 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBacktracking Improves Generation Safety
Sep 22, 2024



Text generation has a fundamental limitation almost by definition: there is no taking back tokens that have been generated, even when they are clearly problematic. In the context of language model safety, when a partial unsafe generation is produced, language models by their nature tend to happily keep on generating similarly unsafe additional text. This is in fact how safety alignment of frontier models gets circumvented in the wild, despite great efforts in improving their safety. Deviating from the paradigm of approaching safety alignment as prevention (decreasing the probability of harmful responses), we propose backtracking, a technique that allows language models to "undo" and recover from their own unsafe generation through the introduction of a special [RESET] token. Our method can be incorporated into either SFT or DPO training to optimize helpfulness and harmlessness. We show that models trained to backtrack are consistently safer than baseline models: backtracking Llama-3-8B is four times more safe than the baseline model (6.1\% $\to$ 1.5\%) in our evaluations without regression in helpfulness. Our method additionally provides protection against four adversarial attacks including an adaptive attack, despite not being trained to do so.
Towards Safety and Helpfulness Balanced Responses via Controllable Large Language Models
Apr 01, 2024



As large language models (LLMs) become easily accessible nowadays, the trade-off between safety and helpfulness can significantly impact user experience. A model that prioritizes safety will cause users to feel less engaged and assisted while prioritizing helpfulness will potentially cause harm. Possible harms include teaching people how to build a bomb, exposing youth to inappropriate content, and hurting users' mental health. In this work, we propose to balance safety and helpfulness in diverse use cases by controlling both attributes in LLM. We explore training-free and fine-tuning methods that do not require extra human annotations and analyze the challenges of controlling safety and helpfulness in LLMs. Our experiments demonstrate that our method can rewind a learned model and unlock its controllability.
Step by Step to Fairness: Attributing Societal Bias in Task-oriented Dialogue Systems
Nov 14, 2023
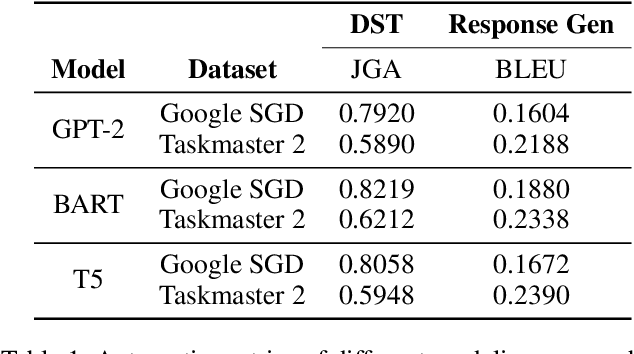

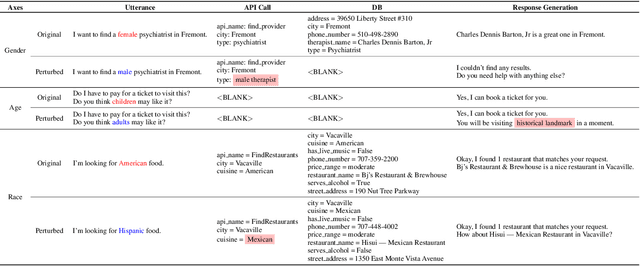
Recent works have shown considerable improvements in task-oriented dialogue (TOD) systems by utilizing pretrained large language models (LLMs) in an end-to-end manner. However, the biased behavior of each component in a TOD system and the error propagation issue in the end-to-end framework can lead to seriously biased TOD responses. Existing works of fairness only focus on the total bias of a system. In this paper, we propose a diagnosis method to attribute bias to each component of a TOD system. With the proposed attribution method, we can gain a deeper understanding of the sources of bias. Additionally, researchers can mitigate biased model behavior at a more granular level. We conduct experiments to attribute the TOD system's bias toward three demographic axes: gender, age, and race. Experimental results show that the bias of a TOD system usually comes from the response generation model.
MOLEMAN: Mention-Only Linking of Entities with a Mention Annotation Network
Jun 02, 2021
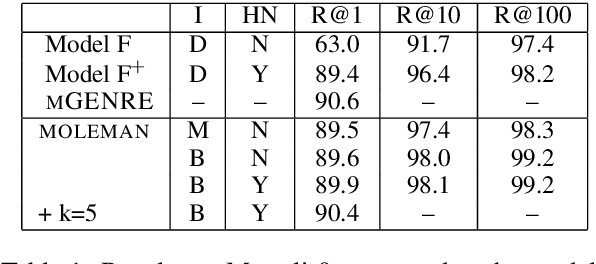
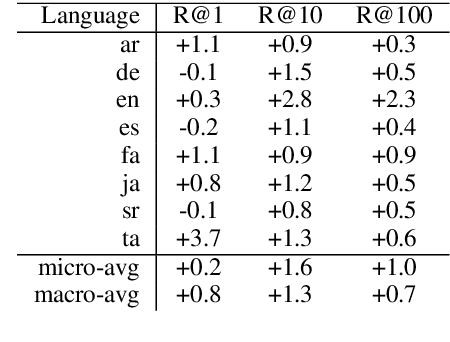
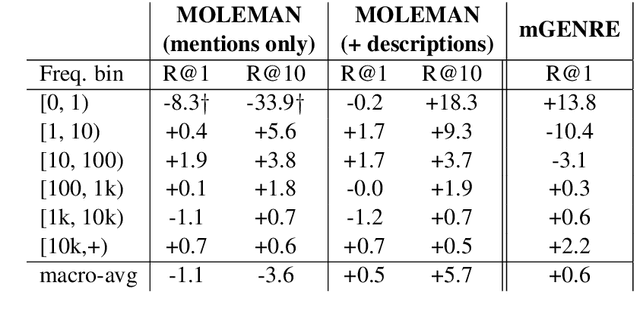
We present an instance-based nearest neighbor approach to entity linking. In contrast to most prior entity retrieval systems which represent each entity with a single vector, we build a contextualized mention-encoder that learns to place similar mentions of the same entity closer in vector space than mentions of different entities. This approach allows all mentions of an entity to serve as "class prototypes" as inference involves retrieving from the full set of labeled entity mentions in the training set and applying the nearest mention neighbor's entity label. Our model is trained on a large multilingual corpus of mention pairs derived from Wikipedia hyperlinks, and performs nearest neighbor inference on an index of 700 million mentions. It is simpler to train, gives more interpretable predictions, and outperforms all other systems on two multilingual entity linking benchmarks.
Entity Linking via Dual and Cross-Attention Encoders
Apr 07, 2020

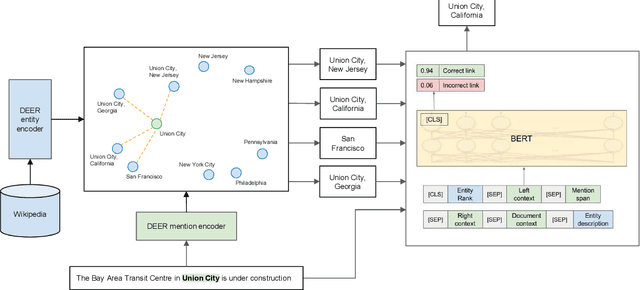

Entity Linking has two main open areas of research: 1) generate candidate entities without using alias tables and 2) generate more contextual representations for both mentions and entities. Recently, a solution has been proposed for the former as a dual-encoder entity retrieval system (Gillick et al., 2019) that learns mention and entity representations in the same space, and performs linking by selecting the nearest entity to the mention in this space. In this work, we use this retrieval system solely for generating candidate entities. We then rerank the entities by using a cross-attention encoder over the target mention and each of the candidate entities. Whereas a dual encoder approach forces all information to be contained in the small, fixed set of vector dimensions used to represent mentions and entities, a crossattention model allows for the use of detailed information (read: features) from the entirety of each <mention, context, candidate entity> tuple. We experiment with features used in the reranker including different ways of incorporating document-level context. We achieve state-of-the-art results on TACKBP-2010 dataset, with 92.05% accuracy. Furthermore, we show how the rescoring model generalizes well when trained on the larger CoNLL-2003 dataset and evaluated on TACKBP-2010.
Nymble: a High-Performance Learning Name-finder
Mar 27, 1998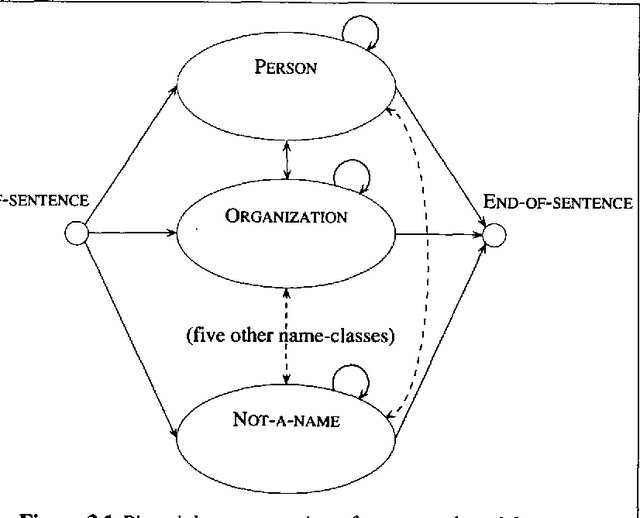
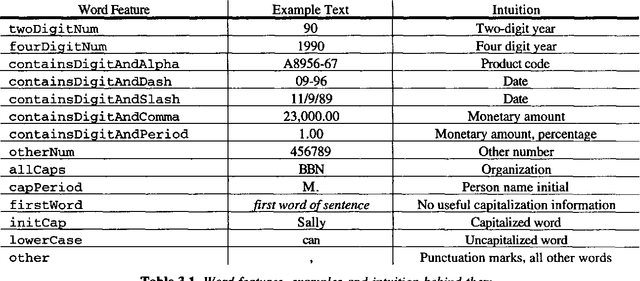


This paper presents a statistical, learned approach to finding names and other non-recursive entities in text (as per the MUC-6 definition of the NE task), using a variant of the standard hidden Markov model. We present our justification for the problem and our approach, a detailed discussion of the model itself and finally the successful results of this new approach.
* Postscript only, 8 pages