 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Skills from Action-Free Videos
Dec 23, 2025Learning from videos offers a promising path toward generalist robots by providing rich visual and temporal priors beyond what real robot datasets contain. While existing video generative models produce impressive visual predictions, they are difficult to translate into low-level actions. Conversely, latent-action models better align videos with actions, but they typically operate at the single-step level and lack high-level planning capabilities. We bridge this gap by introducing Skill Abstraction from Optical Flow (SOF), a framework that learns latent skills from large collections of action-free videos. Our key idea is to learn a latent skill space through an intermediate representation based on optical flow that captures motion information aligned with both video dynamics and robot actions. By learning skills in this flow-based latent space, SOF enables high-level planning over video-derived skills and allows for easier translation of these skills into actions. Experiments show that our approach consistently improves performance in both multitask and long-horizon settings, demonstrating the ability to acquire and compose skills directly from raw visual data.
MedFuse: Multiplicative Embedding Fusion For Irregular Clinical Time Series
Nov 12, 2025Clinical time series derived from electronic health records (EHRs) are inherently irregular, with asynchronous sampling, missing values, and heterogeneous feature dynamics. While numerical laboratory measurements are highly informative, existing embedding strategies usually combine feature identity and value embeddings through additive operations, which constrains their ability to capture value-dependent feature interactions. We propose MedFuse, a framework for irregular clinical time series centered on the MuFuse (Multiplicative Embedding Fusion) module. MuFuse fuses value and feature embeddings through multiplicative modulation, preserving feature-specific information while modeling higher-order dependencies across features. Experiments on three real-world datasets covering both intensive and chronic care show that MedFuse consistently outperforms state-of-the-art baselines on key predictive tasks. Analysis of the learned representations further demonstrates that multiplicative fusion enhances expressiveness and supports cross-dataset pretraining. These results establish MedFuse as a generalizable approach for modeling irregular clinical time series.
SAD-Flower: Flow Matching for Safe, Admissible, and Dynamically Consistent Planning
Nov 07, 2025Flow matching (FM) has shown promising results in data-driven planning. However, it inherently lacks formal guarantees for ensuring state and action constraints, whose satisfaction is a fundamental and crucial requirement for the safety and admissibility of planned trajectories on various systems. Moreover, existing FM planners do not ensure the dynamical consistency, which potentially renders trajectories inexecutable. We address these shortcomings by proposing SAD-Flower, a novel framework for generating Safe, Admissible, and Dynamically consistent trajectories. Our approach relies on an augmentation of the flow with a virtual control input. Thereby, principled guidance can be derived using techniques from nonlinear control theory, providing formal guarantees for state constraints, action constraints, and dynamic consistency. Crucially, SAD-Flower operates without retraining, enabling test-time satisfaction of unseen constraints. Through extensive experiments across several tasks, we demonstrate that SAD-Flower outperforms various generative-model-based baselines in ensuring constraint satisfaction.
Restoring Noisy Demonstration for Imitation Learning With Diffusion Models
Oct 16, 2025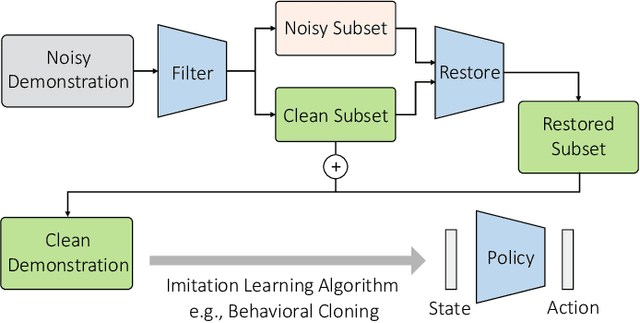
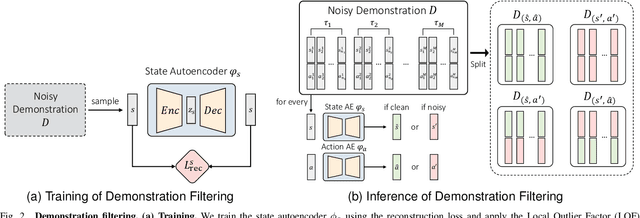
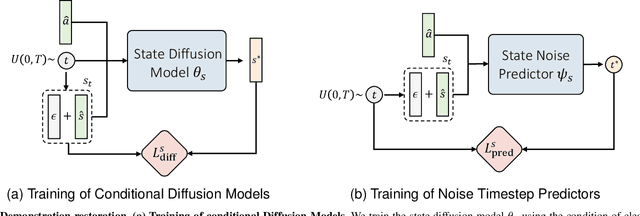
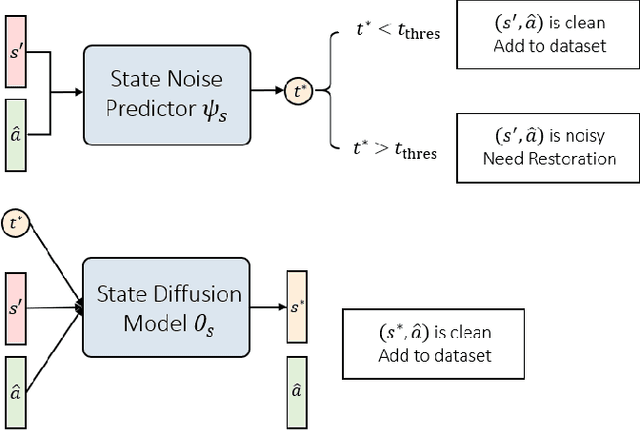
Imitation learning (IL) aims to learn a policy from expert demonstrations and has been applied to various applications. By learning from the expert policy, IL methods do not require environmental interactions or reward signals. However, most existing imitation learning algorithms assume perfect expert demonstrations, but expert demonstrations often contain imperfections caused by errors from human experts or sensor/control system inaccuracies. To address the above problems, this work proposes a filter-and-restore framework to best leverage expert demonstrations with inherent noise. Our proposed method first filters clean samples from the demonstrations and then learns conditional diffusion models to recover the noisy ones. We evaluate our proposed framework and existing methods in various domains, including robot arm manipulation, dexterous manipulation, and locomotion. The experiment results show that our proposed framework consistently outperforms existing methods across all the tasks. Ablation studies further validate the effectiveness of each component and demonstrate the framework's robustness to different noise types and levels. These results confirm the practical applicability of our framework to noisy offline demonstration data.
* Published in IEEE Transactions on Neural Networks and Learning Systems (TNNLS)
Action-Constrained Imitation Learning
Aug 20, 2025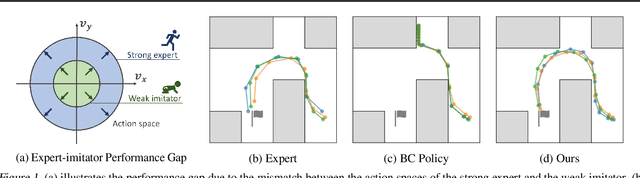
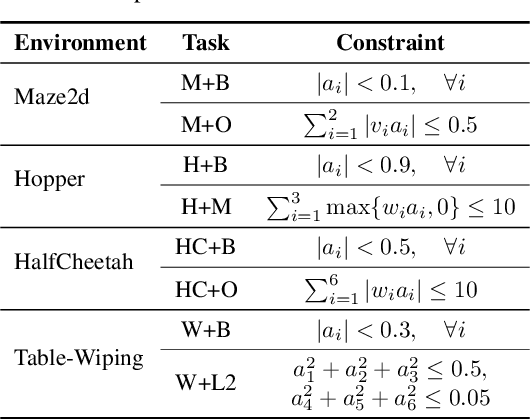
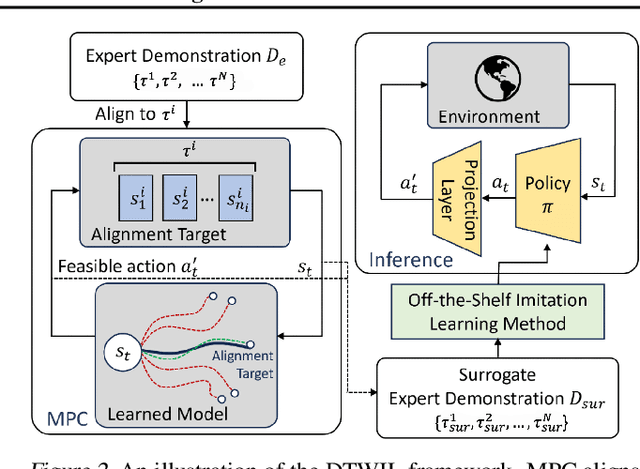
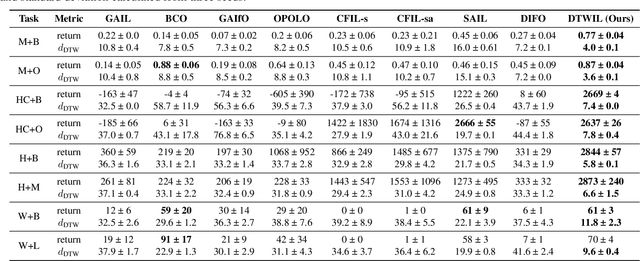
Policy learning under action constraints plays a central role in ensuring safe behaviors in various robot control and resource allocation applications. In this paper, we study a new problem setting termed Action-Constrained Imitation Learning (ACIL), where an action-constrained imitator aims to learn from a demonstrative expert with larger action space. The fundamental challenge of ACIL lies in the unavoidable mismatch of occupancy measure between the expert and the imitator caused by the action constraints. We tackle this mismatch through \textit{trajectory alignment} and propose DTWIL, which replaces the original expert demonstrations with a surrogate dataset that follows similar state trajectories while adhering to the action constraints. Specifically, we recast trajectory alignment as a planning problem and solve it via Model Predictive Control, which aligns the surrogate trajectories with the expert trajectories based on the Dynamic Time Warping (DTW) distance. Through extensive experiments, we demonstrate that learning from the dataset generated by DTWIL significantly enhances performance across multiple robot control tasks and outperforms various benchmark imitation learning algorithms in terms of sample efficiency. Our code is publicly available at https://github.com/NYCU-RL-Bandits-Lab/ACRL-Baselines.
Rethinking Creativity Evaluation: A Critical Analysis of Existing Creativity Evaluations
Aug 07, 2025We systematically examine, analyze, and compare representative creativity measures--creativity index, perplexity, syntactic templates, and LLM-as-a-Judge--across diverse creative domains, including creative writing, unconventional problem-solving, and research ideation. Our analyses reveal that these metrics exhibit limited consistency, capturing different dimensions of creativity. We highlight key limitations, including the creativity index's focus on lexical diversity, perplexity's sensitivity to model confidence, and syntactic templates' inability to capture conceptual creativity. Additionally, LLM-as-a-Judge shows instability and bias. Our findings underscore the need for more robust, generalizable evaluation frameworks that better align with human judgments of creativity.
Adaptive Helpfulness-Harmlessness Alignment with Preference Vectors
Apr 27, 2025Ensuring that large language models (LLMs) are both helpful and harmless is a critical challenge, as overly strict constraints can lead to excessive refusals, while permissive models risk generating harmful content. Existing approaches, such as reinforcement learning from human feedback (RLHF) and direct preference optimization (DPO), attempt to balance these trade-offs but suffer from performance conflicts, limited controllability, and poor extendability. To address these issues, we propose Preference Vector, a novel framework inspired by task arithmetic. Instead of optimizing multiple preferences within a single objective, we train separate models on individual preferences, extract behavior shifts as preference vectors, and dynamically merge them at test time. This modular approach enables fine-grained, user-controllable preference adjustments and facilitates seamless integration of new preferences without retraining. Experiments show that our proposed Preference Vector framework improves helpfulness without excessive conservatism, allows smooth control over preference trade-offs, and supports scalable multi-preference alignment.
Efficient Action-Constrained Reinforcement Learning via Acceptance-Rejection Method and Augmented MDPs
Mar 17, 2025Action-constrained reinforcement learning (ACRL) is a generic framework for learning control policies with zero action constraint violation, which is required by various safety-critical and resource-constrained applications. The existing ACRL methods can typically achieve favorable constraint satisfaction but at the cost of either high computational burden incurred by the quadratic programs (QP) or increased architectural complexity due to the use of sophisticated generative models. In this paper, we propose a generic and computationally efficient framework that can adapt a standard unconstrained RL method to ACRL through two modifications: (i) To enforce the action constraints, we leverage the classic acceptance-rejection method, where we treat the unconstrained policy as the proposal distribution and derive a modified policy with feasible actions. (ii) To improve the acceptance rate of the proposal distribution, we construct an augmented two-objective Markov decision process (MDP), which include additional self-loop state transitions and a penalty signal for the rejected actions. This augmented MDP incentives the learned policy to stay close to the feasible action sets. Through extensive experiments in both robot control and resource allocation domains, we demonstrate that the proposed framework enjoys faster training progress, better constraint satisfaction, and a lower action inference time simultaneously than the state-of-the-art ACRL methods. We have made the source code publicly available to encourage further research in this direction.
Human-Feedback Efficient Reinforcement Learning for Online Diffusion Model Finetuning
Oct 07, 2024Controllable generation through Stable Diffusion (SD) fine-tuning aims to improve fidelity, safety, and alignment with human guidance. Existing reinforcement learning from human feedback methods usually rely on predefined heuristic reward functions or pretrained reward models built on large-scale datasets, limiting their applicability to scenarios where collecting such data is costly or difficult. To effectively and efficiently utilize human feedback, we develop a framework, HERO, which leverages online human feedback collected on the fly during model learning. Specifically, HERO features two key mechanisms: (1) Feedback-Aligned Representation Learning, an online training method that captures human feedback and provides informative learning signals for fine-tuning, and (2) Feedback-Guided Image Generation, which involves generating images from SD's refined initialization samples, enabling faster convergence towards the evaluator's intent. We demonstrate that HERO is 4x more efficient in online feedback for body part anomaly correction compared to the best existing method. Additionally, experiments show that HERO can effectively handle tasks like reasoning, counting, personalization, and reducing NSFW content with only 0.5K online feedback.
Diffusion Imitation from Observation
Oct 07, 2024Learning from observation (LfO) aims to imitate experts by learning from state-only demonstrations without requiring action labels. Existing adversarial imitation learning approaches learn a generator agent policy to produce state transitions that are indistinguishable to a discriminator that learns to classify agent and expert state transitions. Despite its simplicity in formulation, these methods are often sensitive to hyperparameters and brittle to train. Motivated by the recent success of diffusion models in generative modeling, we propose to integrate a diffusion model into the adversarial imitation learning from observation framework. Specifically, we employ a diffusion model to capture expert and agent transitions by generating the next state, given the current state. Then, we reformulate the learning objective to train the diffusion model as a binary classifier and use it to provide "realness" rewards for policy learning. Our proposed framework, Diffusion Imitation from Observation (DIFO), demonstrates superior performance in various continuous control domains, including navigation, locomotion, manipulation, and games. Project page: https://nturobotlearninglab.github.io/DIFO