 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALICE: A Multifaceted Evaluation Framework of Large Audio-Language Models' In-Context Learning Ability
Mar 20, 2026While Large Audio-Language Models (LALMs) have been shown to exhibit degraded instruction-following capabilities, their ability to infer task patterns from in-context examples under audio conditioning remains unstudied. To address this gap, we present ALICE, a three-stage framework that progressively reduces textual guidance to systematically evaluate LALMs' in-context learning ability under audio conditioning. Evaluating six LALMs across four audio understanding tasks under two output constraint categories, we uncover a consistent asymmetry across all stages and LALMs: in-context demonstrations reliably improve format compliance but fail to improve, and often degrade, the core task performance. This suggests that LALMs can glean surface-level formatting patterns from demonstrations but may struggle to leverage cross-modal semantic grounding to reliably infer task objectives from audio-conditioned examples, highlighting potential limitations in current cross-modal integration.
Latent-Mark: An Audio Watermark Robust to Neural Resynthesis
Mar 05, 2026While existing audio watermarking techniques have achieved strong robustness against traditional digital signal processing (DSP) attacks, they remain vulnerable to neural resynthesis. This occurs because modern neural audio codecs act as semantic filters and discard the imperceptible waveform variations used in prior watermarking methods. To address this limitation, we propose Latent-Mark, the first zero-bit audio watermarking framework designed to survive semantic compression. Our key insight is that robustness to the encode-decode process requires embedding the watermark within the codec's invariant latent space. We achieve this by optimizing the audio waveform to induce a detectable directional shift in its encoded latent representation, while constraining perturbations to align with the natural audio manifold to ensure imperceptibility. To prevent overfitting to a single codec's quantization rules, we introduce Cross-Codec Optimization, jointly optimizing the waveform across multiple surrogate codecs to target shared latent invariants. Extensive evaluations demonstrate robust zero-shot transferability to unseen neural codecs, achieving state-of-the-art resilience against traditional DSP attacks while preserving perceptual imperceptibility. Our work inspires future research into universal watermarking frameworks capable of maintaining integrity across increasingly complex and diverse generative distortions.
Expanding the Role of Diffusion Models for Robust Classifier Training
Feb 23, 2026Incorporating diffusion-generated synthetic data into adversarial training (AT) has been shown to substantially improve the training of robust image classifiers. In this work, we extend the role of diffusion models beyond merely generating synthetic data, examining whether their internal representations, which encode meaningful features of the data, can provide additional benefits for robust classifier training. Through systematic experiments, we show that diffusion models offer representations that are both diverse and partially robust, and that explicitly incorporating diffusion representations as an auxiliary learning signal during AT consistently improves robustness across settings. Furthermore, our representation analysis indicates that incorporating diffusion models into AT encourages more disentangled features, while diffusion representations and diffusion-generated synthetic data play complementary roles in shaping representations. Experiments on CIFAR-10, CIFAR-100, and ImageNet validate these findings, demonstrating the effectiveness of jointly leveraging diffusion representations and synthetic data within AT.
Pseudo2Real: Task Arithmetic for Pseudo-Label Correction in Automatic Speech Recognition
Oct 09, 2025Robust ASR under domain shift is crucial because real-world systems encounter unseen accents and domains with limited labeled data. Although pseudo-labeling offers a practical workaround, it often introduces systematic, accent-specific errors that filtering fails to fix. We ask: How can we correct these recurring biases without target ground truth? We propose a simple parameter-space correction: in a source domain containing both real and pseudo-labeled data, two ASR models are fine-tuned from the same initialization, one on ground-truth labels and the other on pseudo-labels, and their weight difference forms a correction vector that captures pseudo-label biases. When applied to a pseudo-labeled target model, this vector enhances recognition, achieving up to a 35% relative Word Error Rate (WER) reduction on AfriSpeech-200 across ten African accents with the Whisper tiny model.
Enhancing Certified Robustness via Block Reflector Orthogonal Layers and Logit Annealing Loss
May 21, 2025Lipschitz neural networks are well-known for providing certified robustness in deep learning. In this paper, we present a novel, efficient Block Reflector Orthogonal (BRO) layer that enhances the capability of orthogonal layers on constructing more expressive Lipschitz neural architectures. In addition, by theoretically analyzing the nature of Lipschitz neural networks, we introduce a new loss function that employs an annealing mechanism to increase margin for most data points. This enables Lipschitz models to provide better certified robustness. By employing our BRO layer and loss function, we design BRONet - a simple yet effective Lipschitz neural network that achieves state-of-the-art certified robustness. Extensive experiments and empirical analysis on CIFAR-10/100, Tiny-ImageNet, and ImageNet validate that our method outperforms existing baselines. The implementation is available at \href{https://github.com/ntuaislab/BRONet}{https://github.com/ntuaislab/BRONet}.
Adaptive Helpfulness-Harmlessness Alignment with Preference Vectors
Apr 27, 2025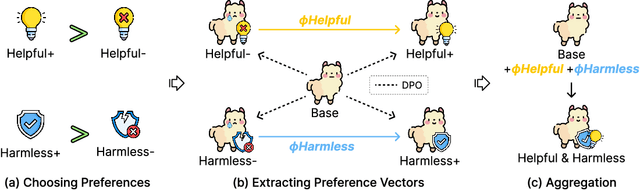
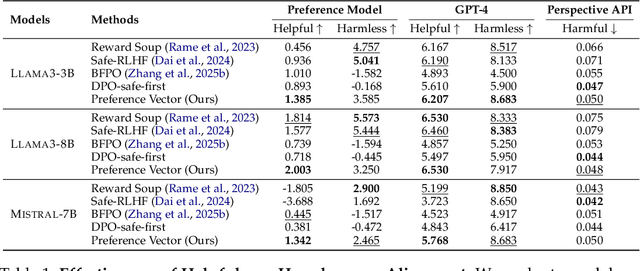
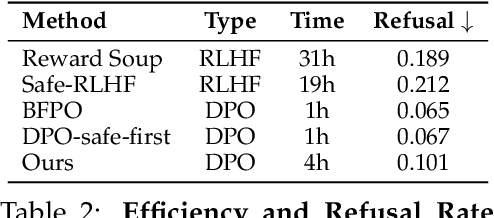
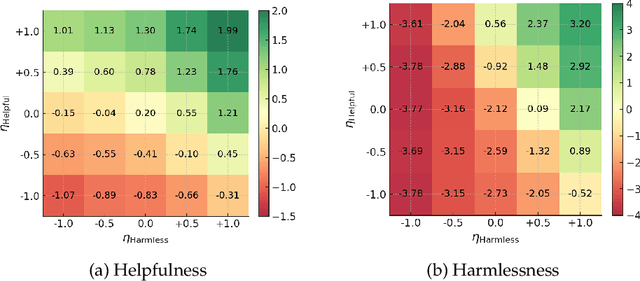
Ensuring that large language models (LLMs) are both helpful and harmless is a critical challenge, as overly strict constraints can lead to excessive refusals, while permissive models risk generating harmful content. Existing approaches, such as reinforcement learning from human feedback (RLHF) and direct preference optimization (DPO), attempt to balance these trade-offs but suffer from performance conflicts, limited controllability, and poor extendability. To address these issues, we propose Preference Vector, a novel framework inspired by task arithmetic. Instead of optimizing multiple preferences within a single objective, we train separate models on individual preferences, extract behavior shifts as preference vectors, and dynamically merge them at test time. This modular approach enables fine-grained, user-controllable preference adjustments and facilitates seamless integration of new preferences without retraining. Experiments show that our proposed Preference Vector framework improves helpfulness without excessive conservatism, allows smooth control over preference trade-offs, and supports scalable multi-preference alignment.
Jailbreaking with Universal Multi-Prompts
Feb 03, 2025Large language models (LLMs) have seen rapid development in recent years, revolutionizing various applications and significantly enhancing convenience and productivity. However, alongside their impressive capabilities, ethical concerns and new types of attacks, such as jailbreaking, have emerged. While most prompting techniques focus on optimizing adversarial inputs for individual cases, resulting in higher computational costs when dealing with large datasets. Less research has addressed the more general setting of training a universal attacker that can transfer to unseen tasks. In this paper, we introduce JUMP, a prompt-based method designed to jailbreak LLMs using universal multi-prompts. We also adapt our approach for defense, which we term DUMP. Experimental results demonstrate that our method for optimizing universal multi-prompts outperforms existing techniques.
Safeguard Fine-Tuned LLMs Through Pre- and Post-Tuning Model Merging
Dec 27, 2024



Fine-tuning large language models (LLMs) for downstream tasks is a widely adopted approach, but it often leads to safety degradation in safety-aligned LLMs. Currently, many solutions address this issue by incorporating additional safety data, which can be impractical in many cases. In this paper, we address the question: How can we improve downstream task performance while preserving safety in LLMs without relying on additional safety data? We propose a simple and effective method that maintains the inherent safety of LLMs while enhancing their downstream task performance: merging the weights of pre- and post-fine-tuned safety-aligned models. Experimental results across various downstream tasks, models, and merging methods demonstrate that this approach effectively mitigates safety degradation while improving downstream task performance, offering a practical solution for adapting safety-aligned LLMs.
Trap-MID: Trapdoor-based Defense against Model Inversion Attacks
Nov 13, 2024Model Inversion (MI) attacks pose a significant threat to the privacy of Deep Neural Networks by recovering training data distribution from well-trained models. While existing defenses often rely on regularization techniques to reduce information leakage, they remain vulnerable to recent attacks. In this paper, we propose the Trapdoor-based Model Inversion Defense (Trap-MID) to mislead MI attacks. A trapdoor is integrated into the model to predict a specific label when the input is injected with the corresponding trigger. Consequently, this trapdoor information serves as the "shortcut" for MI attacks, leading them to extract trapdoor triggers rather than private data. We provide theoretical insights into the impacts of trapdoor's effectiveness and naturalness on deceiving MI attacks. In addition, empirical experiments demonstrate the state-of-the-art defense performance of Trap-MID against various MI attacks without the requirements for extra data or large computational overhead. Our source code is publicly available at https://github.com/ntuaislab/Trap-MID.
Adversarial Robustness Overestimation and Instability in TRADES
Oct 10, 2024



This paper examines the phenomenon of probabilistic robustness overestimation in TRADES, a prominent adversarial training method. Our study reveals that TRADES sometimes yields disproportionately high PGD validation accuracy compared to the AutoAttack testing accuracy in the multiclass classification task. This discrepancy highlights a significant overestimation of robustness for these instances, potentially linked to gradient masking. We further analyze the parameters contributing to unstable models that lead to overestimation. Our findings indicate that smaller batch sizes, lower beta values (which control the weight of the robust loss term in TRADES), larger learning rates, and higher class complexity (e.g., CIFAR-100 versus CIFAR-10) are associated with an increased likelihood of robustness overestimation. By examining metrics such as the First-Order Stationary Condition (FOSC), inner-maximization, and gradient information, we identify the underlying cause of this phenomenon as gradient masking and provide insights into it. Furthermore, our experiments show that certain unstable training instances may return to a state without robust overestimation, inspiring our attempts at a solution. In addition to adjusting parameter settings to reduce instability or retraining when overestimation occurs, we recommend incorporating Gaussian noise in inputs when the FOSC score exceed the threshold. This method aims to mitigate robustness overestimation of TRADES and other similar methods at its source, ensuring more reliable representation of adversarial robustness during evaluation.