 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Bullshit: Characterizing the Emergent Disregard for Truth in Large Language Models
Jul 10, 2025Bullshit, as conceptualized by philosopher Harry Frankfurt, refers to statements made without regard to their truth value. While previous work has explored large language model (LLM) hallucination and sycophancy, we propose machine bullshit as an overarching conceptual framework that can allow researchers to characterize the broader phenomenon of emergent loss of truthfulness in LLMs and shed light on its underlying mechanisms. We introduce the Bullshit Index, a novel metric quantifying LLMs' indifference to truth, and propose a complementary taxonomy analyzing four qualitative forms of bullshit: empty rhetoric, paltering, weasel words, and unverified claims. We conduct empirical evaluations on the Marketplace dataset, the Political Neutrality dataset, and our new BullshitEval benchmark (2,400 scenarios spanning 100 AI assistants) explicitly designed to evaluate machine bullshit. Our results demonstrate that model fine-tuning with reinforcement learning from human feedback (RLHF) significantly exacerbates bullshit and inference-time chain-of-thought (CoT) prompting notably amplify specific bullshit forms, particularly empty rhetoric and paltering. We also observe prevalent machine bullshit in political contexts, with weasel words as the dominant strategy. Our findings highlight systematic challenges in AI alignment and provide new insights toward more truthful LLM behavior.
MASLab: A Unified and Comprehensive Codebase for LLM-based Multi-Agent Systems
May 22, 2025LLM-based multi-agent systems (MAS) have demonstrated significant potential in enhancing single LLMs to address complex and diverse tasks in practical applications. Despite considerable advancements, the field lacks a unified codebase that consolidates existing methods, resulting in redundant re-implementation efforts, unfair comparisons, and high entry barriers for researchers. To address these challenges, we introduce MASLab, a unified, comprehensive, and research-friendly codebase for LLM-based MAS. (1) MASLab integrates over 20 established methods across multiple domains, each rigorously validated by comparing step-by-step outputs with its official implementation. (2) MASLab provides a unified environment with various benchmarks for fair comparisons among methods, ensuring consistent inputs and standardized evaluation protocols. (3) MASLab implements methods within a shared streamlined structure, lowering the barriers for understanding and extension. Building on MASLab, we conduct extensive experiments covering 10+ benchmarks and 8 models, offering researchers a clear and comprehensive view of the current landscape of MAS methods. MASLab will continue to evolve, tracking the latest developments in the field, and invite contributions from the broader open-source community.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
RLHS: Mitigating Misalignment in RLHF with Hindsight Simulation
Jan 15, 2025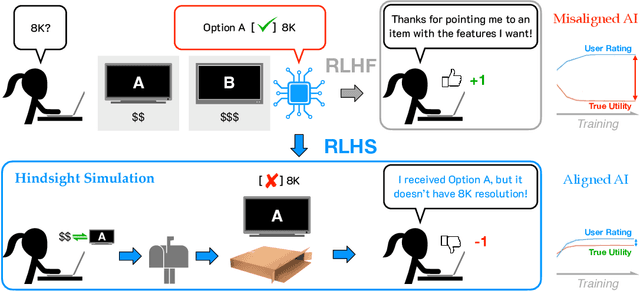



Generative AI systems like foundation models (FMs) must align well with human values to ensure their behavior is helpful and trustworthy. While Reinforcement Learning from Human Feedback (RLHF) has shown promise for optimizing model performance using human judgments, existing RLHF pipelines predominantly rely on immediate feedback, which can fail to accurately reflect the downstream impact of an interaction on users' utility. We demonstrate that feedback based on evaluators' foresight estimates of downstream consequences systematically induces Goodhart's Law dynamics, incentivizing misaligned behaviors like sycophancy and deception and ultimately degrading user outcomes. To alleviate this, we propose decoupling evaluation from prediction by refocusing RLHF on hindsight feedback. Our theoretical analysis reveals that conditioning evaluator feedback on downstream observations mitigates misalignment and improves expected human utility, even when these observations are simulated by the AI system itself. To leverage this insight in a practical alignment algorithm, we introduce Reinforcement Learning from Hindsight Simulation (RLHS), which first simulates plausible consequences and then elicits feedback to assess what behaviors were genuinely beneficial in hindsight. We apply RLHS to two widely-employed online and offline preference optimization methods -- Proximal Policy Optimization (PPO) and Direct Preference Optimization (DPO) -- and show empirically that misalignment is significantly reduced with both methods. Through an online human user study, we show that RLHS consistently outperforms RLHF in helping users achieve their goals and earns higher satisfaction ratings, despite being trained solely with simulated hindsight feedback. These results underscore the importance of focusing on long-term consequences, even simulated ones, to mitigate misalignment in RLHF.
CharXiv: Charting Gaps in Realistic Chart Understanding in Multimodal LLMs
Jun 26, 2024



Chart understanding plays a pivotal role when applying Multimodal Large Language Models (MLLMs) to real-world tasks such as analyzing scientific papers or financial reports. However, existing datasets often focus on oversimplified and homogeneous charts with template-based questions, leading to an over-optimistic measure of progress. We demonstrate that although open-source models can appear to outperform strong proprietary models on these benchmarks, a simple stress test with slightly different charts or questions can deteriorate performance by up to 34.5%. In this work, we propose CharXiv, a comprehensive evaluation suite involving 2,323 natural, challenging, and diverse charts from arXiv papers. CharXiv includes two types of questions: 1) descriptive questions about examining basic chart elements and 2) reasoning questions that require synthesizing information across complex visual elements in the chart. To ensure quality, all charts and questions are handpicked, curated, and verified by human experts. Our results reveal a substantial, previously underestimated gap between the reasoning skills of the strongest proprietary model (i.e., GPT-4o), which achieves 47.1% accuracy, and the strongest open-source model (i.e., InternVL Chat V1.5), which achieves 29.2%. All models lag far behind human performance of 80.5%, underscoring weaknesses in the chart understanding capabilities of existing MLLMs. We hope CharXiv facilitates future research on MLLM chart understanding by providing a more realistic and faithful measure of progress. Project page and leaderboard: https://charxiv.github.io/
Introspective Planning: Guiding Language-Enabled Agents to Refine Their Own Uncertainty
Feb 18, 2024



Large language models (LLMs) exhibit advanced reasoning skills, enabling robots to comprehend natural language instructions and strategically plan high-level actions through proper grounding. However, LLM hallucination may result in robots confidently executing plans that are misaligned with user goals or, in extreme cases, unsafe. Additionally, inherent ambiguity in natural language instructions can induce task uncertainty, particularly in situations where multiple valid options exist. To address this issue, LLMs must identify such uncertainty and proactively seek clarification. This paper explores the concept of introspective planning as a systematic method for guiding LLMs in forming uncertainty--aware plans for robotic task execution without the need for fine-tuning. We investigate uncertainty quantification in task-level robot planning and demonstrate that introspection significantly improves both success rates and safety compared to state-of-the-art LLM-based planning approaches. Furthermore, we assess the effectiveness of introspective planning in conjunction with conformal prediction, revealing that this combination yields tighter confidence bounds, thereby maintaining statistical success guarantees with fewer superfluous user clarification queries.
Who Plays First? Optimizing the Order of Play in Stackelberg Games with Many Robots
Feb 14, 2024We consider the multi-agent spatial navigation problem of computing the socially optimal order of play, i.e., the sequence in which the agents commit to their decisions, and its associated equilibrium in an N-player Stackelberg trajectory game. We model this problem as a mixed-integer optimization problem over the space of all possible Stackelberg games associated with the order of play's permutations. To solve the problem, we introduce Branch and Play (B&P), an efficient and exact algorithm that provably converges to a socially optimal order of play and its Stackelberg equilibrium. As a subroutine for B&P, we employ and extend sequential trajectory planning, i.e., a popular multi-agent control approach, to scalably compute valid local Stackelberg equilibria for any given order of play. We demonstrate the practical utility of B&P to coordinate air traffic control, swarm formation, and delivery vehicle fleets. We find that B&P consistently outperforms various baselines, and computes the socially optimal equilibrium.
Simple Baselines for Interactive Video Retrieval with Questions and Answers
Aug 21, 2023



To date, the majority of video retrieval systems have been optimized for a "single-shot" scenario in which the user submits a query in isolation, ignoring previous interactions with the system. Recently, there has been renewed interest in interactive systems to enhance retrieval, but existing approaches are complex and deliver limited gains in performance. In this work, we revisit this topic and propose several simple yet effective baselines for interactive video retrieval via question-answering. We employ a VideoQA model to simulate user interactions and show that this enables the productive study of the interactive retrieval task without access to ground truth dialogue data. Experiments on MSR-VTT, MSVD, and AVSD show that our framework using question-based interaction significantly improves the performance of text-based video retrieval systems.
Path Independent Equilibrium Models Can Better Exploit Test-Time Computation
Nov 18, 2022



Designing networks capable of attaining better performance with an increased inference budget is important to facilitate generalization to harder problem instances. Recent efforts have shown promising results in this direction by making use of depth-wise recurrent networks. We show that a broad class of architectures named equilibrium models display strong upwards generalization, and find that stronger performance on harder examples (which require more iterations of inference to get correct) strongly correlates with the path independence of the system -- its tendency to converge to the same steady-state behaviour regardless of initialization, given enough computation. Experimental interventions made to promote path independence result in improved generalization on harder problem instances, while those that penalize it degrade this ability. Path independence analyses are also useful on a per-example basis: for equilibrium models that have good in-distribution performance, path independence on out-of-distribution samples strongly correlates with accuracy. Our results help explain why equilibrium models are capable of strong upwards generalization and motivates future work that harnesses path independence as a general modelling principle to facilitate scalable test-time usage.