 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEXOP: A Device for Robotic Transfer of Dexterous Human Manipulation
Sep 04, 2025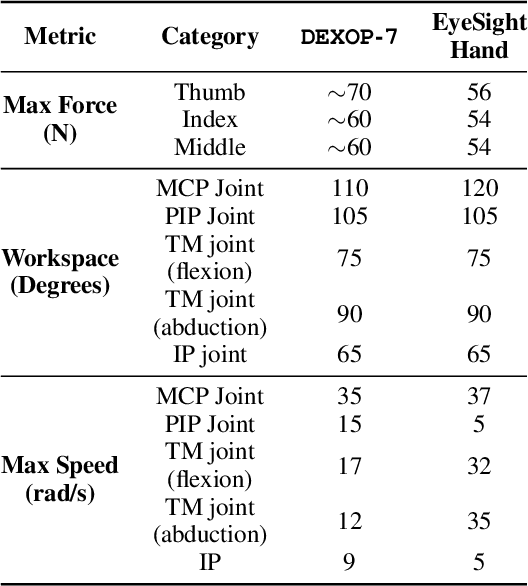
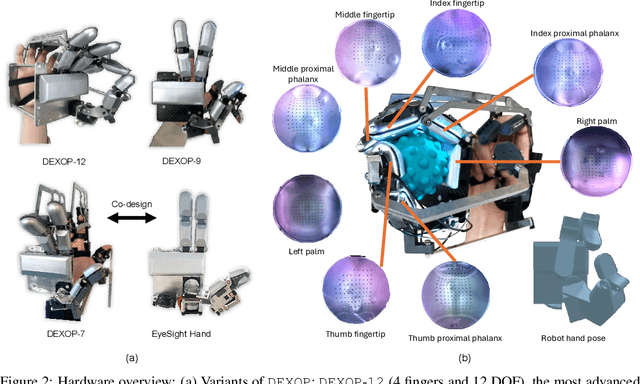

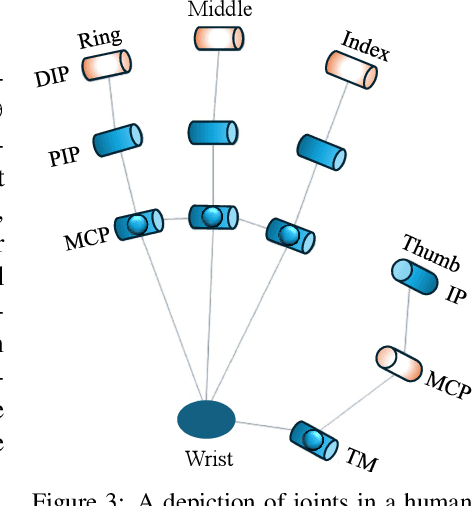
We introduce perioperation, a paradigm for robotic data collection that sensorizes and records human manipulation while maximizing the transferability of the data to real robots. We implement this paradigm in DEXOP, a passive hand exoskeleton designed to maximize human ability to collect rich sensory (vision + tactile) data for diverse dexterous manipulation tasks in natural environments. DEXOP mechanically connects human fingers to robot fingers, providing users with direct contact feedback (via proprioception) and mirrors the human hand pose to the passive robot hand to maximize the transfer of demonstrated skills to the robot. The force feedback and pose mirroring make task demonstrations more natural for humans compared to teleoperation, increasing both speed and accuracy. We evaluate DEXOP across a range of dexterous, contact-rich tasks, demonstrating its ability to collect high-quality demonstration data at scale. Policies learned with DEXOP data significantly improve task performance per unit time of data collection compared to teleoperation, making DEXOP a powerful tool for advancing robot dexterity. Our project page is at https://dex-op.github.io.
Keypoint Abstraction using Large Models for Object-Relative Imitation Learning
Oct 30, 2024



Generalization to novel object configurations and instances across diverse tasks and environments is a critical challenge in robotics. Keypoint-based representations have been proven effective as a succinct representation for capturing essential object features, and for establishing a reference frame in action prediction, enabling data-efficient learning of robot skills. However, their manual design nature and reliance on additional human labels limit their scalability. In this paper, we propose KALM, a framework that leverages large pre-trained vision-language models (LMs) to automatically generate task-relevant and cross-instance consistent keypoints. KALM distills robust and consistent keypoints across views and objects by generating proposals using LMs and verifies them against a small set of robot demonstration data. Based on the generated keypoints, we can train keypoint-conditioned policy models that predict actions in keypoint-centric frames, enabling robots to generalize effectively across varying object poses, camera views, and object instances with similar functional shapes. Our method demonstrates strong performance in the real world, adapting to different tasks and environments from only a handful of demonstrations while requiring no additional labels. Website: https://kalm-il.github.io/
Diffusion Imitation from Observation
Oct 07, 2024Learning from observation (LfO) aims to imitate experts by learning from state-only demonstrations without requiring action labels. Existing adversarial imitation learning approaches learn a generator agent policy to produce state transitions that are indistinguishable to a discriminator that learns to classify agent and expert state transitions. Despite its simplicity in formulation, these methods are often sensitive to hyperparameters and brittle to train. Motivated by the recent success of diffusion models in generative modeling, we propose to integrate a diffusion model into the adversarial imitation learning from observation framework. Specifically, we employ a diffusion model to capture expert and agent transitions by generating the next state, given the current state. Then, we reformulate the learning objective to train the diffusion model as a binary classifier and use it to provide "realness" rewards for policy learning. Our proposed framework, Diffusion Imitation from Observation (DIFO), demonstrates superior performance in various continuous control domains, including navigation, locomotion, manipulation, and games. Project page: https://nturobotlearninglab.github.io/DIFO