-Retrieval of Flow Patterns and Context Semantics
Jun 24, 2025We present CID-GraphRAG (Conversational Intent-Driven Graph Retrieval Augmented Generation), a novel framework that addresses the limitations of existing dialogue systems in maintaining both contextual coherence and goal-oriented progression in multi-turn customer service conversations. Unlike traditional RAG systems that rely solely on semantic similarity (Conversation RAG) or standard knowledge graphs (GraphRAG), CID-GraphRAG constructs dynamic intent transition graphs from goal achieved historical dialogues and implements a dual-retrieval mechanism that adaptively balances intent-based graph traversal with semantic search. This approach enables the system to simultaneously leverage both conversional intent flow patterns and contextual semantics, significantly improving retrieval quality and response quality. In extensive experiments on real-world customer service dialogues, we employ both automatic metrics and LLM-as-judge assessments, demonstrating that CID-GraphRAG significantly outperforms both semantic-based Conversation RAG and intent-based GraphRAG baselines across all evaluation criteria. Quantitatively, CID-GraphRAG demonstrates substantial improvements over Conversation RAG across automatic metrics, with relative gains of 11% in BLEU, 5% in ROUGE-L, 6% in METEOR, and most notably, a 58% improvement in response quality according to LLM-as-judge evaluations. These results demonstrate that the integration of intent transition structures with semantic retrieval creates a synergistic effect that neither approach achieves independently, establishing CID-GraphRAG as an effective framework for addressing the challenges of maintaining contextual coherence and goal-oriented progression in knowledge-intensive multi-turn dialogues.
DRAMA: Diverse Augmentation from Large Language Models to Smaller Dense Retrievers
Feb 25, 2025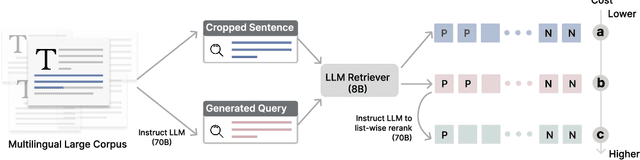
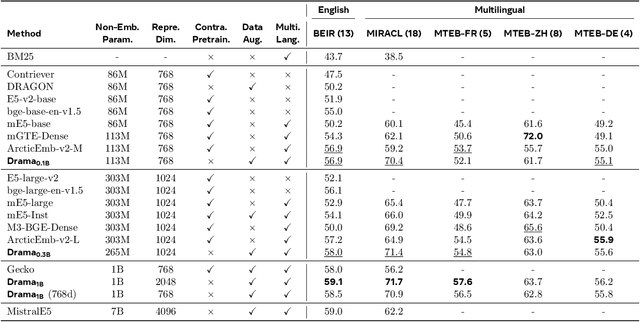
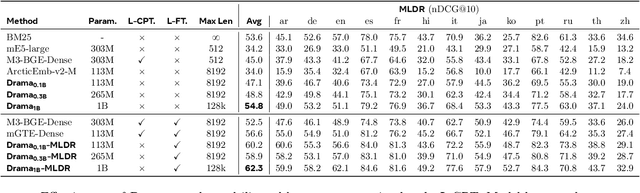
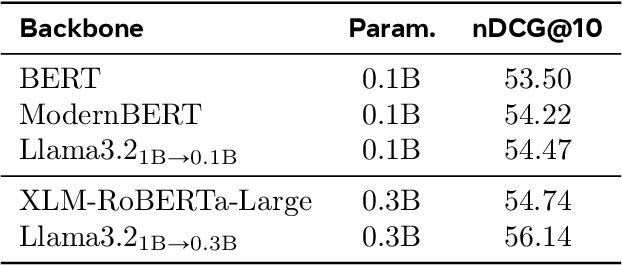
Large language models (LLMs) have demonstrated strong effectiveness and robustness while fine-tuned as dense retrievers. However, their large parameter size brings significant inference time computational challenges, including high encoding costs for large-scale corpora and increased query latency, limiting their practical deployment. While smaller retrievers offer better efficiency, they often fail to generalize effectively with limited supervised fine-tuning data. In this work, we introduce DRAMA, a training framework that leverages LLMs to train smaller generalizable dense retrievers. In particular, we adopt pruned LLMs as the backbone and train on diverse LLM-augmented data in a single-stage contrastive learning setup. Experiments show that DRAMA offers better multilingual and long-context capabilities than traditional encoder-based retrievers, and achieves strong performance across multiple tasks and languages. These highlight the potential of connecting the training of smaller retrievers with the growing advancements in LLMs, bridging the gap between efficiency and generalization.
Extracting and Understanding the Superficial Knowledge in Alignment
Feb 07, 2025



Alignment of large language models (LLMs) with human values and preferences, often achieved through fine-tuning based on human feedback, is essential for ensuring safe and responsible AI behaviors. However, the process typically requires substantial data and computation resources. Recent studies have revealed that alignment might be attainable at lower costs through simpler methods, such as in-context learning. This leads to the question: Is alignment predominantly superficial? In this paper, we delve into this question and provide a quantitative analysis. We formalize the concept of superficial knowledge, defining it as knowledge that can be acquired through easily token restyling, without affecting the model's ability to capture underlying causal relationships between tokens. We propose a method to extract and isolate superficial knowledge from aligned models, focusing on the shallow modifications to the final token selection process. By comparing models augmented only with superficial knowledge to fully aligned models, we quantify the superficial portion of alignment. Our findings reveal that while superficial knowledge constitutes a significant portion of alignment, particularly in safety and detoxification tasks, it is not the whole story. Tasks requiring reasoning and contextual understanding still rely on deeper knowledge. Additionally, we demonstrate two practical advantages of isolated superficial knowledge: (1) it can be transferred between models, enabling efficient offsite alignment of larger models using extracted superficial knowledge from smaller models, and (2) it is recoverable, allowing for the restoration of alignment in compromised models without sacrificing performance.
Nearest Neighbor Speculative Decoding for LLM Generation and Attribution
May 29, 2024



Large language models (LLMs) often hallucinate and lack the ability to provide attribution for their generations. Semi-parametric LMs, such as kNN-LM, approach these limitations by refining the output of an LM for a given prompt using its nearest neighbor matches in a non-parametric data store. However, these models often exhibit slow inference speeds and produce non-fluent texts. In this paper, we introduce Nearest Neighbor Speculative Decoding (NEST), a novel semi-parametric language modeling approach that is capable of incorporating real-world text spans of arbitrary length into the LM generations and providing attribution to their sources. NEST performs token-level retrieval at each inference step to compute a semi-parametric mixture distribution and identify promising span continuations in a corpus. It then uses an approximate speculative decoding procedure that accepts a prefix of the retrieved span or generates a new token. NEST significantly enhances the generation quality and attribution rate of the base LM across a variety of knowledge-intensive tasks, surpassing the conventional kNN-LM method and performing competitively with in-context retrieval augmentation. In addition, NEST substantially improves the generation speed, achieving a 1.8x speedup in inference time when applied to Llama-2-Chat 70B.
An Introduction to Vision-Language Modeling
May 27, 2024


Following the recent popularity of Large Language Models (LLMs), several attempts have been made to extend them to the visual domain. From having a visual assistant that could guide us through unfamiliar environments to generative models that produce images using only a high-level text description, the vision-language model (VLM) applications will significantly impact our relationship with technology. However, there are many challenges that need to be addressed to improve the reliability of those models. While language is discrete, vision evolves in a much higher dimensional space in which concepts cannot always be easily discretized. To better understand the mechanics behind mapping vision to language, we present this introduction to VLMs which we hope will help anyone who would like to enter the field. First, we introduce what VLMs are, how they work, and how to train them. Then, we present and discuss approaches to evaluate VLMs. Although this work primarily focuses on mapping images to language, we also discuss extending VLMs to videos.
FLAME: Factuality-Aware Alignment for Large Language Models
May 02, 2024



Alignment is a standard procedure to fine-tune pre-trained large language models (LLMs) to follow natural language instructions and serve as helpful AI assistants. We have observed, however, that the conventional alignment process fails to enhance the factual accuracy of LLMs, and often leads to the generation of more false facts (i.e. hallucination). In this paper, we study how to make the LLM alignment process more factual, by first identifying factors that lead to hallucination in both alignment steps:\ supervised fine-tuning (SFT) and reinforcement learning (RL). In particular, we find that training the LLM on new knowledge or unfamiliar texts can encourage hallucination. This makes SFT less factual as it trains on human labeled data that may be novel to the LLM. Furthermore, reward functions used in standard RL can also encourage hallucination, because it guides the LLM to provide more helpful responses on a diverse set of instructions, often preferring longer and more detailed responses. Based on these observations, we propose factuality-aware alignment, comprised of factuality-aware SFT and factuality-aware RL through direct preference optimization. Experiments show that our proposed factuality-aware alignment guides LLMs to output more factual responses while maintaining instruction-following capability.
Towards Safety and Helpfulness Balanced Responses via Controllable Large Language Models
Apr 01, 2024



As large language models (LLMs) become easily accessible nowadays, the trade-off between safety and helpfulness can significantly impact user experience. A model that prioritizes safety will cause users to feel less engaged and assisted while prioritizing helpfulness will potentially cause harm. Possible harms include teaching people how to build a bomb, exposing youth to inappropriate content, and hurting users' mental health. In this work, we propose to balance safety and helpfulness in diverse use cases by controlling both attributes in LLM. We explore training-free and fine-tuning methods that do not require extra human annotations and analyze the challenges of controlling safety and helpfulness in LLMs. Our experiments demonstrate that our method can rewind a learned model and unlock its controllability.