 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing the MADDPG Algorithm for Multi-Agent Learning via Action Inference and Importance Sampling
Jun 03, 2026We investigate multi-agent deep reinforcement learning and propose two enhancements to the Multi-Agent Deep Deterministic Policy Gradient (MADDPG) algorithm. First, we introduce a novel Action Inference mechanism that enables each agent to predict other agents' intended actions, thereby improving the accuracy and stability of its own policy. Second, we apply an importance sampling strategy, using geometric distribution, in the replay buffer to prioritize more recent and informative experiences, which helps mitigate the non-stationarity inherent in multi-agent environments. We evaluate both modifications on the discrete-action Predator-Prey task provided by the PettingZoo library, a flexible Python interface for general multi-agent reinforcement learning benchmarks. Our results indicate that Action Inference is effective in improving learning stability and inter-agent cooperation and that importance sampling using geometric distribution can lead to significant improvements in exploration efficiency over standard MADDPG. Code available at https://github.com/shaashwathsivakumar/MARL_Proj
Ads in AI Chatbots? An Analysis of How Large Language Models Navigate Conflicts of Interest
Apr 09, 2026Today's large language models (LLMs) are trained to align with user preferences through methods such as reinforcement learning. Yet models are beginning to be deployed not merely to satisfy users, but also to generate revenue for the companies that created them through advertisements. This creates the potential for LLMs to face conflicts of interest, where the most beneficial response to a user may not be aligned with the company's incentives. For instance, a sponsored product may be more expensive but otherwise equal to another; in this case, what does (and should) the LLM recommend to the user? In this paper, we provide a framework for categorizing the ways in which conflicting incentives might lead LLMs to change the way they interact with users, inspired by literature from linguistics and advertising regulation. We then present a suite of evaluations to examine how current models handle these tradeoffs. We find that a majority of LLMs forsake user welfare for company incentives in a multitude of conflict of interest situations, including recommending a sponsored product almost twice as expensive (Grok 4.1 Fast, 83%), surfacing sponsored options to disrupt the purchasing process (GPT 5.1, 94%), and concealing prices in unfavorable comparisons (Qwen 3 Next, 24%). Behaviors also vary strongly with levels of reasoning and users' inferred socio-economic status. Our results highlight some of the hidden risks to users that can emerge when companies begin to subtly incentivize advertisements in chatbots.
Cognitive Models and AI Algorithms Provide Templates for Designing Language Agents
Feb 26, 2026While contemporary large language models (LLMs) are increasingly capable in isolation, there are still many difficult problems that lie beyond the abilities of a single LLM. For such tasks, there is still uncertainty about how best to take many LLMs as parts and combine them into a greater whole. This position paper argues that potential blueprints for designing such modular language agents can be found in the existing literature on cognitive models and artificial intelligence (AI) algorithms. To make this point clear, we formalize the idea of an agent template that specifies roles for individual LLMs and how their functionalities should be composed. We then survey a variety of existing language agents in the literature and highlight their underlying templates derived directly from cognitive models or AI algorithms. By highlighting these designs, we aim to call attention to agent templates inspired by cognitive science and AI as a powerful tool for developing effective, interpretable language agents.
From Evaluation to Design: Using Potential Energy Surface Smoothness Metrics to Guide Machine Learning Interatomic Potential Architectures
Feb 04, 2026Machine Learning Interatomic Potentials (MLIPs) sometimes fail to reproduce the physical smoothness of the quantum potential energy surface (PES), leading to erroneous behavior in downstream simulations that standard energy and force regression evaluations can miss. Existing evaluations, such as microcanonical molecular dynamics (MD), are computationally expensive and primarily probe near-equilibrium states. To improve evaluation metrics for MLIPs, we introduce the Bond Smoothness Characterization Test (BSCT). This efficient benchmark probes the PES via controlled bond deformations and detects non-smoothness, including discontinuities, artificial minima, and spurious forces, both near and far from equilibrium. We show that BSCT correlates strongly with MD stability while requiring a fraction of the cost of MD. To demonstrate how BSCT can guide iterative model design, we utilize an unconstrained Transformer backbone as a testbed, illustrating how refinements such as a new differentiable $k$-nearest neighbors algorithm and temperature-controlled attention reduce artifacts identified by our metric. By optimizing model design systematically based on BSCT, the resulting MLIP simultaneously achieves a low conventional E/F regression error, stable MD simulations, and robust atomistic property predictions. Our results establish BSCT as both a validation metric and as an "in-the-loop" model design proxy that alerts MLIP developers to physical challenges that cannot be efficiently evaluated by current MLIP benchmarks.
Large Language Models Develop Novel Social Biases Through Adaptive Exploration
Nov 08, 2025



As large language models (LLMs) are adopted into frameworks that grant them the capacity to make real decisions, it is increasingly important to ensure that they are unbiased. In this paper, we argue that the predominant approach of simply removing existing biases from models is not enough. Using a paradigm from the psychology literature, we demonstrate that LLMs can spontaneously develop novel social biases about artificial demographic groups even when no inherent differences exist. These biases result in highly stratified task allocations, which are less fair than assignments by human participants and are exacerbated by newer and larger models. In social science, emergent biases like these have been shown to result from exploration-exploitation trade-offs, where the decision-maker explores too little, allowing early observations to strongly influence impressions about entire demographic groups. To alleviate this effect, we examine a series of interventions targeting model inputs, problem structure, and explicit steering. We find that explicitly incentivizing exploration most robustly reduces stratification, highlighting the need for better multifaceted objectives to mitigate bias. These results reveal that LLMs are not merely passive mirrors of human social biases, but can actively create new ones from experience, raising urgent questions about how these systems will shape societies over time.
LLM Social Simulations Are a Promising Research Method
Apr 03, 2025Accurate and verifiable large language model (LLM) simulations of human research subjects promise an accessible data source for understanding human behavior and training new AI systems. However, results to date have been limited, and few social scientists have adopted these methods. In this position paper, we argue that the promise of LLM social simulations can be achieved by addressing five tractable challenges. We ground our argument in a literature survey of empirical comparisons between LLMs and human research subjects, commentaries on the topic, and related work. We identify promising directions with prompting, fine-tuning, and complementary methods. We believe that LLM social simulations can already be used for exploratory research, such as pilot experiments for psychology, economics, sociology, and marketing. More widespread use may soon be possible with rapidly advancing LLM capabilities, and researchers should prioritize developing conceptual models and evaluations that can be iteratively deployed and refined at pace with ongoing AI advances.
Using the Tools of Cognitive Science to Understand Large Language Models at Different Levels of Analysis
Mar 17, 2025Modern artificial intelligence systems, such as large language models, are increasingly powerful but also increasingly hard to understand. Recognizing this problem as analogous to the historical difficulties in understanding the human mind, we argue that methods developed in cognitive science can be useful for understanding large language models. We propose a framework for applying these methods based on Marr's three levels of analysis. By revisiting established cognitive science techniques relevant to each level and illustrating their potential to yield insights into the behavior and internal organization of large language models, we aim to provide a toolkit for making sense of these new kinds of minds.
On Benchmarking Human-Like Intelligence in Machines
Feb 27, 2025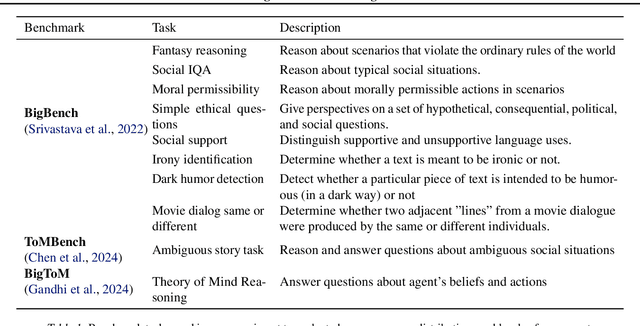
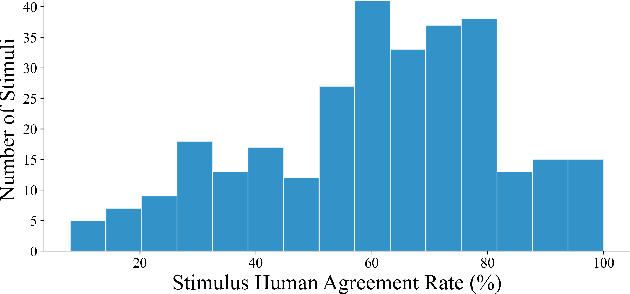
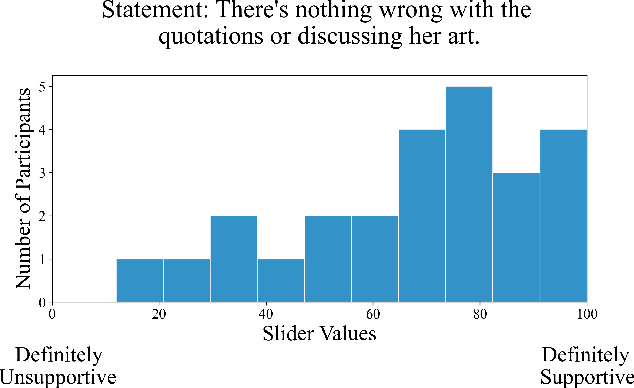
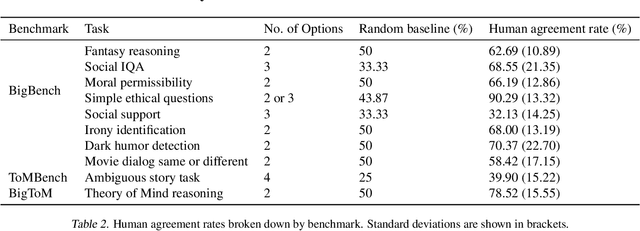
Recent benchmark studies have claimed that AI has approached or even surpassed human-level performances on various cognitive tasks. However, this position paper argues that current AI evaluation paradigms are insufficient for assessing human-like cognitive capabilities. We identify a set of key shortcomings: a lack of human-validated labels, inadequate representation of human response variability and uncertainty, and reliance on simplified and ecologically-invalid tasks. We support our claims by conducting a human evaluation study on ten existing AI benchmarks, suggesting significant biases and flaws in task and label designs. To address these limitations, we propose five concrete recommendations for developing future benchmarks that will enable more rigorous and meaningful evaluations of human-like cognitive capacities in AI with various implications for such AI applications.
RLHS: Mitigating Misalignment in RLHF with Hindsight Simulation
Jan 15, 2025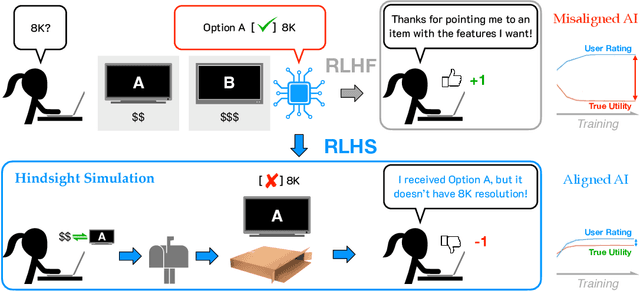



Generative AI systems like foundation models (FMs) must align well with human values to ensure their behavior is helpful and trustworthy. While Reinforcement Learning from Human Feedback (RLHF) has shown promise for optimizing model performance using human judgments, existing RLHF pipelines predominantly rely on immediate feedback, which can fail to accurately reflect the downstream impact of an interaction on users' utility. We demonstrate that feedback based on evaluators' foresight estimates of downstream consequences systematically induces Goodhart's Law dynamics, incentivizing misaligned behaviors like sycophancy and deception and ultimately degrading user outcomes. To alleviate this, we propose decoupling evaluation from prediction by refocusing RLHF on hindsight feedback. Our theoretical analysis reveals that conditioning evaluator feedback on downstream observations mitigates misalignment and improves expected human utility, even when these observations are simulated by the AI system itself. To leverage this insight in a practical alignment algorithm, we introduce Reinforcement Learning from Hindsight Simulation (RLHS), which first simulates plausible consequences and then elicits feedback to assess what behaviors were genuinely beneficial in hindsight. We apply RLHS to two widely-employed online and offline preference optimization methods -- Proximal Policy Optimization (PPO) and Direct Preference Optimization (DPO) -- and show empirically that misalignment is significantly reduced with both methods. Through an online human user study, we show that RLHS consistently outperforms RLHF in helping users achieve their goals and earns higher satisfaction ratings, despite being trained solely with simulated hindsight feedback. These results underscore the importance of focusing on long-term consequences, even simulated ones, to mitigate misalignment in RLHF.
Mind Your Step (by Step): Chain-of-Thought can Reduce Performance on Tasks where Thinking Makes Humans Worse
Oct 27, 2024Chain-of-thought (CoT) prompting has become a widely used strategy for working with large language and multimodal models. While CoT has been shown to improve performance across many tasks, determining the settings in which it is effective remains an ongoing effort. In particular, it is still an open question in what settings CoT systematically reduces model performance. In this paper, we seek to identify the characteristics of tasks where CoT reduces performance by drawing inspiration from cognitive psychology, looking at cases where (i) verbal thinking or deliberation hurts performance in humans, and (ii) the constraints governing human performance generalize to language models. Three such cases are implicit statistical learning, visual recognition, and classifying with patterns containing exceptions. In extensive experiments across all three settings, we find that a diverse collection of state-of-the-art models exhibit significant drop-offs in performance (e.g., up to 36.3% absolute accuracy for OpenAI o1-preview compared to GPT-4o) when using inference-time reasoning compared to zero-shot counterparts. We also identify three tasks that satisfy condition (i) but not (ii), and find that while verbal thinking reduces human performance in these tasks, CoT retains or increases model performance. Overall, our results show that while there is not an exact parallel between the cognitive processes of models and those of humans, considering cases where thinking has negative consequences for human performance can help us identify settings where it negatively impacts models. By connecting the literature on human deliberation with evaluations of CoT, we offer a new tool that can be used in understanding the impact of prompt choices and inference-time reasoning.