 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding Social Perception in Intuitive Physics
Mar 28, 2026People infer rich social information from others' actions. These inferences are often constrained by the physical world: what agents can do, what obstacles permit, and how the physical actions of agents causally change an environment and other agents' mental states and behavior. We propose that such rich social perception is more than visual pattern matching, but rather a reasoning process grounded in an integration of intuitive psychology with intuitive physics. To test this hypothesis, we introduced PHASE (PHysically grounded Abstract Social Events), a large dataset of procedurally generated animations, depicting physically simulated two-agent interactions on a 2D surface. Each animation follows the style of the Heider and Simmel movie, with systematic variation in environment geometry, object dynamics, agent capacities, goals, and relationships (friendly/adversarial/neutral). We then present a computational model, SIMPLE, a physics-grounded Bayesian inverse planning model that integrates planning, probabilistic planning, and physics simulation to infer agents' goals and relations from their trajectories. Our experimental results showed that SIMPLE achieved high accuracy and agreement with human judgments across diverse scenarios, while feedforward baseline models -- including strong vision-language models -- and physics-agnostic inverse planning failed to achieve human-level performance and did not align with human judgments. These results suggest that our model provides a computational account for how people understand physically grounded social scenes by inverting a generative model of physics and agents.
Sycophantic Chatbots Cause Delusional Spiraling, Even in Ideal Bayesians
Feb 22, 2026"AI psychosis" or "delusional spiraling" is an emerging phenomenon where AI chatbot users find themselves dangerously confident in outlandish beliefs after extended chatbot conversations. This phenomenon is typically attributed to AI chatbots' well-documented bias towards validating users' claims, a property often called "sycophancy." In this paper, we probe the causal link between AI sycophancy and AI-induced psychosis through modeling and simulation. We propose a simple Bayesian model of a user conversing with a chatbot, and formalize notions of sycophancy and delusional spiraling in that model. We then show that in this model, even an idealized Bayes-rational user is vulnerable to delusional spiraling, and that sycophancy plays a causal role. Furthermore, this effect persists in the face of two candidate mitigations: preventing chatbots from hallucinating false claims, and informing users of the possibility of model sycophancy. We conclude by discussing the implications of these results for model developers and policymakers concerned with mitigating the problem of delusional spiraling.
AI Gamestore: Scalable, Open-Ended Evaluation of Machine General Intelligence with Human Games
Feb 19, 2026Rigorously evaluating machine intelligence against the broad spectrum of human general intelligence has become increasingly important and challenging in this era of rapid technological advance. Conventional AI benchmarks typically assess only narrow capabilities in a limited range of human activity. Most are also static, quickly saturating as developers explicitly or implicitly optimize for them. We propose that a more promising way to evaluate human-like general intelligence in AI systems is through a particularly strong form of general game playing: studying how and how well they play and learn to play \textbf{all conceivable human games}, in comparison to human players with the same level of experience, time, or other resources. We define a "human game" to be a game designed by humans for humans, and argue for the evaluative suitability of this space of all such games people can imagine and enjoy -- the "Multiverse of Human Games". Taking a first step towards this vision, we introduce the AI GameStore, a scalable and open-ended platform that uses LLMs with humans-in-the-loop to synthesize new representative human games, by automatically sourcing and adapting standardized and containerized variants of game environments from popular human digital gaming platforms. As a proof of concept, we generated 100 such games based on the top charts of Apple App Store and Steam, and evaluated seven frontier vision-language models (VLMs) on short episodes of play. The best models achieved less than 10\% of the human average score on the majority of the games, and especially struggled with games that challenge world-model learning, memory and planning. We conclude with a set of next steps for building out the AI GameStore as a practical way to measure and drive progress toward human-like general intelligence in machines.
PhyScensis: Physics-Augmented LLM Agents for Complex Physical Scene Arrangement
Feb 16, 2026Automatically generating interactive 3D environments is crucial for scaling up robotic data collection in simulation. While prior work has primarily focused on 3D asset placement, it often overlooks the physical relationships between objects (e.g., contact, support, balance, and containment), which are essential for creating complex and realistic manipulation scenarios such as tabletop arrangements, shelf organization, or box packing. Compared to classical 3D layout generation, producing complex physical scenes introduces additional challenges: (a) higher object density and complexity (e.g., a small shelf may hold dozens of books), (b) richer supporting relationships and compact spatial layouts, and (c) the need to accurately model both spatial placement and physical properties. To address these challenges, we propose PhyScensis, an LLM agent-based framework powered by a physics engine, to produce physically plausible scene configurations with high complexity. Specifically, our framework consists of three main components: an LLM agent iteratively proposes assets with spatial and physical predicates; a solver, equipped with a physics engine, realizes these predicates into a 3D scene; and feedback from the solver informs the agent to refine and enrich the configuration. Moreover, our framework preserves strong controllability over fine-grained textual descriptions and numerical parameters (e.g., relative positions, scene stability), enabled through probabilistic programming for stability and a complementary heuristic that jointly regulates stability and spatial relations. Experimental results show that our method outperforms prior approaches in scene complexity, visual quality, and physical accuracy, offering a unified pipeline for generating complex physical scene layouts for robotic manipulation.
Learning Abstractions for Hierarchical Planning in Program-Synthesis Agents
Jan 31, 2026Humans learn abstractions and use them to plan efficiently to quickly generalize across tasks -- an ability that remains challenging for state-of-the-art large language model (LLM) agents and deep reinforcement learning (RL) systems. Inspired by the cognitive science of how people form abstractions and intuitive theories of their world knowledge, Theory-Based RL (TBRL) systems, such as TheoryCoder, exhibit strong generalization through effective use of abstractions. However, they heavily rely on human-provided abstractions and sidestep the abstraction-learning problem. We introduce TheoryCoder-2, a new TBRL agent that leverages LLMs' in-context learning ability to actively learn reusable abstractions rather than relying on hand-specified ones, by synthesizing abstractions from experience and integrating them into a hierarchical planning process. We conduct experiments on diverse environments, including BabyAI, Minihack and VGDL games like Sokoban. We find that TheoryCoder-2 is significantly more sample-efficient than baseline LLM agents augmented with classical planning domain construction, reasoning-based planning, and prior program-synthesis agents such as WorldCoder. TheoryCoder-2 is able to solve complex tasks that the baselines fail, while only requiring minimal human prompts, unlike prior TBRL systems.
A Matter of Interest: Understanding Interestingness of Math Problems in Humans and Language Models
Nov 11, 2025The evolution of mathematics has been guided in part by interestingness. From researchers choosing which problems to tackle next, to students deciding which ones to engage with, people's choices are often guided by judgments about how interesting or challenging problems are likely to be. As AI systems, such as LLMs, increasingly participate in mathematics with people -- whether for advanced research or education -- it becomes important to understand how well their judgments align with human ones. Our work examines this alignment through two empirical studies of human and LLM assessment of mathematical interestingness and difficulty, spanning a range of mathematical experience. We study two groups: participants from a crowdsourcing platform and International Math Olympiad competitors. We show that while many LLMs appear to broadly agree with human notions of interestingness, they mostly do not capture the distribution observed in human judgments. Moreover, most LLMs only somewhat align with why humans find certain math problems interesting, showing weak correlation with human-selected interestingness rationales. Together, our findings highlight both the promises and limitations of current LLMs in capturing human interestingness judgments for mathematical AI thought partnerships.
On the Same Wavelength? Evaluating Pragmatic Reasoning in Language Models across Broad Concepts
Sep 08, 2025

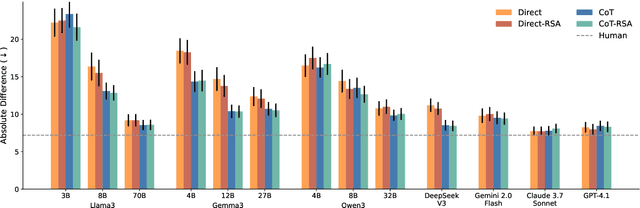
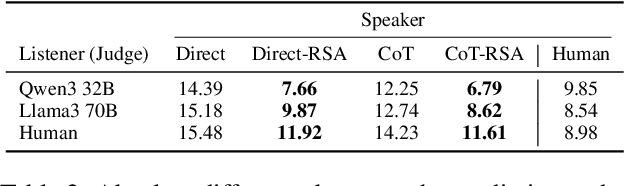
Language use is shaped by pragmatics -- i.e., reasoning about communicative goals and norms in context. As language models (LMs) are increasingly used as conversational agents, it becomes ever more important to understand their pragmatic reasoning abilities. We propose an evaluation framework derived from Wavelength, a popular communication game where a speaker and a listener communicate about a broad range of concepts in a granular manner. We study a range of LMs on both language comprehension and language production using direct and Chain-of-Thought (CoT) prompting, and further explore a Rational Speech Act (RSA) approach to incorporating Bayesian pragmatic reasoning into LM inference. We find that state-of-the-art LMs, but not smaller ones, achieve strong performance on language comprehension, obtaining similar-to-human accuracy and exhibiting high correlations with human judgments even without CoT prompting or RSA. On language production, CoT can outperform direct prompting, and using RSA provides significant improvements over both approaches. Our study helps identify the strengths and limitations in LMs' pragmatic reasoning abilities and demonstrates the potential for improving them with RSA, opening up future avenues for understanding conceptual representation, language understanding, and social reasoning in LMs and humans.
Minding the Politeness Gap in Cross-cultural Communication
Jun 18, 2025Misunderstandings in cross-cultural communication often arise from subtle differences in interpretation, but it is unclear whether these differences arise from the literal meanings assigned to words or from more general pragmatic factors such as norms around politeness and brevity. In this paper, we report three experiments examining how speakers of British and American English interpret intensifiers like "quite" and "very." To better understand these cross-cultural differences, we developed a computational cognitive model where listeners recursively reason about speakers who balance informativity, politeness, and utterance cost. Our model comparisons suggested that cross-cultural differences in intensifier interpretation stem from a combination of (1) different literal meanings, (2) different weights on utterance cost. These findings challenge accounts based purely on semantic variation or politeness norms, demonstrating that cross-cultural differences in interpretation emerge from an intricate interplay between the two.
What's in the Box? Reasoning about Unseen Objects from Multimodal Cues
Jun 17, 2025People regularly make inferences about objects in the world that they cannot see by flexibly integrating information from multiple sources: auditory and visual cues, language, and our prior beliefs and knowledge about the scene. How are we able to so flexibly integrate many sources of information to make sense of the world around us, even if we have no direct knowledge? In this work, we propose a neurosymbolic model that uses neural networks to parse open-ended multimodal inputs and then applies a Bayesian model to integrate different sources of information to evaluate different hypotheses. We evaluate our model with a novel object guessing game called ``What's in the Box?'' where humans and models watch a video clip of an experimenter shaking boxes and then try to guess the objects inside the boxes. Through a human experiment, we show that our model correlates strongly with human judgments, whereas unimodal ablated models and large multimodal neural model baselines show poor correlation.
Scaling up the think-aloud method
May 29, 2025The think-aloud method, where participants voice their thoughts as they solve a task, is a valuable source of rich data about human reasoning processes. Yet, it has declined in popularity in contemporary cognitive science, largely because labor-intensive transcription and annotation preclude large sample sizes. Here, we develop methods to automate the transcription and annotation of verbal reports of reasoning using natural language processing tools, allowing for large-scale analysis of think-aloud data. In our study, 640 participants thought aloud while playing the Game of 24, a mathematical reasoning task. We automatically transcribed the recordings and coded the transcripts as search graphs, finding moderate inter-rater reliability with humans. We analyze these graphs and characterize consistency and variation in human reasoning traces. Our work demonstrates the value of think-aloud data at scale and serves as a proof of concept for the automated analysis of verbal reports.