 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnealing Self-Distillation Rectification Improves Adversarial Training
May 20, 2023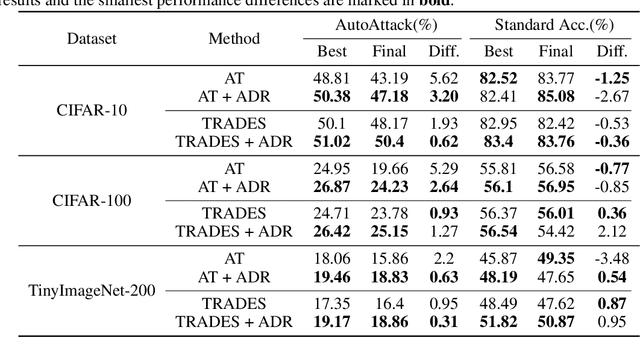

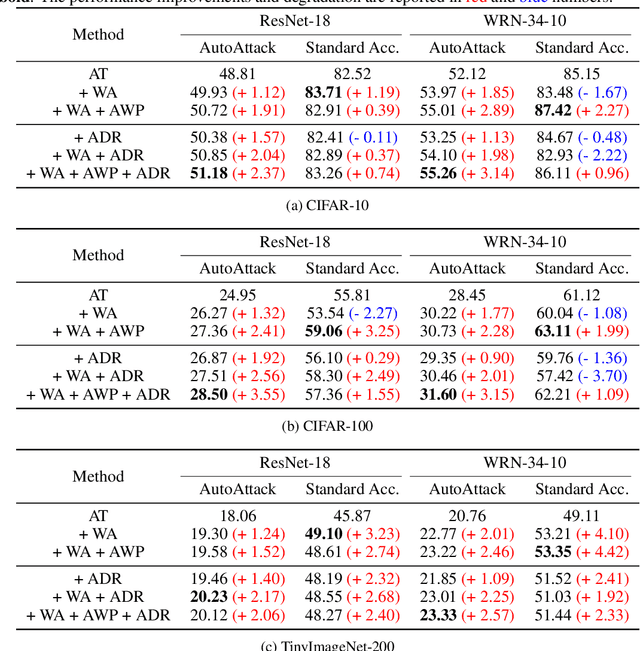
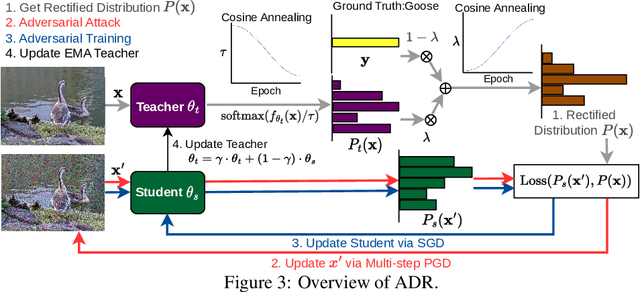
In standard adversarial training, models are optimized to fit one-hot labels within allowable adversarial perturbation budgets. However, the ignorance of underlying distribution shifts brought by perturbations causes the problem of robust overfitting. To address this issue and enhance adversarial robustness, we analyze the characteristics of robust models and identify that robust models tend to produce smoother and well-calibrated outputs. Based on the observation, we propose a simple yet effective method, Annealing Self-Distillation Rectification (ADR), which generates soft labels as a better guidance mechanism that accurately reflects the distribution shift under attack during adversarial training. By utilizing ADR, we can obtain rectified distributions that significantly improve model robustness without the need for pre-trained models or extensive extra computation. Moreover, our method facilitates seamless plug-and-play integration with other adversarial training techniques by replacing the hard labels in their objectives. We demonstrate the efficacy of ADR through extensive experiments and strong performances across datasets.
Enhancing Targeted Attack Transferability via Diversified Weight Pruning
Aug 18, 2022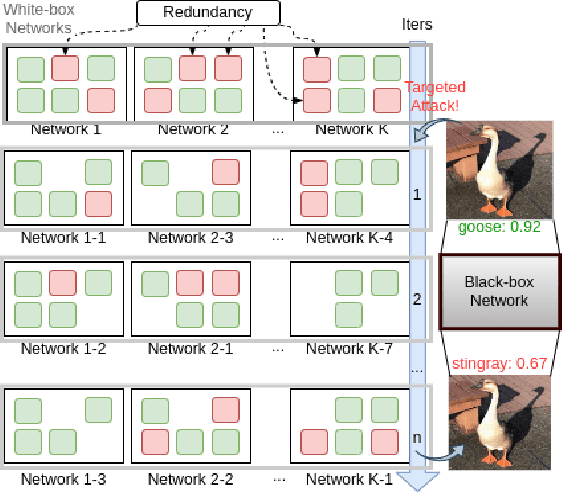



Malicious attackers can generate targeted adversarial examples by imposing human-imperceptible noise on images, forcing neural network models to produce specific incorrect outputs. With cross-model transferable adversarial examples, the vulnerability of neural networks remains even if the model information is kept secret from the attacker. Recent studies have shown the effectiveness of ensemble-based methods in generating transferable adversarial examples. However, existing methods fall short under the more challenging scenario of creating targeted attacks transferable among distinct models. In this work, we propose Diversified Weight Pruning (DWP) to further enhance the ensemble-based methods by leveraging the weight pruning method commonly used in model compression. Specifically, we obtain multiple diverse models by a random weight pruning method. These models preserve similar accuracies and can serve as additional models for ensemble-based methods, yielding stronger transferable targeted attacks. Experiments on ImageNet-Compatible Dataset under the more challenging scenarios are provided: transferring to distinct architectures and to adversarially trained models. The results show that our proposed DWP improves the targeted attack success rates with up to 4.1% and 8.0% on the combination of state-of-the-art methods, respectively